数据集成
FlowMQ 提供数据集成能力,支持将 Stream 中的数据实时分发到外部系统(数据库、数据湖、云服务等),也支持将外部系统的数据实时导入到 Stream 中。每一个数据集成任务称为一个 Data Pipeline。
本文介绍数据集成的公共概念与通用流程。各系统专属配置请参考:
什么是 Data Pipeline
Data Pipeline 是 FlowMQ 中数据集成的基本单元。每个 Pipeline 定义了一条数据流转链路,包含:
- 数据源(Source):数据的来源,可以是 FlowMQ Stream 或外部系统
- 数据目标(Sink):数据的去向,可以是外部系统或 FlowMQ Stream
- 数据转换(Transform):可选的中间处理步骤,用于对数据进行过滤、格式转换或字段映射
用户可以创建多个 Pipeline,各 Pipeline 独立运行、互不影响。
数据流向
Stream → 外部系统
将 Stream 中的数据实时同步到外部存储或服务,常见目标包括:
- 数据库:PostgreSQL、MySQL、MongoDB、ClickHouse、InfluxDB 等
- 数据湖 / 数据仓库:Snowflake、Databricks、BigQuery、S3 (Parquet/ORC) 等
- 搜索与分析:Elasticsearch、OpenSearch 等
- 应用与服务:Webhook、HTTP API、Slack、邮件通知等
外部系统 → Stream
将外部数据源的变更实时捕获并写入 Stream,常见来源包括:
- 数据库 CDC:捕获 PostgreSQL、MySQL 等数据库的行级变更
- API 轮询:定期拉取外部 REST API 的数据
- 文件监听:监控对象存储或文件系统中的新文件
典型用例
- IoT 数据入湖:设备遥测数据经 Stream 实时写入数据湖,供离线分析与 BI 报表使用
- 实时数据同步:将业务事件从 Stream 同步到 Elasticsearch,支撑全文检索与实时仪表盘
- 数据库变更分发:通过 CDC 捕获数据库变更写入 Stream,下游多个系统按需消费
- 跨系统数据管道:将外部系统的数据导入 Stream,经转换后再分发到其他目标系统
注意事项
- Pipeline 独立性:各 Pipeline 独立运行,单个 Pipeline 的故障或暂停不影响其他 Pipeline
- 数据顺序:Pipeline 保持 Stream 分区内的消息顺序,跨分区不保证全局有序
- 幂等写入:目标系统支持幂等时建议开启,避免重试导致数据重复
Bloblang 插值表达式
FlowMQ 数据管道配置中支持使用 Bloblang 插值表达式 动态引用消息内容、元数据,并做字符串变换。语法为 ${! <bloblang 表达式> },在运行时按每条消息求值,将结果填入对应配置项。
常用函数
| 函数 | 说明 | 示例 |
|---|---|---|
json("path") | 从消息体的 JSON 中提取字段,支持点号路径 | ${! json("data.value") } 取 data.value |
metadata("key") | 从消息元数据中提取,如 kafka_topic、partition 等 | ${! metadata("kafka_topic") } |
方法链
Bloblang 支持方法链,可对返回值进一步处理,例如:
re_replace_all(pattern, replacement):替换匹配字符。metadata("kafka_topic").re_replace_all("[^a-zA-Z0-9_]", "_")将 topic 中非法字符替换为下划线re_replace_all("/", "."):将路径分隔符/替换为.,常用于构建 IoTDB 等时序库的路径
字面量转义
若配置中需要输出字面量 ${!foo} 而不是插值结果,使用双花括号转义:$true。
通用配置流程
准备工作
在“数据流”模块中点击“创建数据流”按钮,数据流名称为
flowmq.mqtt.kafka,主题过滤器设置为flowmq/mqtt/kafka,点击“创建数据流”按钮。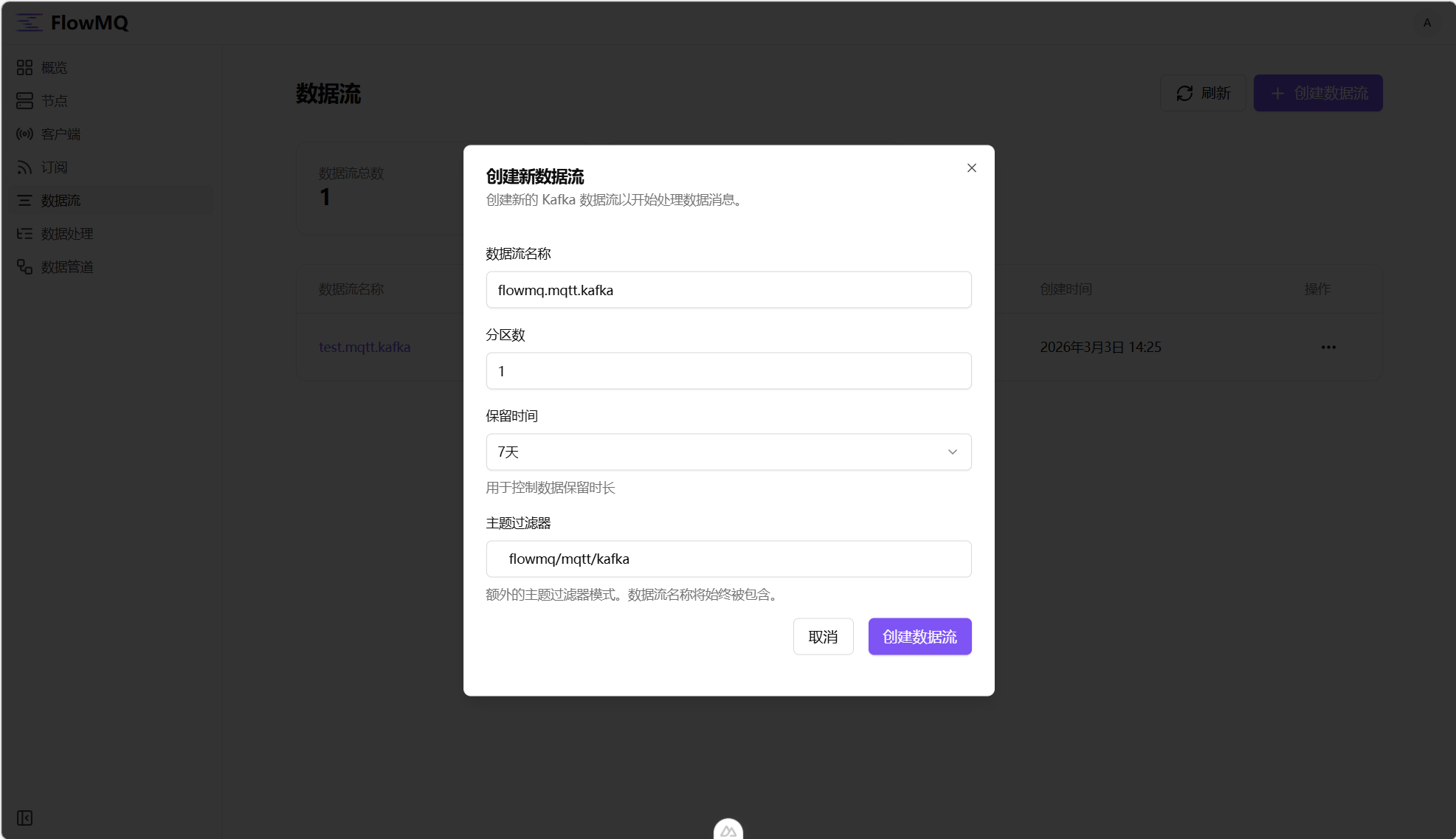
使用 MQTT 客户端软件,publish topic设置为
flowmq/mqtt/kafka,需要发送的数据如下:
json
{
"id": "e6eb1d31-5ab7-4ace-8bf7-e7c3e7a30a73",
"source": "1SDA526VD_POP_P1",
"time": "2023-05-30T15:23:23.123+08:00",
"type": "1",
"data": {
"value": "280.44",
"quality": "0",
"timestamp": 1710400220000
}
}创建 Pipeline
- 在“数据管道”模块中点击“创建管道”。
- 填写管道名称,选择方向(上行/下行)与任务数。
- 选择数据流作为 Source。
- 选择目标系统(Sink)并填写连接参数。
- 点击“测试”验证连接。
- 确认配置并创建 Pipeline。
- 在列表中启动 Pipeline 并观察运行状态。
系统专属配置
不同目标系统在连接参数、字段映射、路径命名规则上存在差异,请按目标系统查看专属文档: