数据处理
数据处理引擎用于对流式数据进行实时接入、转换与分发,实现规则驱动的计算流水线:从数据源接入、经 SQL 等逻辑处理、再输出到多种目标系统。
特点及优势
低延迟
提供低延迟的数据处理分析,能够更快速地将数据在多系统间传递,结合 AI/ML 算法,可以实现智能决策与控制。
完整的数据分析
- 数据抽取、转换和过滤
- 数据排序、分组、聚合、连接
- 丰富的内置函数,覆盖数学运算、字符串处理、聚合运算和哈希运算等
- 多类时间窗口,以及计数窗口
AI/ML 集成
可通过扩展接入自定义函数、AI/ML 算法等,实现在源(Source)、函数(Function)、动作(Sink)三个方面的扩展:
- 源(Source):接入更多数据源用于数据分析
- 目标(Sink):将分析结果发送到不同的扩展系统
- 函数(Function):增加自定义函数用于数据分析(如 AI/ML 函数调用)
核心概念
源(Source)
源(Source)定义了与外部系统的连接方式,以便将数据加载进来。在规则中,根据数据使用逻辑,数据源可作为**流(Stream)或表(Table)**使用。
- 流(Stream):数据源接入的主要运行方式,用户通过选择数据源类型及配置参数定义如何连接外部资源。有数据流入时,会触发规则中的计算。
- 表(Table):用于表示流的当前状态,可视为流的快照,用于批处理。组合使用流与表可实现更多数据处理功能。
- 扫描表:在内存中保存状态数据,按事件驱动逐个加载数据。
- 查询表:绑定外部数据(如 SQL 数据库)并在需要时查询引用。
源的解码:创建源时可指定 format 定义解码方式,支持 json、binary、protobuf、delimited 等格式,也可使用自定义编码(custom)。
源的定义与运行:创建流的逻辑定义后,并未立即启动物理数据输入;该定义可在多条规则的 SQL from 子句中复用。仅当使用该定义的规则启动后,数据流才会真正运行。
常见数据源类型包括:MQTT、Kafka 等。
规则(Rule)
规则代表一条数据处理流程,定义从数据源输入、经处理逻辑、到输出至动作(Sink)的完整链路。
- 规则生命周期:启动后持续运行,直至用户停止或异常退出。
- 规则隔离:各规则独立运行,单条规则错误不影响其他规则;共享硬件资源,可通过算子缓冲区限制处理速度。
- 规则流水线:多条规则可通过「内存 Source/Sink」或「MQTT Source/Sink」串联成处理管道。例如,第一条规则将结果写入内存 sink,后续规则从其内存源订阅并继续处理。
- SQL 语句:提供类 SQL 的查询语言,对数据流执行转换和计算,支持 DDL、DML 及查询,为 ANSI SQL 子集并带定制扩展。
- 规则调试:开启调试后,可实时查看数据源接入、经 SQL 处理后的输出结果,便于验证 SQL、函数及数据模板是否符合预期。
动作(Sink)
- 动作 Sink:向外部系统写入数据,一条规则可有多个动作,动作类型可重复。
- 数据模板:对规则输出进行二次处理后再送入各 Sink,为可选项;不配置时,处理结果直接输出。
- 动作类型:MQTT、REST、内存、Log、SQL、InfluxDB V1/V2、文件、Nop、Kafka、Image 等。
流式处理
流数据是不断增长的无界数据集,流处理对其做低延迟、近实时处理,适用于实时分析、实时计算、实时预测等场景。
- 有状态流处理:计算保持上下文状态,例如聚合(总和、计数、平均值)、检测事件变化、在事件序列中搜索模式等。
- 窗口:将无界数据分割为有界区间进行计算,支持:
- 时间窗口:按时间分割
- 计数窗口:按元素数量分割
时间窗口同时支持处理时间和事件时间。
- 多源连接:将多个数据源合并计算,支持 LEFT、RIGHT、FULL、CROSS 等连接类型。
- 时间概念:
- 事件时间:事件实际发生时间,通常由时间戳字段表示。
- 处理时间:系统观察到事件的时间。
- 事件时间与水印:支持事件时间的引擎通过水印衡量事件时间进度。水印携带时间戳 t,表示该流中不应再有 t' ≤ t 的事件;用于触发窗口输出等逻辑。
扩展
支持用户自定义扩展以接入 AI/ML 等能力,可通过插件系统编写扩展,或调用外部 REST 服务作为函数及算法扩展。
配置
支持资源配置、模式配置等,用于调整数据处理模块的运行参数。
操作示例
本示例演示如何对 MQTT 主题上的 JSON 数据进行转换后发送到另一主题。假设设备向 flowmq/data/raw 上报如下格式的数据,目标是将 data.value 转为数值并加 1 后写入 flowmq/data/adjusted。
示例数据
{
"id": "e6eb1d31-5ab7-4ace-8bf7-e7c3e7a30a73",
"source": "1SDA526VD_POP_P1",
"time": "2023-05-30T15:23:23.123+08:00",
"type": "1",
"data": {
"value": "280.44",
"quality": "0",
"timestamp": 1710400220000
}
}1. 创建开发任务
1.1 在数据处理模块中依次点击“开发任务” -> “创建开发任务”, 在弹出框中输入开发任务名称以及可选的描述,点击“创建”按钮。 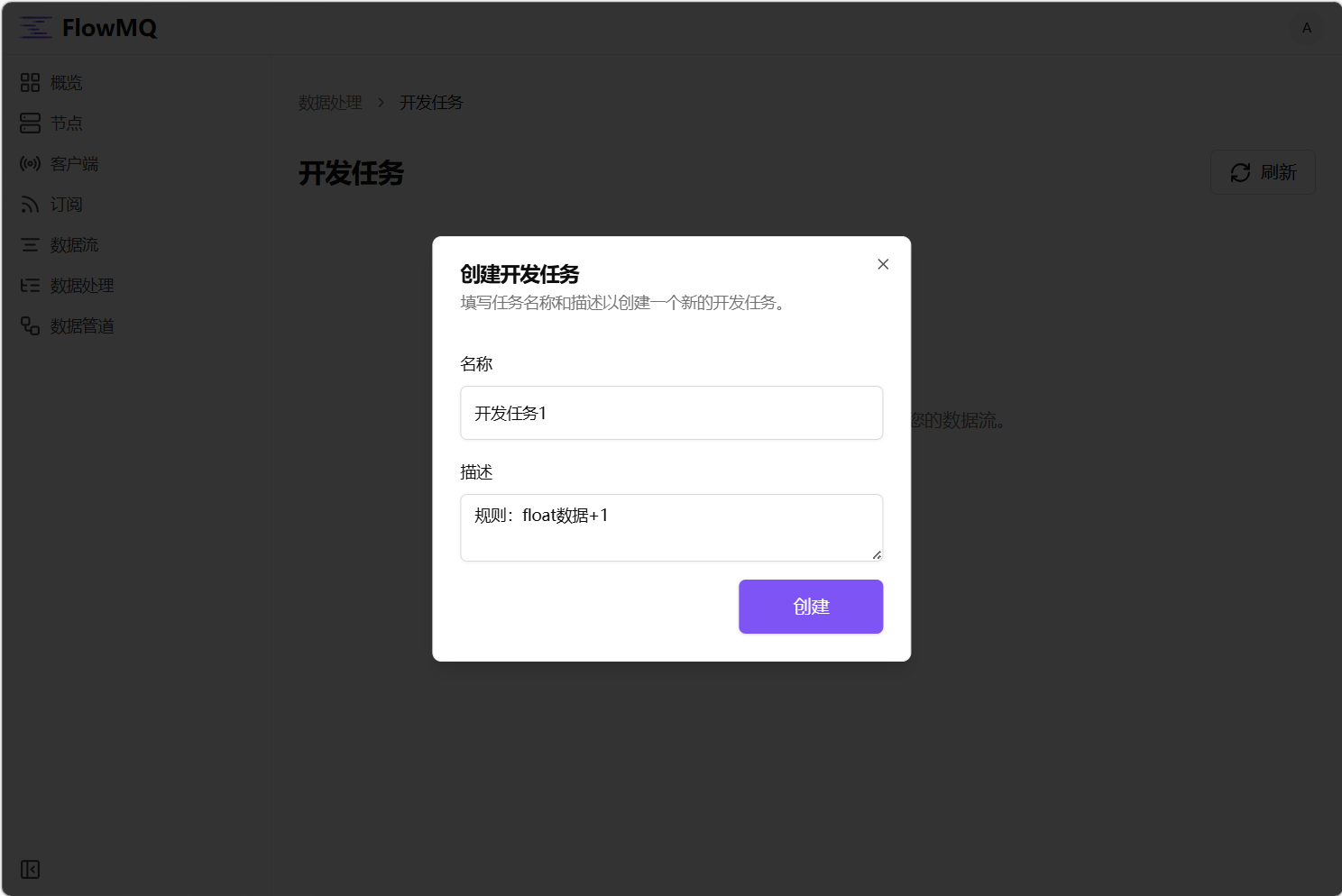
1.2 此时我们会在开发任务列表中看到刚刚创建的开发任务项。 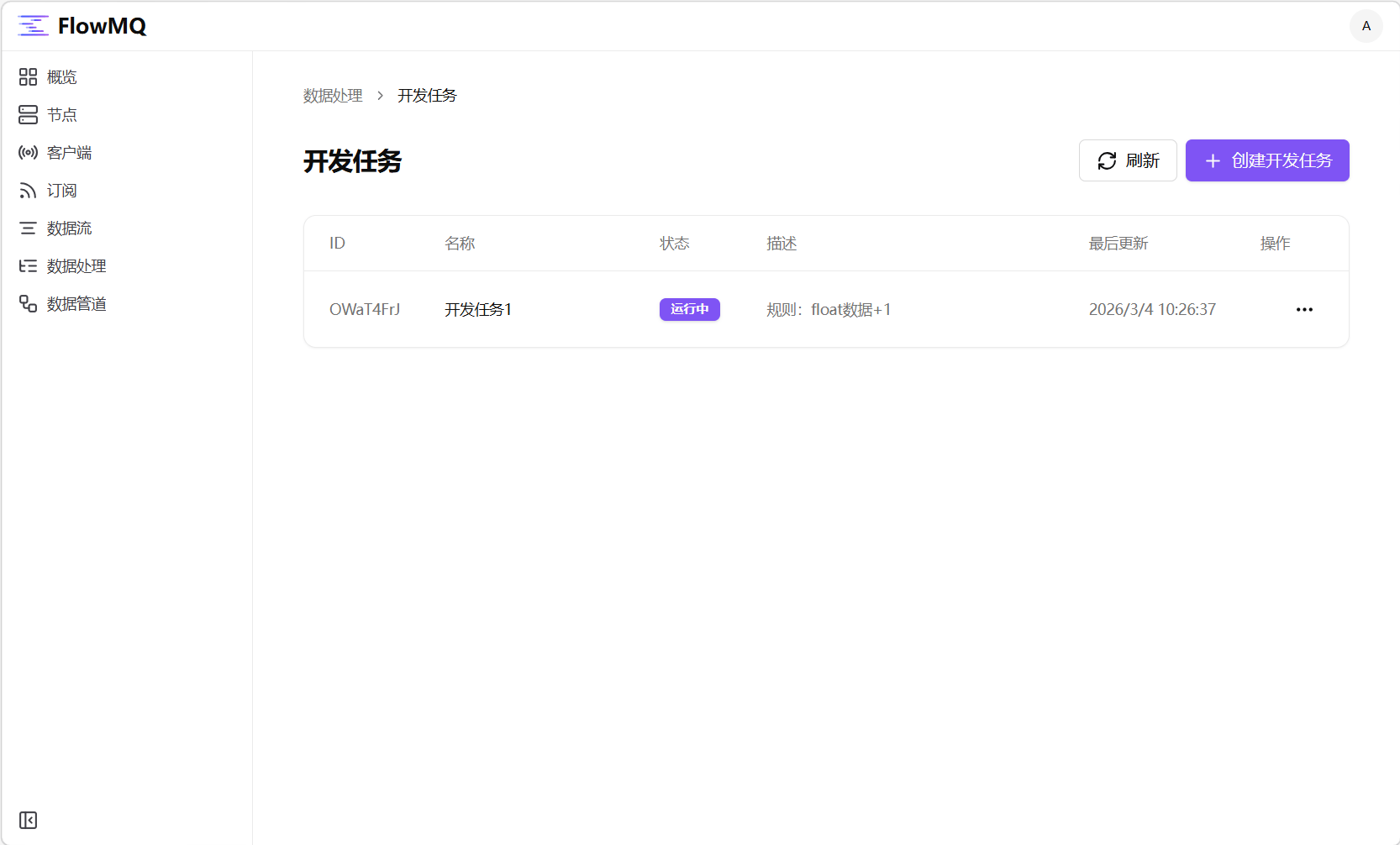
1.3 在开发任务项右侧操作菜单中选择“配置”进入配置页面, 选择配置页面的“连接器”Tab,然后点击“添加连接器”按钮,并在接下来的页面中添加连接器名称——mqttconnector1,选择“MQTT”卡片,点击“下一步”按钮,填写连接器配置表单,测试并提交。 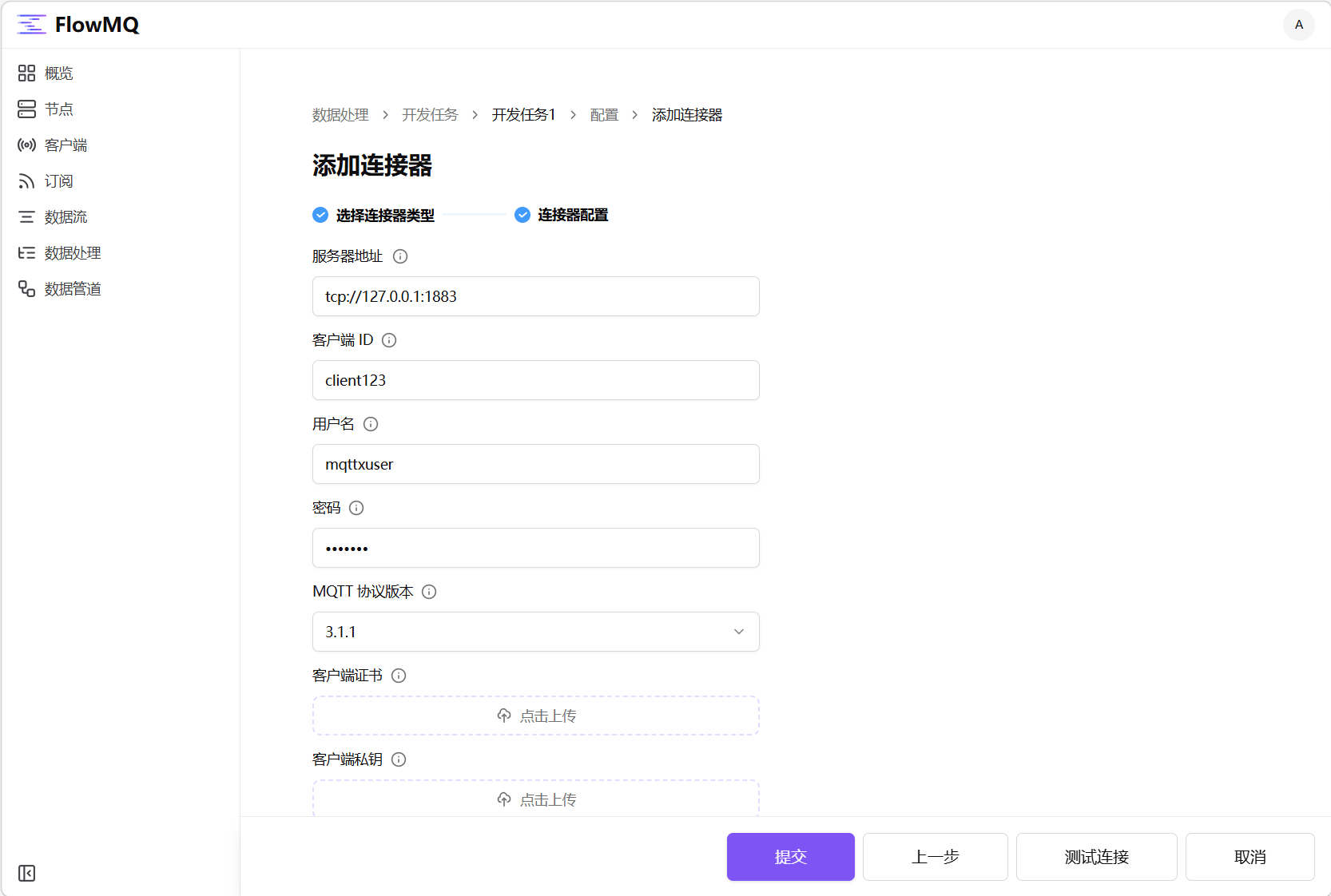
2. 创建数据源
2.1 回到开发任务列表,在操作菜单中选择“源管理”,并且点击“创建流”按钮,选择“MQTT”卡片后点击“下一步”按钮进入流配置表单页面,填写流名称为“mqttstream1”,数据源填写为“flowmq/data/raw”,
2.2 点击“添加配置组”按钮,在弹出的表单中填写配置组名称为“mqttconf1”,连接器下拉列表中选择之前创建的“mqttconnector1”,然后点击“提交”按钮后回到创建流表单中 
2.3 点击“提交”按钮,生成数据源。
3. 新建规则
3.1 回到开发任务列表,在操作菜单中选择“规则”,点击“创建规则”按钮,编写 SQL 对 data.value 做类型转换与 +1 运算并输出:
SELECT
id,
source,
time,
type,
cast(data.value,"float") + 1 AS adjusted_value,
data.quality,
data.timestamp
FROM mqttstream13.2 点击右侧“添加动作”按钮,选择“MQTT”卡片并点击“下一步”按钮进入动作配置表单,选择连接器“mqttconnector1”,主题填写为flowmq/data/adjusted,点击“提交”按钮保存配置。 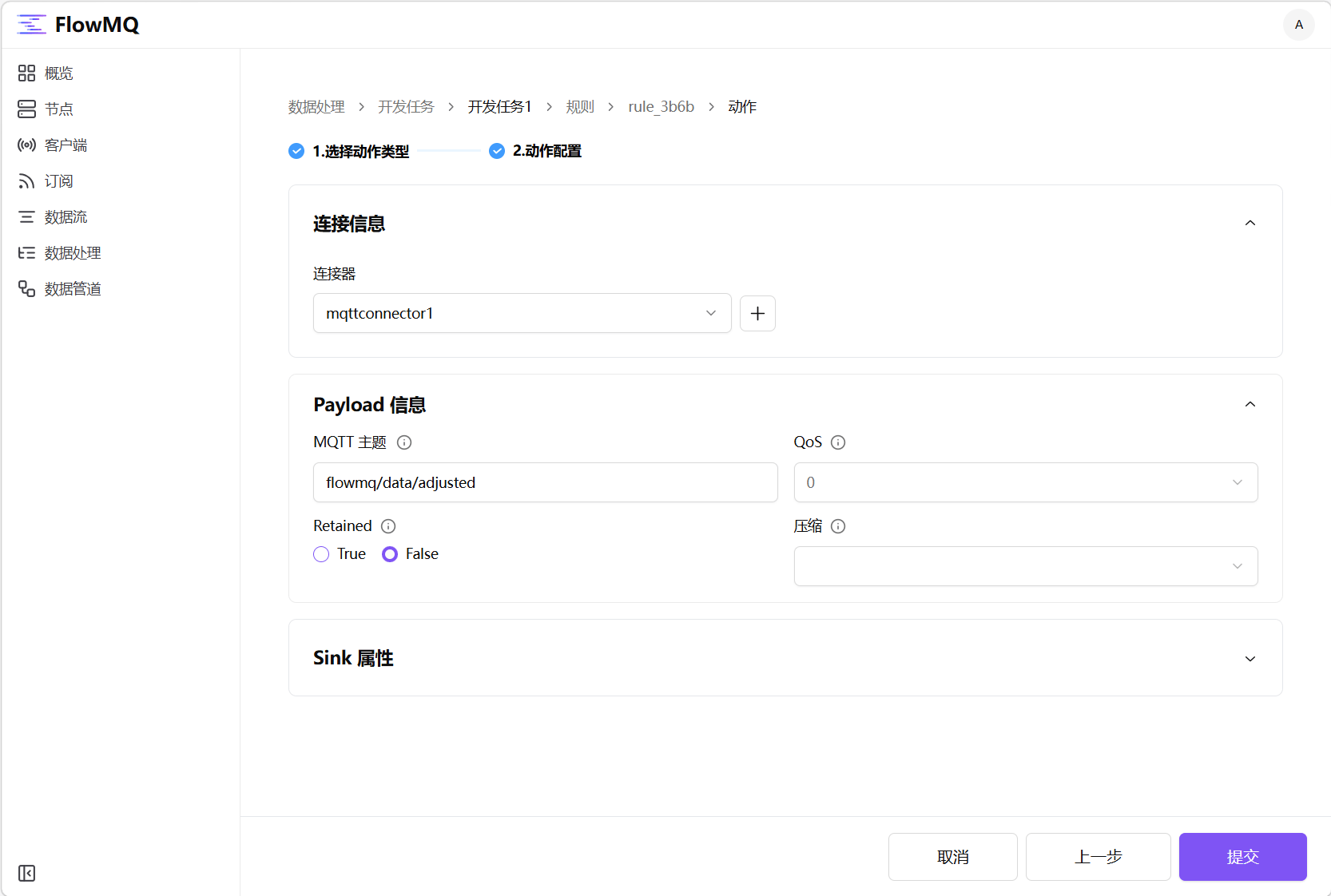
3.3 点击“保存规则”按钮保存规则。 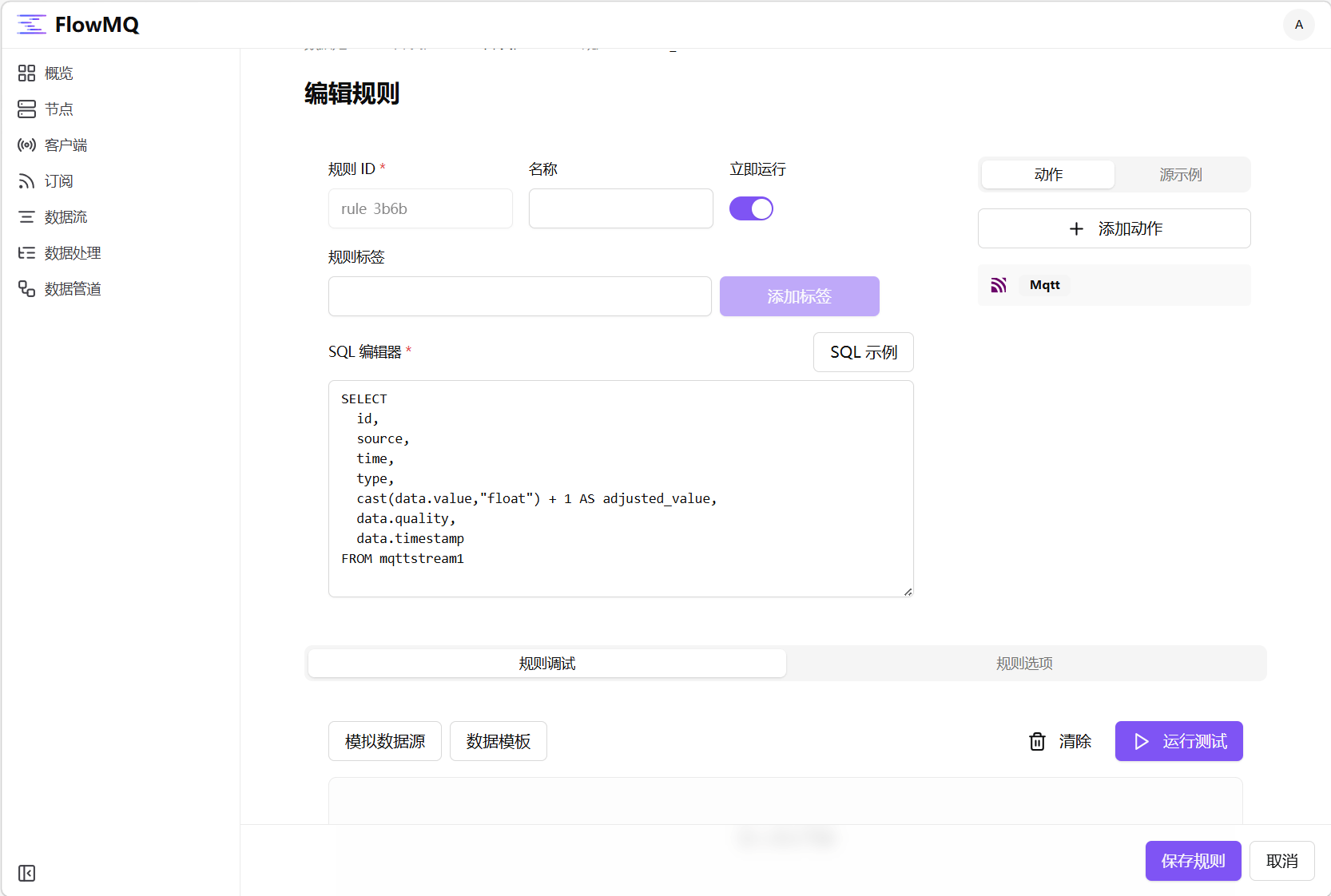
4. 部署任务
4.1 回到开发任务列表,在操作菜单中选择“停止”,然后继续在该菜单中选择“部署”选项,在弹出对话框中填写部署名称和运行的实例数量,点击“部署”按钮,完成规则的部署。 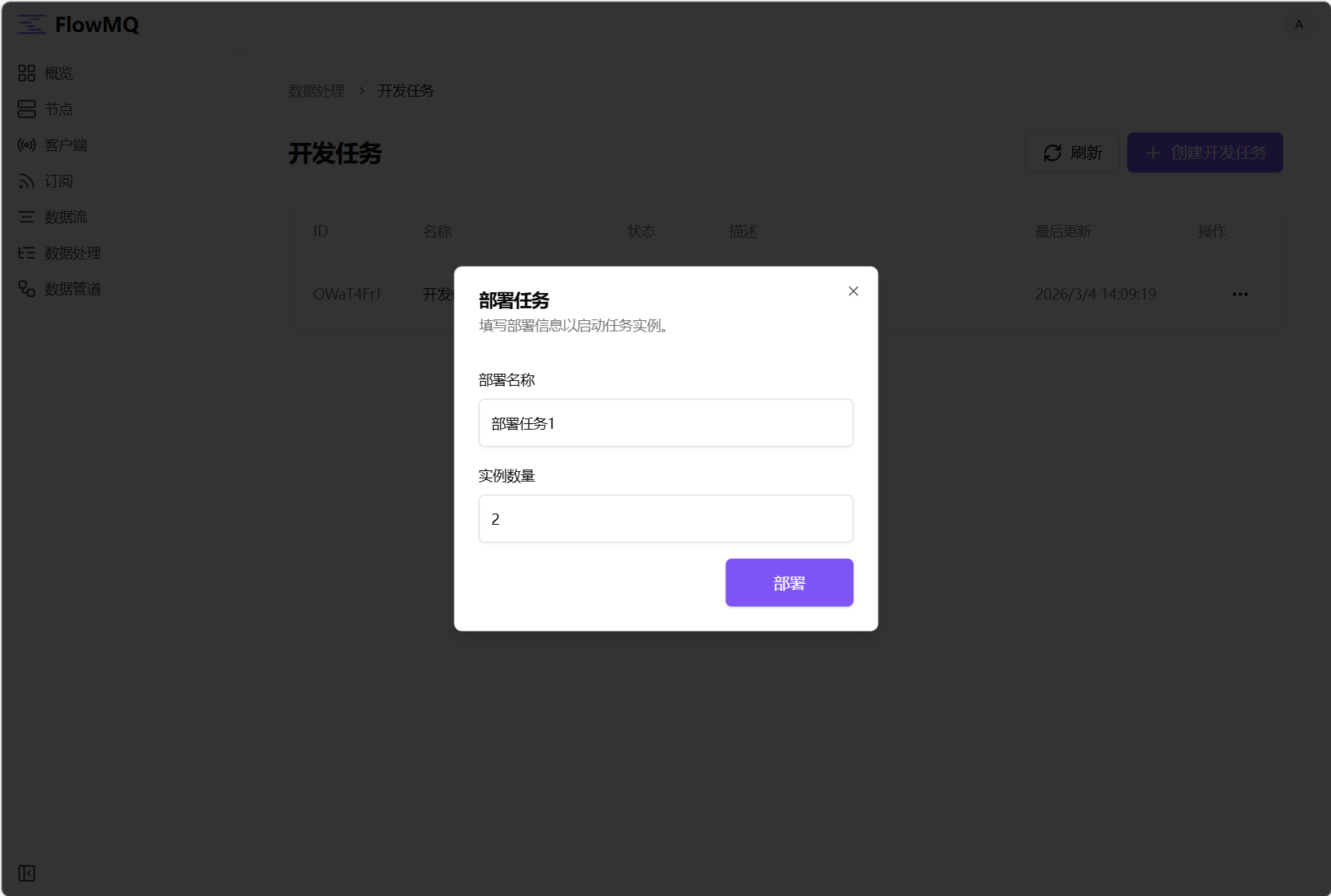
5. 启动并验证
5.1 进入“数据处理\部署管理”页面,在部署管理列表的操作菜单中选择“启动”。
5.2 启动部署后,向 flowmq/data/raw 发布上述示例数据,订阅 flowmq/data/adjusted 即可收到处理后的结果:
[{
"id": "e6eb1d31-5ab7-4ace-8bf7-e7c3e7a30a73",
"source": "1SDA526VD_POP_P1",
"time": "2023-05-30T15:23:23.123+08:00",
"type": "1",
"adjusted_value": 281.44,
"quality": "0",
"timestamp": 1710400220000
}]5.3 在部署管理列表的操作菜单中选择“状态”可查看部署实例的指标信息。