Snowflake への MQTT データ取り込み
Snowflake は、クラウドベースのデータプラットフォームであり、高いスケーラビリティと柔軟性を備えたデータウェアハウジング、分析、および安全なデータ共有のソリューションを提供します。構造化データおよび半構造化データの処理に優れ、大量のデータを高速なクエリ性能で保存し、さまざまなツールやサービスとシームレスに統合できるよう設計されています。
本ページでは、EMQX と Snowflake 間のデータ統合について詳しく紹介し、ルールおよび Sink の作成方法について実践的なガイドを提供します。
動作概要
EMQX における Snowflake データ統合はすぐに使える機能であり、複雑なビジネス開発にも簡単に設定可能です。典型的な IoT アプリケーションでは、EMQX がデバイス接続とメッセージ送受信を担う IoT プラットフォームとして機能し、Snowflake はメッセージデータの取り込み、保存、分析を担当するデータストレージおよび処理プラットフォームとして利用されます。
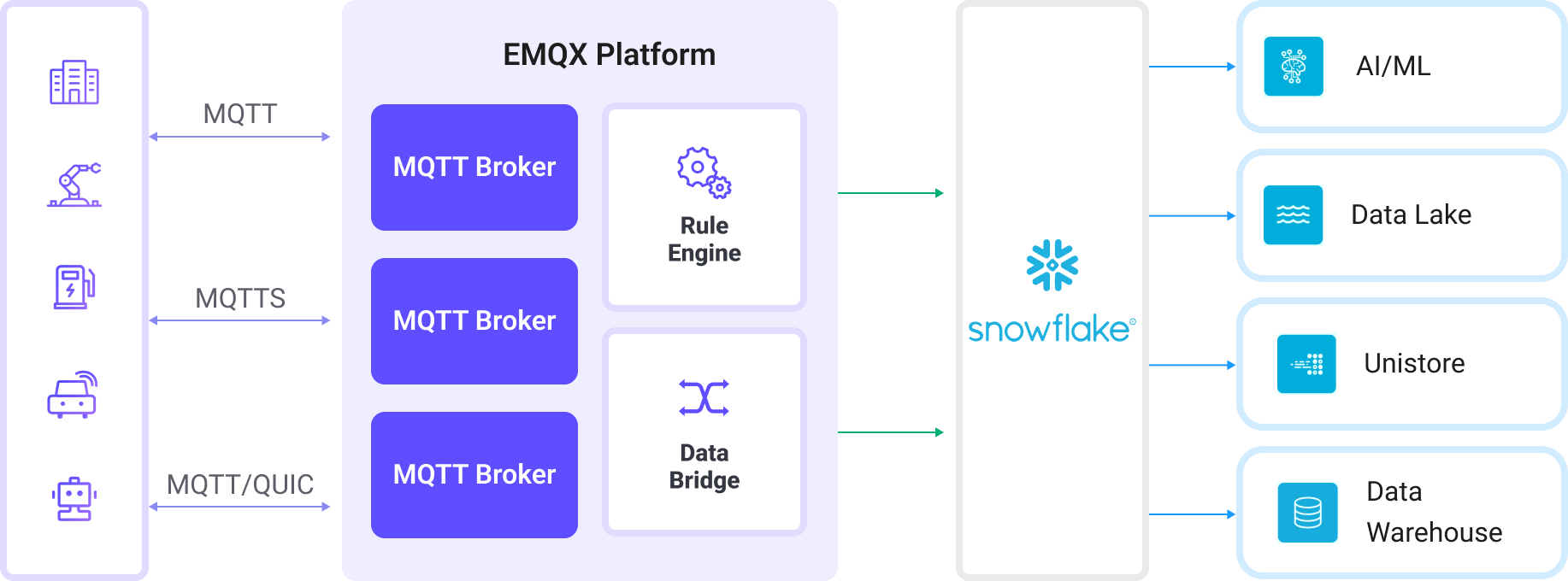
EMQX はルールエンジンと Sink を利用してデバイスイベントやデータを Snowflake に転送します。エンドユーザーやアプリケーションは Snowflake のテーブル内のデータにアクセスできます。具体的なワークフローは以下の通りです:
- デバイスの EMQX への接続:IoT デバイスは MQTT プロトコルで正常に接続するとオンラインイベントをトリガーします。イベントにはデバイスID、送信元IPアドレスなどの情報が含まれます。
- デバイスメッセージのパブリッシュと受信:デバイスは特定のトピックを通じてテレメトリや状態データをパブリッシュします。EMQX はメッセージを受信し、ルールエンジン内で比較処理を行います。
- ルールエンジンによるメッセージ処理:組み込みのルールエンジンはトピックマッチングに基づき特定のソースからのメッセージやイベントを処理します。対応するルールをマッチングし、データ形式変換、特定情報のフィルタリング、コンテキスト情報の付加などの処理を行います。
- Snowflake への書き込み:ルールはメッセージを Snowflake Stage に書き込み、そこから Snowflake テーブルにロードするアクションをトリガーします。
イベントやメッセージデータが Snowflake に書き込まれた後は、以下のようなビジネスや技術的な目的で利用可能です:
- データアーカイブ:IoT データを Snowflake に安全に長期保存し、コンプライアンスや過去データの利用を保証します。
- データ分析:Snowflake のデータウェアハウジングおよび分析機能を活用し、リアルタイムまたはバッチ分析を行い、予知保全、運用インサイト、デバイス性能評価を可能にします。
特長と利点
EMQX の Snowflake データ統合を利用することで、以下の特長と利点が得られます:
- メッセージ変換:メッセージは EMQX のルール内で高度な処理や変換を経てから Snowflake に書き込まれるため、後続の保存や利用が容易になります。
- 柔軟なデータ操作:Snowflake Sink は、書き込むフィールドを選択可能であり、ビジネスニーズに応じた効率的かつ動的なストレージ構成が可能です。
- 統合されたビジネスプロセス:Snowflake Sink によりデバイスデータを Snowflake の豊富なエコシステムアプリケーションと組み合わせ、データ分析やアーカイブなど多様なビジネスシナリオを実現します。
- 低コストの長期保存:Snowflake のスケーラブルなストレージ基盤は、従来のデータベースに比べて低コストで長期データ保持に最適なソリューションです。大量の IoT データ保存に適しています。
これらの特長により、効率的で信頼性が高くスケーラブルな IoT アプリケーションを構築し、ビジネスの意思決定や最適化に役立てることができます。
はじめる前に
このセクションでは、EMQX で Snowflake Sink を作成する前に必要な準備について説明します。
前提条件
Snowflake ODBC ドライバーの初期化
EMQX が Snowflake と通信し効率的にデータ転送を行うために、Snowflake Open Database Connectivity (ODBC) ドライバーのインストールと設定が必要です。これは通信の橋渡し役となり、データの適切なフォーマット、認証、転送を保証します。
詳細は公式の ODBC Driver ページおよび ライセンス契約 を参照してください。
Linux
以下のスクリプトを実行して Snowflake ODBC ドライバーをインストールし、odbc.ini ファイルを設定します:
scripts/install-snowflake-driver.sh注意
このスクリプトはテスト用であり、本番環境での ODBC ドライバー設定方法の推奨ではありません。公式の Linux 向けインストール手順 を参照してください。
macOS
macOS で Snowflake ODBC ドライバーをインストールおよび設定する手順は以下の通りです:
unixODBC をインストール(例):
brew install unixodbc詳細なインストールおよび設定手順は macOS 向け ODBC ドライバーのインストールと設定 を参照してください。
インストール後、以下の設定ファイルを更新します:
Snowflake ODBC ドライバーの権限と設定を更新:
bashchown $(id -u):$(id -g) /opt/snowflake/snowflakeodbc/lib/universal/simba.snowflake.ini echo 'ODBCInstLib=libiodbcinst.dylib' >> /opt/snowflake/snowflakeodbc/lib/universal/simba.snowflake.ini~/.odbc.iniファイルを作成または更新して ODBC 接続を設定:cat << EOF > ~/.odbc.ini [ODBC] Trace=no TraceFile= [ODBC Drivers] Snowflake = Installed [ODBC Data Sources] snowflake = Snowflake [Snowflake] Driver = /opt/snowflake/snowflakeodbc/lib/universal/libSnowflake.dylib EOF
ユーザーアカウントとデータベースの作成
Snowflake ODBC ドライバーをインストールしたら、データ取り込み用のユーザーアカウント、データベース、および関連リソースを設定します。これらの認証情報は後で EMQX のコネクターおよび Sink 設定時に使用します。
| フィールド名 | 値 |
|---|---|
| Data Source Name (DSN) | snowflake |
| ユーザー名 | snowpipeuser |
| パスワード | Snowpipeuser99 |
| データベース名 | testdatabase |
| スキーマ | public |
| ステージ | emqx |
| パイプ | emqx |
| パイプユーザー | snowpipeuser |
| プライベートキー | file://<path to snowflake_rsa_key.private.pem> |
RSA キーペアの生成
Snowflake への安全な接続のため、以下のコマンドで認証用の RSA キーペアを生成します:
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out snowflake_rsa_key.private.pem -nocrypt
openssl rsa -in snowflake_rsa_key.private.pem -pubout -out snowflake_rsa_key.public.pem詳細は キーペア認証とキーペアローテーション を参照してください。
SQL を使った Snowflake リソースのセットアップ
ODBC ドライバーのセットアップと RSA キーペア生成後、Snowflake のリソースを設定します。SQL コマンドを使ってデータベース、テーブル、ステージ、パイプを作成します。
Snowflake コンソールの SQL ワークシートを開き、以下の SQL を実行してデータベース、テーブル、ステージ、パイプを作成します:
sqlUSE ROLE accountadmin; CREATE DATABASE IF NOT EXISTS testdatabase; CREATE OR REPLACE TABLE testdatabase.public.emqx ( clientid STRING, topic STRING, payload STRING, publish_received_at TIMESTAMP_LTZ ); CREATE STAGE IF NOT EXISTS testdatabase.public.emqx FILE_FORMAT = (TYPE = CSV PARSE_HEADER = TRUE FIELD_OPTIONALLY_ENCLOSED_BY = '"') COPY_OPTIONS = (ON_ERROR = CONTINUE PURGE = TRUE); CREATE PIPE IF NOT EXISTS testdatabase.public.emqx AS COPY INTO testdatabase.public.emqx FROM @testdatabase.public.emqx MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;新しいユーザーを作成し、そのユーザーに RSA 公開鍵を設定します:
sqlCREATE USER IF NOT EXISTS snowpipeuser PASSWORD = 'Snowpipeuser99' MUST_CHANGE_PASSWORD = FALSE; ALTER USER snowpipeuser SET RSA_PUBLIC_KEY = ' <YOUR_PUBLIC_KEY_CONTENTS_LINE_1> <YOUR_PUBLIC_KEY_CONTENTS_LINE_2> <YOUR_PUBLIC_KEY_CONTENTS_LINE_3> <YOUR_PUBLIC_KEY_CONTENTS_LINE_4> ';TIP
PEM ファイルの
-----BEGIN PUBLIC KEY-----および-----END PUBLIC KEY-----行は削除し、残りの内容を改行を保持したまま含めてください。ユーザーが Snowflake リソースを管理できるように必要なロールを作成し割り当てます:
sqlCREATE OR REPLACE ROLE snowpipe; GRANT USAGE ON DATABASE testdatabase TO ROLE snowpipe; GRANT USAGE ON SCHEMA testdatabase.public TO ROLE snowpipe; GRANT INSERT, SELECT ON testdatabase.public.emqx TO ROLE snowpipe; GRANT READ, WRITE ON STAGE testdatabase.public.emqx TO ROLE snowpipe; GRANT OPERATE, MONITOR ON PIPE testdatabase.public.emqx TO ROLE snowpipe; GRANT ROLE snowpipe TO USER snowpipeuser; ALTER USER snowpipeuser SET DEFAULT_ROLE = snowpipe;
コネクターの作成
Snowflake Sink を追加する前に、EMQX で Snowflake への接続を確立するためのコネクターを作成します。
- ダッシュボードの Integration -> Connector ページに移動します。
- 右上の Create ボタンをクリックします。
- コネクタータイプとして Snowflake を選択し、次へ進みます。
- コネクター名を入力します。英数字の組み合わせで、ここでは
my-snowflakeと入力します。 - 接続情報を入力します。
- Account:Snowflake の組織IDとアカウント名をハイフン(
-)で区切って入力します。これは Snowflake プラットフォームの URL の一部で、Snowflake コンソールで確認可能です。 - Server Host:Snowflake のエンドポイント URL で、通常
<Your Snowflake Organization ID>-<Your Snowflake Account Name>.snowflakecomputing.comの形式です。<Your Snowflake Organization ID>-<Your Snowflake Account Name>はご自身の Snowflake インスタンス固有のサブドメインに置き換えてください。 - Data Source Name(DSN):ODBC ドライバー設定時に
.odbc.iniファイルで設定したsnowflakeを入力します。 - Username:前述の設定で作成した
snowpipeuserを入力します。 - Password:前述の設定で定義した
Snowpipeuser99を入力します。
- Account:Snowflake の組織IDとアカウント名をハイフン(
- 暗号化接続を確立したい場合は、Enable TLS のトグルスイッチをオンにします。TLS 接続の詳細は TLS for External Resource Access を参照してください。
- 詳細設定(任意):Advanced Settings を参照してください。
- Create をクリックする前に、Test Connectivity ボタンでコネクターが Snowflake に接続できるかテストできます。
- 最後に、ページ下部の Create ボタンをクリックしてコネクター作成を完了します。
これでコネクターの作成が完了し、次にルールと Sink を作成してデータの書き込み方法を指定できます。
Snowflake Sink を使ったルールの作成
このセクションでは、EMQX でソース MQTT トピック t/# からのメッセージを処理し、処理結果を設定済みの Snowflake Sink を通じて Snowflake に書き込むルールの作成方法を示します。
ダッシュボードの Integration -> Rules ページに移動します。
右上の Create ボタンをクリックします。
ルールID に
my_ruleと入力し、SQL エディターに以下のルール SQL を入力します:sqlSELECT clientid, unix_ts_to_rfc3339(publish_received_at, 'millisecond') as publish_received_at, topic, payload FROM "t/#"TIP
SQL に不慣れな場合は、SQL Examples をクリックし、Enable Debug を有効にしてルール SQL の結果を学習・テストできます。
TIP
Snowflake 連携では、選択するフィールドが Snowflake 側で定義したテーブルのカラム数および名前と完全に一致していることが重要です。余分なフィールドを追加したり、
*で全選択することは避けてください。アクションを追加し、Action Type ドロップダウンリストから
Snowflakeを選択します。アクションのドロップダウンはデフォルトのcreate actionのままにするか、既存の Snowflake アクションを選択します。ここでは新しい Sink を作成してルールに追加します。Sink の名前(例:
snowflake_sink)と簡単な説明を入力します。先に作成した
my-snowflakeコネクターをコネクタードロップダウンから選択します。ドロップダウン横の作成ボタンをクリックしてポップアップで新規コネクターを素早く作成することも可能です。必要な設定パラメータは Create a Connector を参照してください。以下の設定を行います:
- Database Name:
testdatabaseを入力。EMQX データ保存用に作成した Snowflake データベースです。 - Schema:
publicを入力。testdatabase内のデータテーブルがあるスキーマです。 - Stage:
emqxを入力。Snowflake でデータをテーブルにロードする前に保持するステージです。 - Pipe:
emqxを入力。ステージからテーブルへのロード処理を自動化するパイプです。 - Pipe User:
snowpipeuserを入力。パイプ管理権限を持つ Snowflake ユーザーです。 - Private Key:RSA プライベートキーのパス(例:
file://<path to snowflake_rsa_key.private.pem>)または RSA プライベートキーファイルの内容を入力します。これは安全な認証に使用され、Snowflake パイプへの安全なアクセスに必要です。ファイルパスを使用する場合は、クラスタ内のすべてのノードでパスが一貫しており、EMQX アプリケーションユーザーがアクセス可能である必要があります。
- Database Name:
Upload Mode を選択します。現在は
Aggregated Uploadのみサポートしています。この方法は複数のルールトリガー結果を単一ファイル(例:CSV ファイル)にまとめて Snowflake にアップロードし、ファイル数を減らして書き込み効率を向上させます。Aggregation Type を選択します。現在は
csvのみサポートしています。データはカンマ区切りの CSV 形式で Snowflake にステージングされます。Column Order:ドロップダウンリストから列の順序を選択します。生成される CSV ファイルは、選択した列の順序でソートされ、未選択の列はアルファベット順にソートされます。
Max Records:集約がトリガーされる最大レコード数を設定します。例えば
1000に設定すると、1000 レコード収集後にアップロードされます。最大レコード数に達すると単一ファイルの集約が完了しアップロードされ、時間間隔がリセットされます。Time Interval:集約が行われる時間間隔(秒)を設定します。例えば
60に設定すると、最大レコード数に達していなくても 60 秒ごとにデータがアップロードされ、最大レコード数がリセットされます。
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義できます。これらはプライマリ Sink がメッセージ処理に失敗した場合にトリガーされます。詳細は Fallback Actions を参照してください。
Advanced Settings を展開し、必要に応じて詳細設定を行います(任意)。詳細は Advanced Settings を参照してください。
残りの設定はデフォルト値のままにし、Create ボタンをクリックして Sink 作成を完了します。作成成功後、ルール作成画面に戻り、新しい Sink がルールアクションに追加されます。
ルール作成画面で Create ボタンをクリックし、ルール作成全体を完了します。
これでルールの作成が完了しました。Rules ページで新規作成したルールを確認でき、Actions (Sink) タブで新しい Snowflake Sink を確認できます。
また、Integration -> Flow Designer をクリックするとトポロジーを視覚的に確認できます。トポロジーは、トピック t/# のメッセージがルール my_rule によって解析され、Snowflake に書き込まれる流れを示します。
ルールのテスト
このセクションでは、設定したルールのテスト方法を示します。
テストメッセージのパブリッシュ
MQTTX を使ってトピック t/1 にメッセージをパブリッシュします:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "Hello Snowflake" }'この操作を数回繰り返して複数のテストメッセージを生成してください。
Snowflake 内のデータ確認
テストメッセージ送信後、Snowflake にデータが正常に書き込まれたかを確認します。
Snowflake のウェブインターフェースを開き、認証情報で Snowflake コンソールにログインします。
Snowflake コンソールで以下の SQL クエリを実行し、ルールによって書き込まれた
emqxテーブルのデータを表示します:SELECT * FROM testdatabase.public.emqx;これにより、
emqxテーブルにアップロードされたすべてのレコードが表示され、clientid、topic、payload、publish_received_atフィールドを確認できます。送信したテストメッセージ(例:
{ "msg": "Hello Snowflake" })や、トピック、タイムスタンプなどのメタデータが確認できるはずです。
詳細設定
このセクションでは、Snowflake Sink の詳細設定オプションについて説明します。ダッシュボードで Sink を設定する際、Advanced Settings を展開して以下のパラメータをニーズに応じて調整できます。
| フィールド名 | 説明 | デフォルト値 |
|---|---|---|
| Max Retries | アップロード失敗時の最大リトライ回数を設定します。例えば 3 を入力すると3回までリトライします。 | 3 |
| Buffer Pool Size | バッファワーカープロセスの数を指定します。これらのワーカーは EMQX と Snowflake 間のデータフローを管理し、一時的にデータを保持・処理します。パフォーマンス最適化とスムーズなデータ送信に重要です。 | 16 |
| Request TTL | リクエストの有効期間(秒)を設定します。リクエストがバッファに入ってからの最大有効時間を指定し、この期間を超えたリクエストは期限切れとみなされます。レスポンスやアックがタイムリーに返らない場合も期限切れとなります。 | |
| Health Check Interval | Snowflake との接続の自動ヘルスチェックを行う間隔(秒)を指定します。 | 15 |
| Max Buffer Queue Size | Snowflake Sink の各バッファワーカーが保持可能な最大バイト数を指定します。バッファワーカーはデータを一時保管し、効率的にデータストリームを処理します。システム性能やデータ送信要件に応じて調整してください。 | 256 |
| Query Mode | リクエストモードを synchronous または asynchronous から選択し、メッセージ送信を最適化します。非同期モードでは Snowflake への書き込みが MQTT メッセージのパブリッシュをブロックしませんが、クライアントがメッセージ到達前に受信する可能性があります。 | Asynchronous |
| Batch Size | EMQX から Snowflake へ一度に送信するデータバッチの最大サイズを指定します。サイズ調整によりデータ転送の効率と性能を微調整できます。1 に設定すると、データレコードを個別に送信し、バッチ化しません。 | 1 |
| Inflight Window | "インフライトキューリクエスト" は開始済みでまだレスポンスやアックを受け取っていないリクエストを指します。この設定は Snowflake との通信中に同時に存在可能なインフライトリクエストの最大数を制御します。 Request Mode が asynchronous の場合、同一 MQTT クライアントからのメッセージを厳密に順序処理したい場合はこの値を 1 に設定してください。 | 100 |
| Connect Timeout | Snowflake への接続試行時のタイムアウト時間(秒)を指定します。例えば 30 秒に設定すると、その時間内に接続できなければリトライ(Max Retries に基づく)またはエラーを発生させます。ネットワークレイテンシや接続信頼性管理に役立ちます。 | 15 |
| HTTP Pipelining | レスポンス待ちをせずに送信可能な HTTP リクエストの最大数を指定します。 | 100 |
| Connection Pool Size | EMQX が Snowflake に同時に維持可能な接続数を定義します。大きいほど同時リクエスト数が増え高負荷に対応可能ですが、システムリソース消費も増加します。 | 8 |