摄像头与视觉识别
摄像头与视觉识别为设备智能体提供本轮请求的画面上下文,用于读取状态灯、屏幕文字、仪表读数、物体和现场环境,并结合设备规格回答问题或决定控制动作;真实设备上线、命令执行和状态上报仍通过 MQTT 或设备 SDK 完成。
使用前准备
启用摄像头和视觉识别前,需要先完成以下准备:
- 已创建设备智能体,并为目标设备定义好设备规格。视觉结果如果需要触发控制,仍会落到这些命令、属性字段和事件上。
- 已在 配置 中启用视觉能力,或确认当前设备智能体模型支持图像输入。
- 控制台使用需要浏览器摄像头权限。
- SDK/设备端接入需要能拍照或获取图像帧,并能通过 SDK 或 HTTP 接口上传图片。
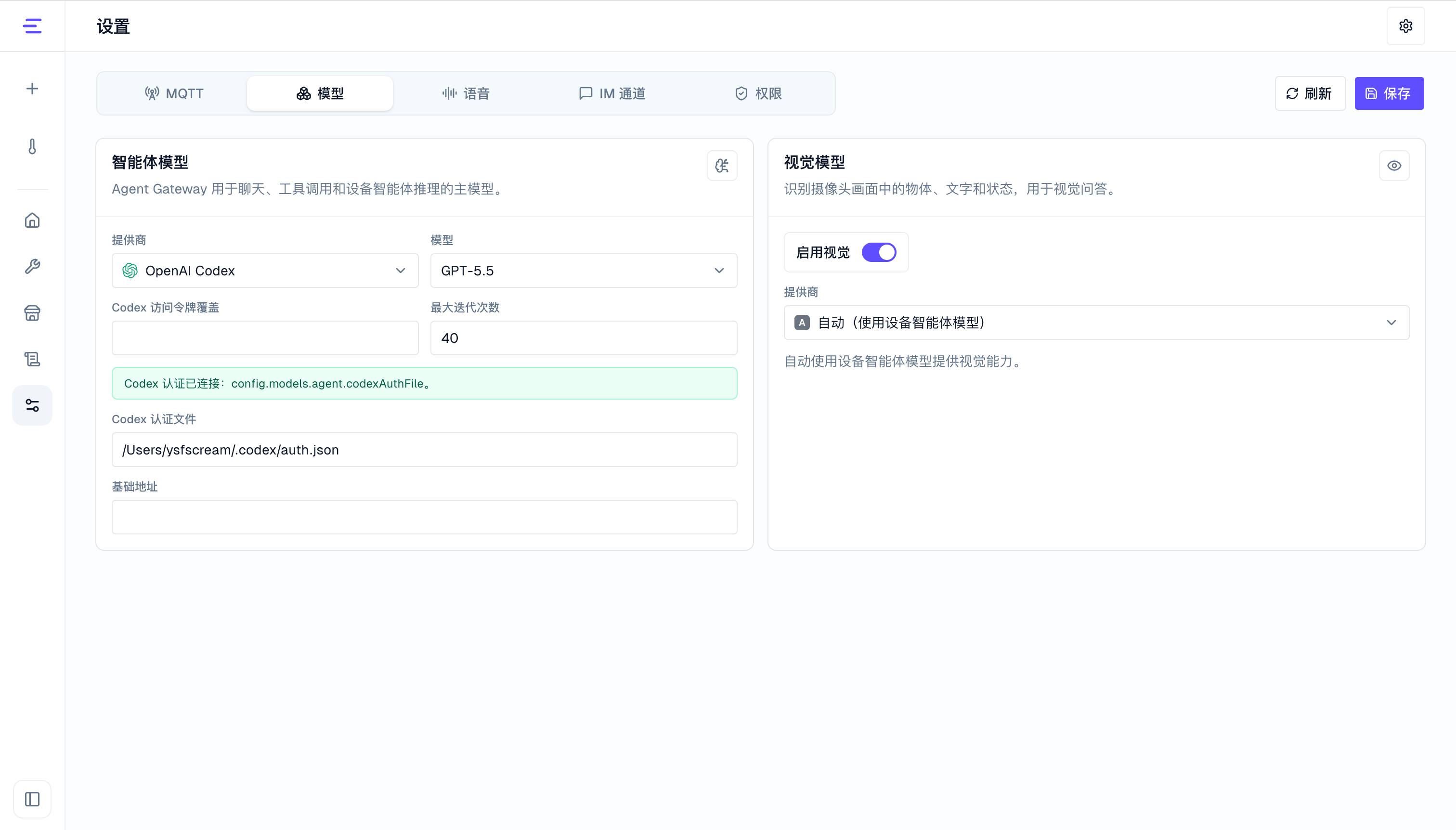
配置视觉能力
在 配置 中启用视觉能力。当前支持两种配置方式:
| 方式 | 说明 |
|---|---|
| 自动 | 使用当前设备智能体模型的图像输入能力;如果主模型不支持图像输入,则视觉识别不可用 |
| DashScope | 使用配置的 Qwen VL 等视觉模型,需要提供对应 API 密钥 |
常用配置包括是否启用视觉、模型服务商、模型名称、API 密钥和超时时间。完整配置项见 配置。
控制台使用和 SDK 接入
摄像头和视觉识别有两条使用路径。通常先用控制台验证识别效果,再接入 SDK 到真实设备或图像来源。
| 路径 | 适用场景 | 需要完成 |
|---|---|---|
| 控制台使用 | 开发调试、演示、验证设备智能体是否能理解现场画面 | 启用视觉能力,选中设备后打开摄像头入口,并授权浏览器摄像头 |
| SDK/设备端接入 | 设备本身带摄像头、截图、检测画面或图像来源 | 设备端上传图像帧,并把返回的 visionRefs 带入对话请求 |
控制台使用适合快速确认识别效果和设备上下文。SDK/设备端接入负责从真实设备、截图或检测系统上传图片。两种方式都会进入同一个设备智能体会话,并使用同一份设备规格。
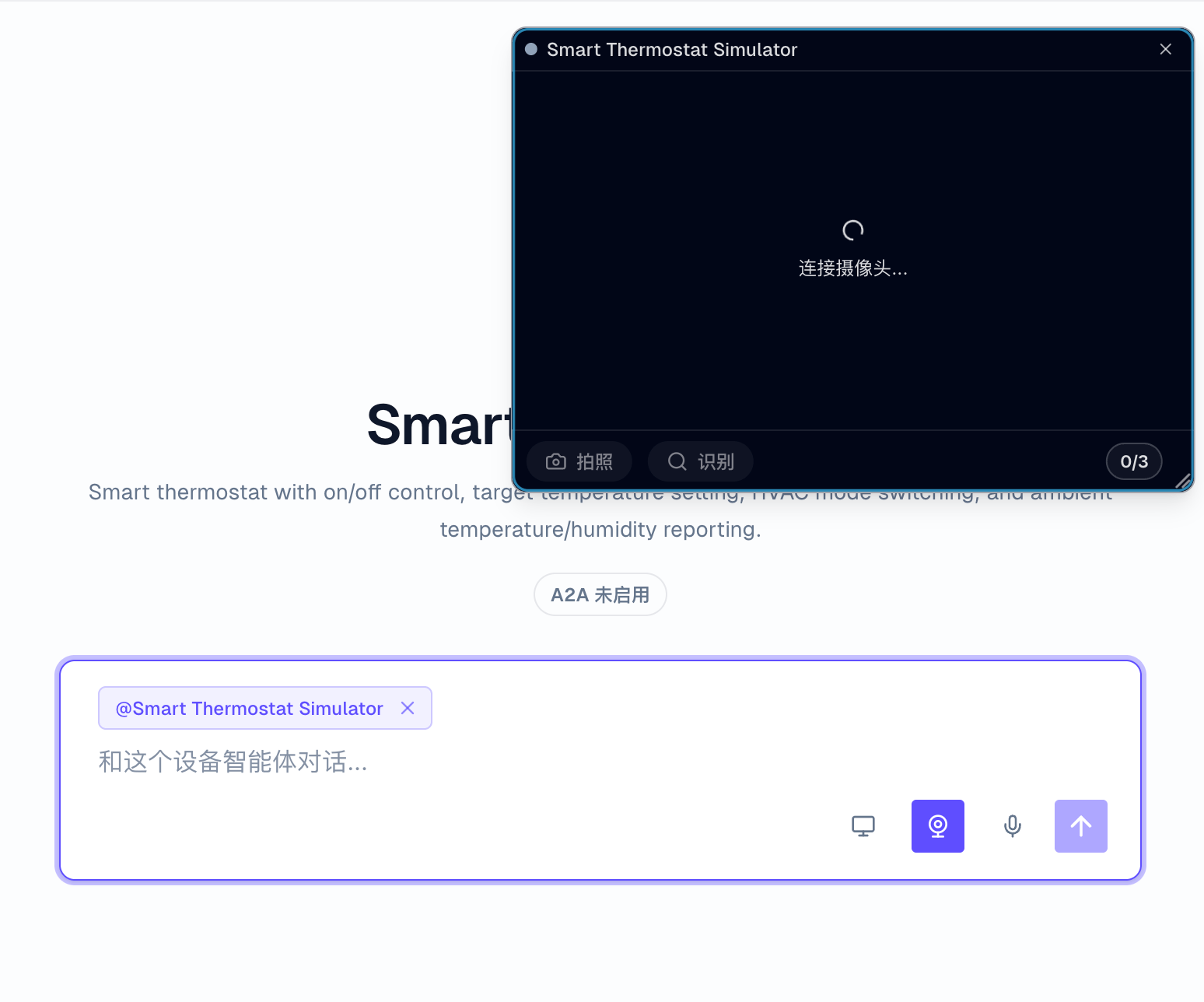
控制台使用
进入设备智能体工作区并选中设备,打开摄像头入口。当前画面会绑定到这台设备。
控制台使用时可以:
- 确认摄像头预览正常,并把画面对准状态灯、屏幕、仪表或需要识别的物体。
- 放大摄像头预览窗口,或拖动窗口位置,避免遮挡当前操作区域。
- 点击 拍照 和 识别,把最近拍摄的画面作为一次视觉识别请求提交。
- 在文本或语音请求中引用当前画面,例如询问“状态灯是什么颜色”或“屏幕上显示的告警是什么”。
- 查看回答是否只基于画面可见内容,并确认需要控制设备时是否调用了预期命令。
SDK/设备端接入
生成设备 SDK 后,工程会包含视觉相关代码或示例。设备端接入步骤如下:
- 先启动设备端 MQTT 或 SDK 连接,确认设备在控制台在线。
- 在设备端采集图片,例如摄像头拍照、屏幕截图或检测画面。
- 上传图像帧到
/api/vision/frames,获取返回的visionRefs。 - 调用
/api/chat时带上visionRefs,让设备智能体把图片作为本轮请求上下文。 - 如果识别结果需要控制设备,真实设备仍然通过 MQTT 或 SDK 收到命令并返回响应。
语音和视觉是两条独立路径:语音走 /ws/voice,拍照识物走 /api/vision/frames 加 /api/chat。如果需要设备智能体帮助生成设备端拍照识物逻辑,可以在 SDK 接入 中使用智能体适配和增强 SDK。
需要验证设备的可视化输出时,使用 模拟显示器。
验证结果
完成配置、控制台使用或 SDK/设备端接入后,至少验证这些结果:
- 控制台摄像头可以预览画面,浏览器权限没有被拦截。
- 拍照或上传图片后,设备智能体能基于画面回答问题。
- 文本或语音请求附带画面时,回答能结合当前设备上下文。
- 查询类问题能读到真实设备状态,控制类指令能触发设备规格中定义的命令。
- 设备端上传的图片不会被当作长期资产,只用于本轮或短时间内的识别请求。
注意事项
视觉识别只使用本轮或最近的图像帧,不会长期保存图片。回答应基于画面可见内容;摄像头能力仍取决于浏览器权限和设备可用性。