语音交互
语音交互把麦克风输入接入当前设备会话,识别文本会按设备规格完成查询或控制;语音通道只处理音频、识别文本和播报,真实设备上线、命令执行和状态上报仍通过 MQTT 或设备 SDK 完成。
使用前准备
启用语音前,需要先完成以下准备:
- 已创建设备智能体,并为目标设备定义好设备规格。语音请求最终会落到这些命令、属性字段和事件上。
- 目标设备已通过 MQTT 或设备 SDK 接入,并能接收命令、返回结果和上报状态。
- 已准备可用的语音识别和语音合成服务商凭证。
- 控制台使用需要浏览器麦克风权限;SDK/设备端接入需要设备端能采集麦克风音频并播放合成音频。
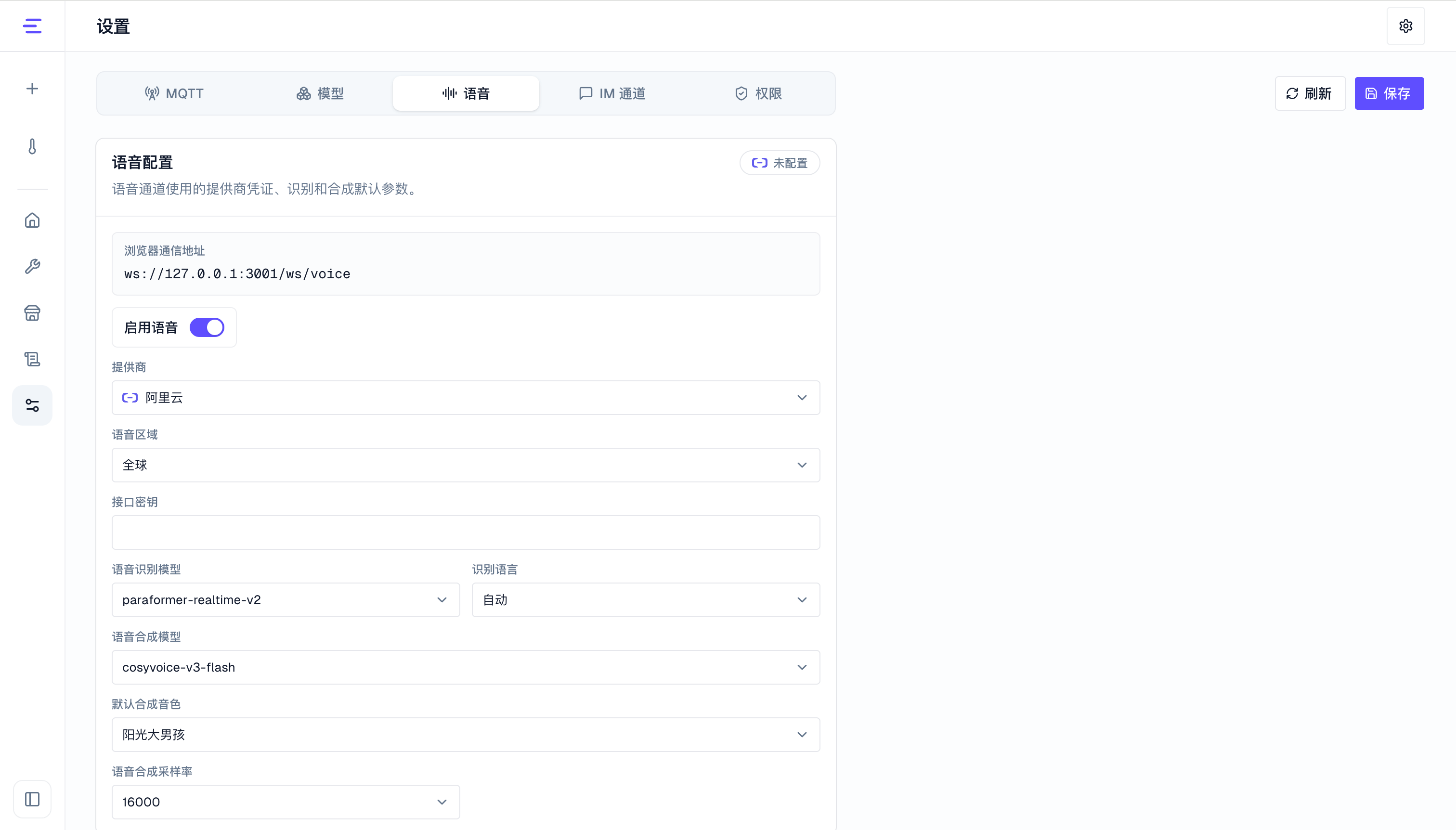
配置语音服务
在 配置 中启用语音能力,并选择语音服务商。当前支持:
| 服务商 | 能力 |
|---|---|
| 火山引擎 | 语音识别和语音合成 |
| 阿里云百炼 DashScope | 语音识别和语音合成 |
| AWS | Transcribe 语音识别和 Polly 语音合成 |
| ElevenLabs | 语音识别和语音合成 |
常用配置包括:
- 是否启用语音。
- 语音监听地址和端口。
- 语音区域、识别采样率、服务商凭证、识别模型、合成模型和音色。
- 如需远程浏览器访问或生产部署,可配置语音 TLS。
远程接入方式见 语音配置。
控制台使用和 SDK 接入
语音交互有两条使用路径。通常先用控制台验证识别质量和控制链路,再接入 SDK 到真实设备。
| 路径 | 适用场景 | 需要完成 |
|---|---|---|
| 控制台使用 | 开发调试、演示、验证设备规格是否适合语音控制 | 启用语音配置,选中设备后用浏览器麦克风发起请求 |
| SDK/设备端接入 | 设备本身带麦克风、扬声器或系统音频接口 | 设备端连接 /ws/voice,发送音频帧,播放返回的 TTS 音频 |
控制台使用适合快速确认语音识别、设备上下文和命令调用。SDK/设备端接入负责真实设备的音频采集与播放。两种方式都会进入同一个设备智能体会话,并使用同一份设备规格。
控制台使用
进入设备智能体工作区并选中设备,打开语音入口。后续语音请求都会绑定到这台设备。
控制台使用时可以:
- 发起一条和设备规格相关的语音指令,例如查询状态、调整参数或触发某个动作。
- 查看识别文本是否准确,并确认设备智能体是否调用了预期命令或读取了预期状态。
- 听取语音回复,必要时中断当前朗读。
- 将识别出的文本转回输入框继续编辑,用于排查识别错误或提示词问题。
如果同时开启摄像头,语音请求结束时可以携带当前画面。设备智能体会在用户询问可见内容时使用视觉能力,例如识别状态灯、读取屏幕文字或判断画面中的物体。
SDK/设备端接入
生成设备 SDK 后,工程会包含语音连接信息,例如 VOICE_CHAT_HOST;C SDK 还包含可运行的语音聊天示例。设备端接入步骤如下:
- 先启动设备端 MQTT 或 SDK 连接,确认设备在控制台在线。
- 读取 SDK 工程中的语音配置,连接 Agent Gateway 的
/ws/voice。 - 建立连接后发送
hello,带上设备 ID、会话 ID、服务商和音频参数。 - 用户开始说话时发送
listen,随后持续发送 16 kHz、单声道、Int16LE PCM 音频帧。 - 用户结束说话时发送
stop。如需结合摄像头画面,可在结束时带上视觉帧引用。 - 监听识别文本、设备智能体回复和 TTS 音频帧,把音频帧接到设备扬声器或系统音频播放。
不使用生成 SDK 时,可以直接按 WebSocket 协议接入。协议消息、Header 和 hello 示例见 API 参考。
语音请求触发设备控制时,真实设备仍然通过 MQTT 或 SDK 收到命令并返回响应。设备端不需要维护额外的“语音命令”分支,以免和设备规格中的命令定义不一致。
如需生成带麦克风、扬声器或系统音频接口适配逻辑的设备端代码,可以在 SDK 接入 中使用智能体适配和增强 SDK。
验证结果
完成控制台配置或 SDK/设备端接入后,至少验证这些结果:
- 语音 WebSocket 可以连接,
hello能返回会话信息。 - 麦克风音频能被识别成文本,且识别文本进入当前设备的对话上下文。
- 查询类问题能读到真实设备状态,控制类指令能触发设备规格中定义的命令。
- 设备端能收到命令、返回执行结果,并在控制台或日志中看到对应记录。
- TTS 音频能在浏览器或真实设备上播放,
abort可以中断当前朗读。 - 远程访问或生产部署时,客户端使用 语音连接地址 和对应的 TLS 配置。
注意事项
语音功能需要启用通道、配置 语音连接地址、允许麦克风权限,并配置可用的语音服务商。它更适合手动发起的短语音交互;长报告、复杂表格、代码、唤醒词和持续后台监听场景更适合放在语音流程之外处理。