将 MQTT 数据写入到 Amazon S3 存储桶中
Amazon S3 是一种面向互联网的存储服务,具有高度的可靠性、稳定性和安全性,能够快速部署和使用。EMQX Cloud 能够将 MQTT 消息高效地存储至 Amazon S3 存储桶中,实现灵活的物联网数据存储功能。
本页详细介绍了 EMQX Cloud 与 Amazon S3 的数据集成并提供了实用的规则和动作创建指导。
工作原理
Amazon S3 数据集成是 EMQX Cloud 中开箱即用的功能,通过简单的配置即可实现复杂的业务开发。在一个典型的物联网应用中,EMQX Cloud 作为物联网平台,负责接入设备进行消息传输,Amazon S3 作为数据存储平台,负责消息数据的存储。
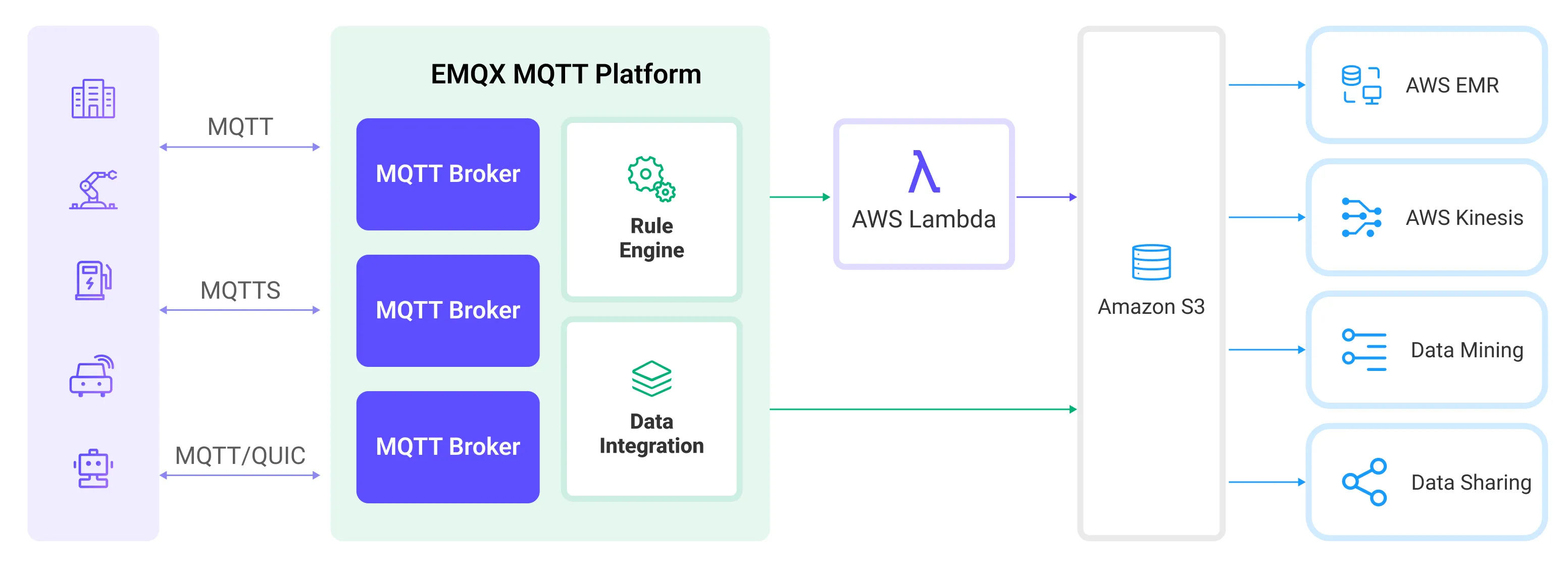
EMQX Cloud 通过规则和动作将设备事件和数据转发至 Amazon S3,应用读取 Amazon S3 中数据即可进行数据的应用。其具体的工作流程如下:
- 设备连接到 EMQX Cloud:物联网设备通过 MQTT 协议连接成功后将触发上线事件,事件包含设备 ID、来源 IP 地址以及其他属性等信息。
- 设备消息发布和接收:设备通过特定的主题发布遥测和状态数据,EMQX Cloud 接收到消息后将在规则引擎中进行比对。
- 规则引擎处理消息:通过内置的规则引擎,可以根据主题匹配处理特定来源的消息和事件。规则引擎会匹配对应的规则,并对消息和事件进行处理,例如转换数据格式、过滤掉特定信息或使用上下文信息丰富消息。
- 写入到 Amazon S3:规则触发后,消息会被写入到 Amazon S3。通过使用 Amazon S3动作,用户可以从处理结果中提取数据并发送到 S3。消息可以以文本、二进制格式存储,或者将多行结构化数据聚合成一个 CSV 文件,具体取决于消息内容和动作的配置。
事件和消息数据写入到 Amazon S3 后,您可以连接到 Amazon S3 读取数据,进行灵活的应用开发,例如:
- 数据归档:将设备消息作为对象存储,长期保存在 Amazon S3 中,以满足数据保留和合规性要求。
- 数据分析:将 S3 中的数据导入到分析服务例如 Snowflake 中,实现预测性维护、设备效能评估等数据分析业务。
特性与优势
在 EMQX Cloud 中使用 Amazon S3 数据集成能够为您的业务带来以下特性与优势:
- 消息转换:消息可以在写入 Amazon S3 之前,通过 EMQX Cloud 规则中进行丰富的处理和转换,方便后续的存储和使用。
- 灵活数据操作:通过 S3 数据集成,可以方便地将特定字段的数据写入到 Amazon S3 存储桶中,支持动态设置存储桶与对象键,实现数据的灵活存储。
- 整合业务流程:通过 S3 数据集成 可以将设备数据与 Amazon S3 丰富的生态应用结合,以实现更多的业务场景,例如数据分析、数据归档等。
- 低成本长期存储:相较于数据库,Amazon S3 提供了高可用、高可靠、低成本的对象存储服务,可以满足长期存储的需求。
通过以上特性,您可以构建高效、可靠和可扩展的物联网应用,并在业务决策和优化方面受益。
准备工作
本节介绍了在 EMQX Cloud 中创建 Amazon S3 数据集成之前需要做的准备工作。
前置准备
网络设置
由于 EMQX 通过公网访问 Amazon S3,您需要在部署中开通 NAT 网关。您可以在部署左侧菜单栏中点击网络管理,在页面中找到 NAT 网关,点击 +NAT 网关按钮开通 NAT 网关服务。
准备 S3 存储桶
EMQX Cloud 支持 Amazon S3 以及兼容 S3 的存储服务,您可以使用 AWS 云服务创建 S3 存储桶。
在 AWS S3 控制台中,点击创建存储桶按钮。然后按照向导的指示填写相关信息,如存储桶名称(例如
emqx-cloud-s3-connector-test)、区域等,创建一个 S3 存储桶。详细操作可参考 AWS 文档。设置存储桶权限:在存储桶创建成功后,选择该存储桶,并点击权限选项卡,根据需求可以为存储桶选择公共读写、私有等权限。设置存储桶访问权限可以参考以下 JSON:
json{ "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1ListBucket", "Effect": "Allow", "Action": ["s3:ListBucket"], "Resource": ["arn:aws:s3:::emqx-cloud-s3-connector-test"] }, { "Sid": "Stmt2GetAndPutObject", "Effect": "Allow", "Action": ["s3:GetObject", "s3:PutObject"], "Resource": ["arn:aws:s3:::emqx-cloud-s3-connector-test/*"] }, { "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }获取访问密钥:在 AWS 控制台中,搜索并选择 IAM 服务,为 S3 创建一个新的用户,获取 Access Key 和 Secret Key。
至此,您已经完成了 S3 存储桶的创建与配置,接下来我们将在 EMQX Cloud 中创建 Amazon S3 动作。
创建连接器
在创建数据集成的规则之前,您需要先创建一个 Amazon S3 连接器用于访问 S3 服务。
在部署菜单中选择数据集成,在数据转发分类下选择 S3。如果您已经创建了其他的连接器,点击新建连接器,然后在数据转发服务分类下选择 S3。
连接器名称:系统将自动生成一个连接器的名称。
填写连接相关配置:
- 地址:主机地址因不同区域而异,格式为 s3.{region}.amazonaws.com。
- 端口:填写
443。 - 访问密钥 ID 和访问密钥填写 AWS 中创建的访问密钥。
点击启用 TLS,并关闭验证服务器证书。
点击测试连接按钮,如果 S3 能够正常访问,则会返回连接器可用提示。
点击新建按钮完成连接器的创建。
接下来,您可以基于此连接器创建数据集成规则。
创建规则
本节演示了如何在 EMQX Cloud 中创建一条规则,用于处理来自源 MQTT 主题 t/# 的消息,并通过配置的动作将处理后的结果写入到 S3 的 emqx-cloud-s3-connector-test 存储桶中。
点击连接器列表操作列下的新建规则图标或在规则列表中点击新建规则进入新建规则步骤页。
在 SQL 编辑器中输入规则 SQL 如下:
sqlSELECT * FROM "t/#"TIP
如果您初次使用 SQL,可以点击 SQL 示例 和启用调试来学习和测试规则 SQL 的结果。
点击下一步开始创建包含 Amazon S3 Sink 的动作。
从使用连接器下拉框中选择您之前创建的连接器。
设置存储桶,此处输入
emqx-cloud-s3-connector-test,此处也支持${var}格式的占位符,但要注意需要在 S3 中预先创建好对应名称的存储桶。根据情况选择 ACL,指定上传对象的访问权限。
选择上传方式,两种方式区别如下:
- 直接上传:每次规则触发时,按照预设的对象键和内容直接上传到 S3,适合存储二进制或体积较大的文本数据。这种方法可能会生成大量的文件。
- 聚合上传:将多次规则触发的结果打包为一个文件(如 CSV 文件)并上传到 S3,适合存储结构化数据。这种方法可以减少文件数量,提高写入效率。
两种方式配置的参数不同,请根据所选方式进行配置:
展开高级设置,根据需要配置高级设置选项(可选),详细请参考高级设置。
点击确认按钮完成动作的配置。
在弹出的成功创建规则提示框中点击返回规则列表,从而完成了整个数据集成的配置链路。
测试规则
此处以直接上传为例进行测试。使用 MQTTX 向 t/1 主题发布消息:
mqttx pub -i EMQX Cloud_c -t t/1 -m '{ "msg": "hello S3" }'发送几条消息后,访问 Amazon S3 控制台查看结果。
登录 AWS 管理控制台并打开 Amazon S3 控制台: https://console.aws.amazon.com/s3/。
在存储桶列表中,选择 iot-data 存储桶,进入存储桶。你可以在对象列表看到刚刚发布的消息已成功写入到 msg 对象中。选中该对象旁边的复选框,然后选择 下载,可将对象下载至本地查看。
高级设置
本节将深入介绍可用于 S3 动作的高级配置选项。在数据集成中配置 动作 时,您可以根据您的特定需求展开高级设置,调整以下参数。
| 字段名称 | 描述 | 默认值 |
|---|---|---|
| 缓存池大小 | 指定缓冲区工作进程数量,这些工作进程将被分配用于管理 EMQX Cloud 与 S3 的数据流,它们负责在将数据发送到目标服务之前临时存储和处理数据。此设置对于优化性能并确保 动作 数据传输顺利进行尤为重要。 | 16 |
| 请求超期 | “请求 TTL”(生存时间)设置指定了请求在进入缓冲区后被视为有效的最长持续时间(以秒为单位)。此计时器从请求进入缓冲区时开始计时。如果请求在缓冲区内停留的时间超过了此 TTL 设置或者如果请求已发送但未能在 S3 中及时收到响应或确认,则将视为请求已过期。 | 45 |
| 健康检查间隔 | 指定 动作 对与 S3 的连接执行自动健康检查的时间间隔(以秒为单位)。 | 15 |
| 缓存队列最大长度 | 指定可以由 S3 动作 中的每个缓冲器工作进程缓冲的最大字节数。缓冲器工作进程在将数据发送到 S3 之前会临时存储数据,充当处理数据流的中介以更高效地处理数据流。根据系统性能和数据传输要求调整该值。 | 256 |
| 请求模式 | 允许您选择同步或异步请求模式,以根据不同要求优化消息传输。在异步模式下,写入到 S3 不会阻塞 MQTT 消息发布过程。但是,这可能导致客户在它们到达 S3 之前就收到了消息。 | 异步 |
| 请求飞行队列窗口 | “飞行队列请求”是指已启动但尚未收到响应或确认的请求。此设置控制 动作 与 S3 通信时可以同时存在的最大飞行队列请求数。 当 请求模式 设置为 异步 时,“请求飞行队列窗口”参数变得特别重要。如果对于来自同一 MQTT 客户端的消息严格按顺序处理很重要,则应将此值设置为 1。 | 100 |