Amazon S3へのMQTTデータ取り込み
Amazon S3は、高い信頼性、安定性、およびセキュリティを備えたインターネットベースのストレージサービスであり、迅速なデプロイと使いやすさを特徴としています。EMQX CloudはMQTTメッセージを効率的にAmazon S3バケットに保存でき、柔軟なIoTデータストレージ機能を実現します。
本ページでは、EMQX CloudとAmazon S3間のデータ統合について詳しく紹介し、ルールおよびSinkの作成方法を実践的に解説します。
動作概要
EMQX CloudにおけるAmazon S3データ統合はすぐに利用可能な機能であり、複雑なビジネス開発にも簡単に設定できます。典型的なIoTアプリケーションでは、EMQX Cloudがデバイス接続とメッセージ送受信を担うIoTプラットフォームとして機能し、Amazon S3はメッセージデータの保存を担当するデータストレージプラットフォームとして利用されます。
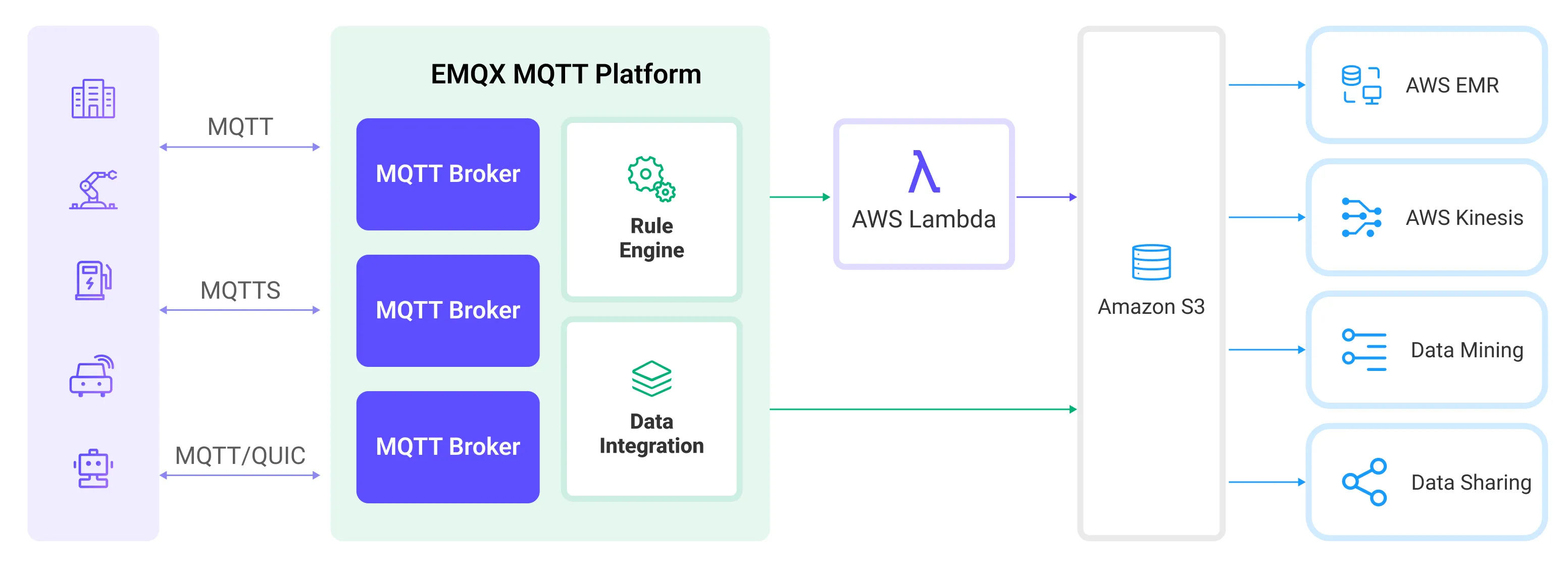
EMQX CloudはルールとSinkを利用してデバイスのイベントやデータをAmazon S3に転送します。アプリケーションはAmazon S3からデータを読み取り、さらなるデータ活用を行えます。具体的なワークフローは以下の通りです。
- デバイスのEMQX Cloudへの接続:IoTデバイスはMQTTプロトコルで正常に接続するとオンラインイベントをトリガーします。このイベントにはデバイスID、送信元IPアドレスなどのプロパティ情報が含まれます。
- デバイスのメッセージパブリッシュと受信:デバイスは特定のトピックを通じてテレメトリやステータスデータをパブリッシュします。EMQX Cloudはメッセージを受信し、ルールエンジン内で照合します。
- ルールエンジンによるメッセージ処理:組み込みのルールエンジンはトピックマッチングに基づき特定のソースからのメッセージやイベントを処理します。対応するルールをマッチングし、データ形式変換、特定情報のフィルタリング、コンテキスト情報の付加などの処理を行います。
- Amazon S3への書き込み:ルールはメッセージをS3に書き込むアクションをトリガーします。Amazon S3 Sinkを利用して処理結果からデータを抽出しS3に送信します。メッセージはテキストまたはバイナリ形式で保存可能で、複数行の構造化データをまとめてCSVファイルとして保存することもできます。これはメッセージ内容やSinkの設定によります。
イベントやメッセージデータがAmazon S3に書き込まれた後は、Amazon S3に接続してデータを読み取り、以下のような柔軟なアプリケーション開発が可能です。
- データアーカイブ:デバイスメッセージをAmazon S3のオブジェクトとして長期保存し、コンプライアンス要件やビジネスニーズに対応。
- データ分析:S3から分析サービス(例:Snowflake)にデータを取り込み、予知保全、デバイス効率評価などのデータ分析に活用。
特長とメリット
EMQX CloudのAmazon S3データ統合を利用することで、以下の特長とメリットが得られます。
- メッセージ変換:メッセージはEMQX Cloudのルール内で高度に処理・変換されてからAmazon S3に書き込まれるため、後続の保存や活用が容易になります。
- 柔軟なデータ操作:S3 Sinkにより特定のデータフィールドをAmazon S3バケットに簡単に書き込め、バケット名やオブジェクトキーの動的設定もサポートし柔軟なデータ保存が可能です。
- 統合されたビジネスプロセス:S3 Sinkを介してデバイスデータをAmazon S3の豊富なエコシステムアプリケーションと連携でき、データ分析やアーカイブなど多様なビジネスシナリオを実現します。
- 低コストの長期保存:データベースと比較して、Amazon S3は高可用性・高信頼性かつコスト効率の良いオブジェクトストレージサービスを提供し、長期保存に適しています。
これらの特長により、効率的で信頼性が高く、スケーラブルなIoTアプリケーションの構築とビジネスの意思決定・最適化が可能になります。
はじめる前に
このセクションでは、EMQX CloudでAmazon S3 Sinkを作成する前の準備事項を紹介します。
前提条件
ネットワーク設定
EMQXはパブリックネットワーク経由でAmazon S3にアクセスするため、デプロイメントにてNATゲートウェイを有効にする必要があります。トップメニューバーのVASをクリックし、NATゲートウェイカードを選択するか、デプロイメント概要ページの下部タブバーでNATゲートウェイサービスを有効化を選択してください。
S3バケットの準備
EMQX CloudはAmazon S3およびその他のS3互換ストレージサービスをサポートしています。ここではAWSクラウドサービスを利用してS3バケットを作成します。
AWS S3コンソールでCreate bucketボタンをクリックし、バケット名やリージョンなどの必要情報を入力してS3バケットを作成します。詳細な操作はAWSドキュメントを参照してください。
バケットの権限を設定します。バケット作成後、対象バケットを選択しPermissionsタブをクリックします。ニーズに応じてバケットをパブリック読み書き、プライベート、その他の権限に設定できます。以下のJSONを参考にアクセス権を設定してください。
json{ "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1ListBucket", "Effect": "Allow", "Action": ["s3:ListBucket"], "Resource": ["arn:aws:s3:::emqx-cloud-s3-connector-test"] }, { "Sid": "Stmt2GetAndPutObject", "Effect": "Allow", "Action": ["s3:GetObject", "s3:PutObject"], "Resource": ["arn:aws:s3:::emqx-cloud-s3-connector-test/*"] }, { "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }アクセスキーを取得します。AWSコンソールでIAMサービスを検索・選択し、S3用の新規ユーザーを作成してAccess KeyおよびSecret Keyを取得します。
Amazon S3バケットの作成と設定が完了したら、EMQX CloudでAmazon S3 Sinkの作成準備が整います。
Amazon S3コネクターの作成
データ統合ルールを作成する前に、対応するコネクターを作成する必要があります。
- 初めてコネクターを作成する場合は、Data Persistenceカテゴリの中からAmazon S3を選択します。既にコネクターを作成済みの場合は、New Connectorを選択し、続けてData Persistenceカテゴリの中からAmazon S3を選択します。
- Connector Name:システムが自動的にコネクター名を生成します。
- 接続情報を入力します:
- Host:リージョンによって異なり、
s3.{region}.amazonaws.comの形式です。 - Port:
443を入力します。 - Access Key IDおよびSecret Access Key:AWSで作成したアクセスキーを入力します。
- Enable TLSをクリックして有効化し、TLS Verifyはオフにします。
- Host:リージョンによって異なり、
- Testボタンをクリックします。Amazon S3サービスにアクセス可能であれば成功のメッセージが返されます。
- Newボタンをクリックして作成を完了します。
これでコネクターの作成が完了し、次にS3サービスに書き込むデータを指定するルールとSinkの作成に進みます。
ルールの作成
このセクションでは、EMQX CloudでソースMQTTトピックt/#からのメッセージを処理し、処理結果を設定済みのSinkを介してS3のemqx-cloud-s3-connector-testバケットに書き込むルールの作成方法を示します。
ルールエリアのNew Ruleをクリックするか、作成したコネクターのActions列にある新規ルールアイコンをクリックします。
SQL editorにルールのマッチングSQL文を入力します。
sqlSELECT * FROM "t/#"TIP
SQLに不慣れな場合は、SQL ExamplesやEnable DebugをクリックしてルールSQLの学習やテストが可能です。
NextをクリックしてAmazon S3 Sinkを含むアクションを追加します。
Connectorドロップダウンから先ほど作成したコネクターを選択します。
Bucketに
emqx-cloud-s3-connector-testを入力します。このフィールドは${var}形式のプレースホルダーもサポートしますが、事前にS3に対応するバケットが作成されている必要があります。必要に応じてACLを選択し、アップロードされるオブジェクトのアクセス権限を指定します。
Upload Methodを選択します。2つの方法の違いは以下の通りです。
- Direct Upload:ルールがトリガーされるたびに、設定済みのオブジェクトキーと内容に従って直接S3にデータをアップロードします。バイナリや大きなテキストデータの保存に適していますが、多数のファイルが生成される可能性があります。
- Aggregated Upload:複数のルールトリガー結果を1つのファイル(例:CSVファイル)にまとめてS3にアップロードします。構造化データの保存に適し、ファイル数を減らし書き込み効率を向上させます。
各方法で設定すべきパラメータは異なります。選択した方法に応じて設定してください。
Advanced Settingsを展開し、必要に応じて詳細設定を行います(任意)。詳細は詳細設定を参照してください。
Confirmボタンをクリックしてルール作成を完了します。
Successful new ruleのポップアップでBack to Rulesをクリックし、データ統合の設定チェーンが完了します。
ルールのテスト
このセクションでは、Direct Upload方式で設定したルールのテスト方法を示します。
MQTTXを使ってトピックt/1にメッセージをパブリッシュします。
mqttx pub -i EMQX Platform_c -t t/1 -m '{ "msg": "hello S3" }'数件のメッセージ送信後、MinIOコンソールまたはAmazon S3コンソールで結果を確認します。
AWSマネジメントコンソールにログインし、Amazon S3コンソールを開きます:https://console.aws.amazon.com/s3/
バケット一覧からemqx-cloud-s3-connector-testバケットを選択し、バケット内に入ります。オブジェクト一覧に先ほどパブリッシュしたメッセージがmsgオブジェクトとして正常に書き込まれていることが確認できます。オブジェクト横のチェックボックスを選択し、Downloadを選んでローカルにダウンロードし内容を確認してください。
詳細設定
このセクションではS3 Sinkの詳細設定オプションについて説明します。ダッシュボードのSink設定時にAdvanced Settingsを展開し、ニーズに応じて以下のパラメータを調整できます。
| フィールド名 | 説明 | デフォルト値 |
|---|---|---|
| Buffer Pool Size | EMQX CloudとS3間のデータフローを管理するバッファワーカープロセスの数を指定します。これらのワーカーはデータを一時的に保存・処理し、ターゲットサービスへ送信する前に最適化を行うため、パフォーマンス向上とスムーズなデータ伝送に重要です。 | 16 |
| Request TTL | 「Request TTL」(Time To Live)は、リクエストがバッファに入ってから有効とみなされる最大秒数を指定します。リクエストはバッファに入った時点でタイマーが開始され、このTTLを超えてバッファに留まるか、送信後にS3からの応答やアックを受け取れない場合、リクエストは期限切れとみなされます。 | |
| Health Check Interval | SinkがS3との接続状態を自動的にヘルスチェックする間隔(秒)を指定します。 | 15 |
| Max Buffer Queue Size | S3 Sinkの各バッファワーカーがバッファリングできる最大バイト数を指定します。バッファワーカーはデータを一時保存し、効率的にデータストリームを処理します。システム性能やデータ伝送要件に応じて調整してください。 | 256 |
| Query Mode | synchronousまたはasynchronousのリクエストモードを選択し、メッセージ伝送を最適化します。非同期モードではS3への書き込みがMQTTメッセージのパブリッシュ処理をブロックしませんが、クライアントがS3到達前にメッセージを受信する可能性があります。 | Asynchronous |
| In-flight Window | 「In-flight queue requests」は開始済みでまだ応答やアックを受け取っていないリクエストを指します。この設定はSinkがS3と通信中に同時に存在可能なin-flightリクエストの最大数を制御します。 Request Modeが asynchronousの場合、このパラメータは特に重要です。同一MQTTクライアントからのメッセージを厳密に順次処理する必要がある場合は、値を1に設定してください。 | 100 |