データ統合概要
EMQX ブローカーは、完全マネージド型の MQTT メッセージクラウドサービスとして、MQTT プロトコルを介してモノのインターネット(IoT)デバイスを接続し、リアルタイムでメッセージを配信します。この基盤をもとに、データ統合は EMQX ブローカーの他のクラウドリソースとの接続機能を強化し、デバイスと他の業務システムとのシームレスな統合を可能にします。EMQX ブローカーのデータ統合は、明確かつ柔軟な「設定可能」なアーキテクチャソリューションを提供するだけでなく、開発プロセスを簡素化します。これによりユーザーの利便性が向上し、業務システムと EMQX ブローカー間の結合度を低減し、データ転送のためのより良いインフラを提供します。
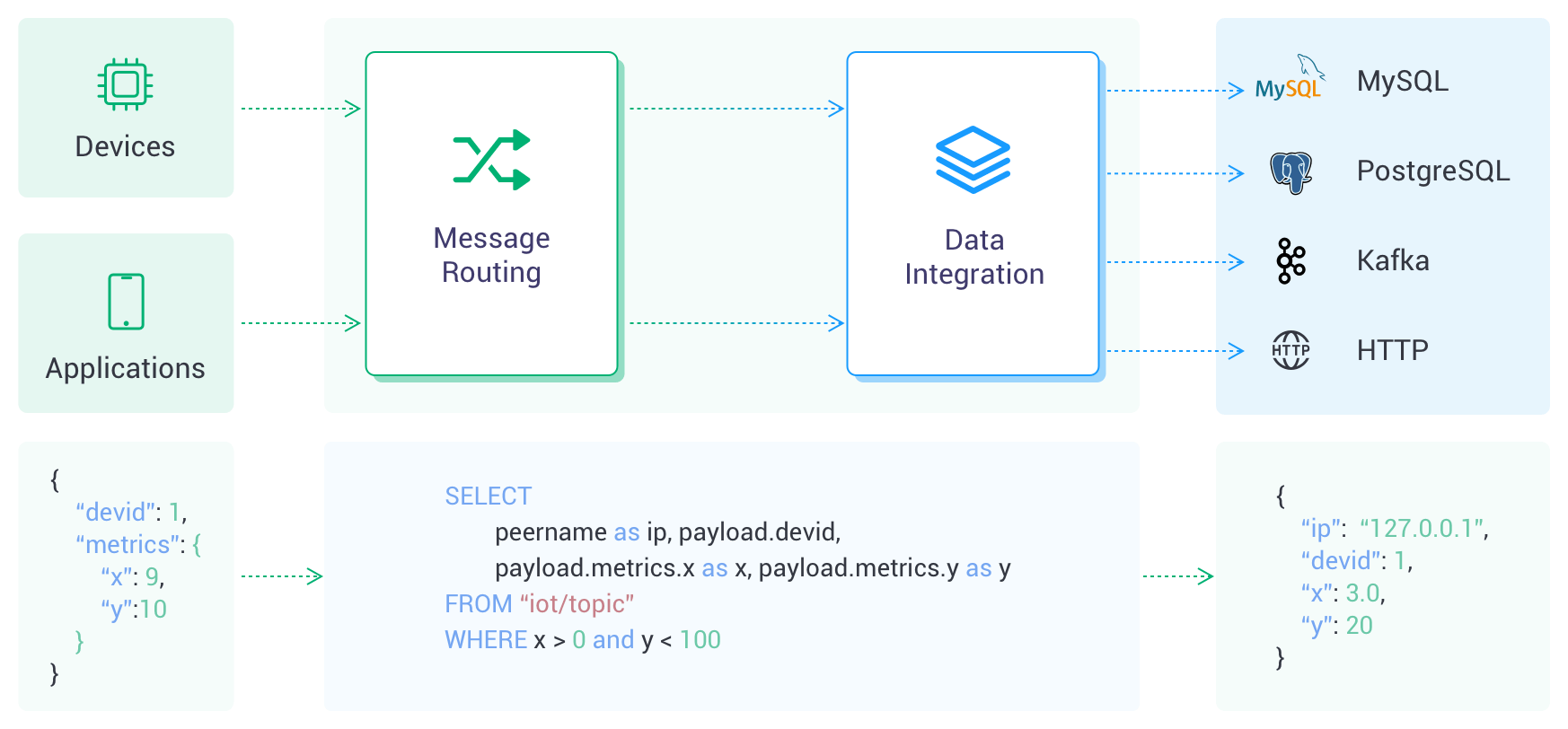
動作原理
デバイスやアプリケーションが接続を確立すると、MQTT ブローカーはメッセージをルーティングします。到着したメッセージは、SQL 文を用いてデータを操作する強力なコンポーネントであるルールエンジンによって処理されます。この処理済みデータは「アクション」によってターゲットのサービスへ転送されます。アクションは「Sink(シンク)」と「Source(ソース)」の2種類に分類され、Sink はデータをサービスに送信し、Source はサービスからデータを受信します。現在、データ統合は Sink モードのみで動作し、さまざまなクラウドサービスへのデータ統合を円滑に行います。
コネクター
コネクターは Sink/Source の基盤となる接続チャネルであり、クラウドプラットフォームから購入したクラウドサービス製品に接続するために使用されます。クラウドサービス製品には、Kafka のようなメッセージキューサービスや RDS のようなストレージサービスがあります。
ルール
ルールは「データの発生元」と「データのフィルタリングおよび処理方法」を記述します。ルールは SQL ライクな文法を使ってカスタムデータを記述でき、SQL テスト機能でエクスポートされるデータをシミュレーションできます。ルール SQL の書き方については、ルール SQL リファレンスをご参照ください。
アクション
アクションは「処理済みデータの送信先」を決定します。1つのルールは複数のアクションに対応可能で、アクションは定義済みのコネクターを設定する必要があり、つまりデータの送信先を指定します。
Sink(シンク)
Sink はルールのアクションに追加されるデータ出力コンポーネントです。デバイスがイベントをトリガーしたり、メッセージが EMQX デプロイメントに到着すると、システムは対応するルールをマッチングして実行し、データをフィルタリングおよび処理します。ルールエンジンで処理されたデータは指定された Sink に転送されます。Sink では、${var} や ${.var} の構文を使ってデータから変数を抽出し、SQL 文やデータテンプレートを動的に生成するなど、データの取り扱い方法を設定できます。その後、対応するコネクターを通じて外部データシステムにデータを送信し、メッセージの保存、データ更新、イベント通知などの操作を実現します。
Sink でサポートされる変数抽出構文は以下の通りです:
${var}:ルールの出力結果から変数を抽出する構文です。例として${topic}があります。ネストされた変数を抽出したい場合はドット.を使い、${payload.temp}のように記述します。抽出したい変数が出力結果に含まれていない場合は、文字列undefinedが返されます。${.var}:まずルールの出力結果から変数を抽出しようとし、存在しない場合は対応するイベントデータから抽出を試みます。例として${.topic}があります。こちらもドット.を使ったネスト変数の抽出が可能で、${.payload.temp}のように記述します。ルールの出力結果とイベントデータの両方に変数が存在しない場合はundefinedが返されます。${.}を使うと、ルールの出力結果とイベントデータからマージされたすべての変数を抽出できます。
Source(ソース)
Source はデータ入力コンポーネントであり、ルールのデータソースとして機能し、ルール SQL で選択されます。
Source は MQTT や Kafka などの外部データシステムからメッセージをサブスクライブまたはコンシュームします。コネクターを通じて新しいメッセージが到着すると、ルールエンジンは対応するルールをマッチングして実行し、データをフィルタリングおよび処理します。処理済みデータは指定された EMQX トピックにパブリッシュされ、クラウドコマンドの配布などの操作を可能にします。
ワークフロー
以下はデータ統合を作成する基本的な流れです:

- コネクターを作成します。デプロイメントのデータ統合初期ページから接続したいサービスを選択し、コネクターを設定します。
- デバイスから収集したデータを処理するルールを作成します。ルールは SQL 文を使って自由にデータを収集・処理できます。
- ルールにアクションを紐付けます。ルールがトリガーされた際、処理済みデータが設定済みのコネクターを通じてクラウドサービスに転送されます。
- 作成したデータ統合が正しく動作するかテストします。
デプロイメントに必要なネットワーク設定
データ統合機能はデプロイメントの種類により、データソースへのアクセスレベルやネットワーク設定が異なります。
サーバレスデプロイメント
データソースはパブリックネットワークアクセスのみサポートします。そのため、データソースを作成する前に、データソースがパブリックネットワークアクセス可能であり、セキュリティグループが開放されていることを確認してください。
Kafka と HTTP サーバーのコネクターのみサポートします。
サーバレスデプロイメントのデータ統合は従量課金制で、以下の通りです:
EMQX サーバレスはユーザーに月間最大100万回のルールアクション実行の無料枠を提供します。これを超えると、追加の100万回あたり0.25ドルの料金が発生します。
最適なパフォーマンスと管理のため、EMQX ブローカーは各デプロイメント内でのコネクター、ルール、アクションの作成に以下の制限を設けています:
カテゴリ 最大許容数 コネクター合計 2 ルール合計 4 ルールごとのアクション数 1
Dedicated Flex デプロイメント
- データソースには内部ネットワーク経由でアクセスすることを推奨します。そのため、作成前に VPC ピアリング を設定し、セキュリティグループを開放してください。
- パブリックネットワーク経由でアクセスする必要がある場合は、NAT ゲートウェイ を有効にできます。
BYOC デプロイメント
注意
BYOC デプロイメントではコンソールからデータ統合の設定はできません。設定には EMQX Management Console をご利用ください。
- ネットワークセキュリティとパフォーマンス向上のため、データソースには内部ネットワーク経由でアクセスすることを推奨します。作成前に、リソースが存在する VPC と BYOC デプロイメントが存在するパブリッククラウドコンソールの VPC 間でピアリング接続を設定し、関連するセキュリティグループを開放してください。詳細は VPC ピアリング接続の作成 をご参照ください。
- パブリックネットワーク経由でリソースにアクセスする必要がある場合は、BYOC デプロイメントが存在する VPC に対してパブリッククラウドコンソールで NAT ゲートウェイを設定してください。