Amazon S3 Tables への MQTT データ取り込み
注意
Amazon S3 Tables のデータ統合は、EMQX バージョン 5.91 以降の Dedicated Flex エディションで利用可能です。
Amazon S3 Tables は、分析ワークロードに最適化された専用ストレージソリューションです。Apache Iceberg フォーマットでの IoT センサーの読み取り値などの表形式データに対し、高性能でスケーラブルかつ安全なストレージを提供します。
EMQX Cloud は Amazon S3 Tables とのシームレスな統合をサポートし、MQTT メッセージを効率的に S3 テーブルバケットに保存できます。この統合により、柔軟でスケーラブルな IoT データストレージが可能となり、Amazon Athena、Amazon Redshift、Amazon EMR などの AWS サービスを用いた高度な分析や処理を促進します。
本ページでは、EMQX Cloud と Amazon S3 Tables 間のデータ統合について詳しく解説し、ルール作成の実践的な手順を紹介します。
動作概要
EMQX Cloud は Amazon S3 Tables と連携し、MQTT データをリアルタイムかつ構造化された形で Amazon S3 に取り込み、長期保存および分析を可能にします。この統合は EMQX Cloud のルールエンジンと S3 Tables アクションを活用し、MQTT メッセージを Apache Iceberg フォーマットのテーブルに変換して S3 テーブルバケットに直接ストリーム配信します。
典型的な IoT シナリオでは:
- EMQX Cloud は MQTT ブローカーとして機能し、デバイスの接続管理、メッセージルーティング、データ処理を担当します。
- Amazon S3 Tables は MQTT メッセージデータを表形式で耐久的かつクエリ可能なストレージとして保存します。
- Amazon Athena は Iceberg テーブルの定義や保存データに対する SQL クエリ実行に使用されます。
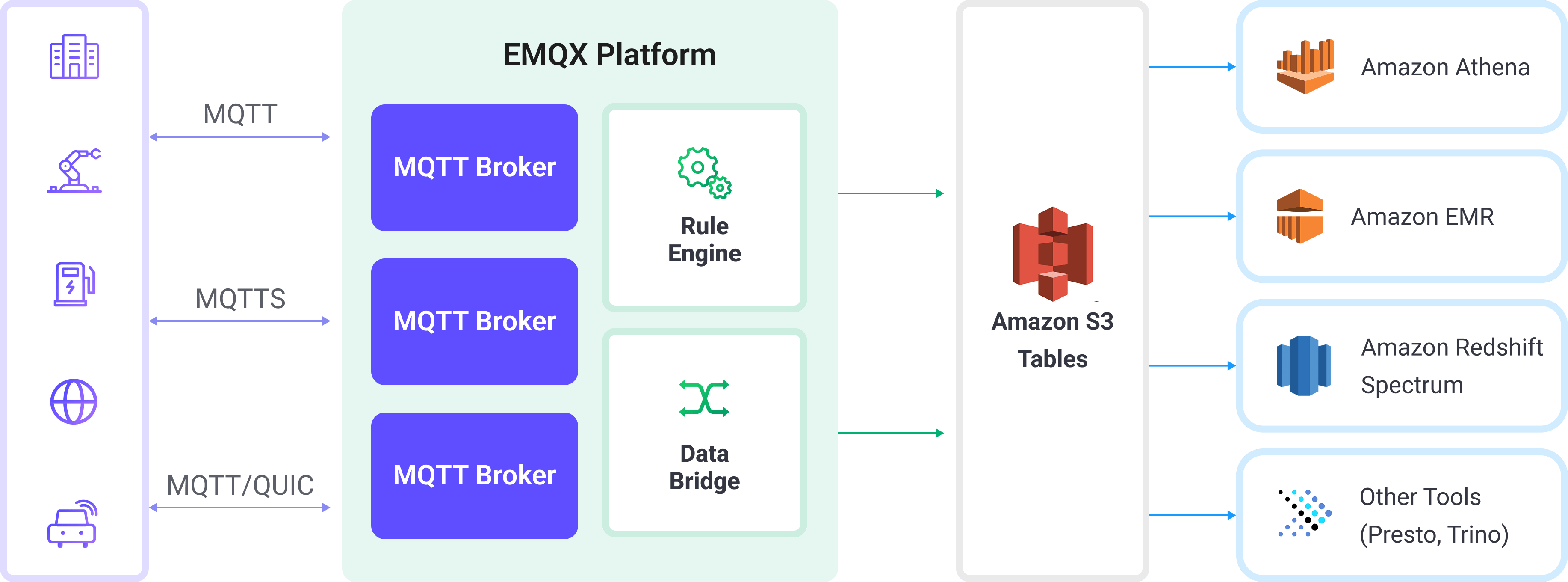
ワークフローは以下の通りです:
- デバイスの EMQX Cloud への接続:IoT デバイスが MQTT 経由で EMQX に接続し、テレメトリデータのパブリッシュを開始します。
- メッセージルーティングとルールマッチング:EMQX は組み込みのルールエンジンで受信した MQTT メッセージを定義済みトピックと照合し、特定のフィールドや値を抽出します。
- データ変換:EMQX のルールでメッセージペイロードをフィルタリング、変換、または拡充し、ターゲットの Iceberg テーブルのスキーマに合わせます。
- Amazon S3 Tables への書き込み:ルールが S3 Tables アクションをトリガーし、変換済みデータをバッチ処理して Iceberg 互換の書き込み API を使い Amazon S3 Tables に送信します。データは Iceberg テーブルのパーティション下に Parquet ファイルとして永続化されます。
- クエリと分析:取り込まれたデータは Amazon Athena でクエリ可能となり、他のデータセットと結合したり、Redshift Spectrum、Amazon EMR、Presto、Trino などのサードパーティ分析エンジンで分析できます。
特長と利点
Amazon S3 Tables データ統合を利用することで、以下の特長と利点が得られます:
- リアルタイムストリーム処理:EMQX Cloud のルールエンジンにより、MQTT メッセージをリアルタイムに抽出・変換・条件付きルーティングし、S3 Tables へ配信可能です。
- S3 上の Iceberg ベースストレージ:メッセージは Apache Iceberg テーブルに書き込まれ、従来のデータベースを不要にしつつ、SQL ライクなアクセスパターンを実現します。
- 分析ツールとの簡単な連携:データが S3 Tables に格納されると、Amazon Athena(SQL)、Amazon EMR、Redshift Spectrum、Presto、Trino、Snowflake などでクエリや分析が可能です。
- 柔軟かつコスト効率の高いストレージ:Amazon S3 は高耐久かつ低コストのオブジェクトストレージを提供し、アーカイブ、コンプライアンス、デバイス生成データの時系列分析に最適です。
はじめる前に
このセクションでは、EMQX Cloud で Amazon S3 Tables 統合を作成するための準備について説明します。
前提条件
進める前に、以下の内容を理解していることを確認してください:
EMQX の概念:
AWS の概念:
AWS S3 Tables が初めての場合、以下の主要用語を確認してください:
- テーブルバケット:S3 Tables で Iceberg ベースのテーブルデータとメタデータを格納するための専用 S3 バケット。
- Amazon Athena:Amazon S3 に保存されたデータに対して直接 SQL クエリを実行できるサーバレスクエリエンジン。DDL ステートメント(例:
CREATE TABLE)を使ってスキーマや構造を定義可能。 - カタログ:Athena のメタデータコンテナで、データベース(ネームスペース)やテーブルを管理。
- データベース(ネームスペース):カタログ内の論理的なテーブルグループ。
- Iceberg テーブル:データレイク向けの高性能かつトランザクショナルなテーブルフォーマット。スキーマ進化、パーティションプルーニング、タイムトラベルクエリをサポート。
ネットワーク設定
EMQX はパブリックネットワーク経由で Amazon S3 にアクセスするため、デプロイメントで NAT ゲートウェイ を有効にする必要があります。トップメニューバーの VAS をクリックし、NAT ゲートウェイカードを選択するか、デプロイメント概要ページの下部タブバーで Enable NAT Gateway service を選択してください。
S3 Tables バケットの準備
MQTT データの送信先となる AWS S3 Tables の準備が必要です。以下を用意してください:
- 実際のデータファイルを保存するテーブルバケット
- 関連テーブルを論理的にグループ化するネームスペース
- 構造化された MQTT データを受け取る Iceberg ベースのテーブル
AWS マネジメントコンソールにログインします。
S3 サービスに移動し、左のナビゲーションペインで Table buckets をクリックします。
Create table bucket をクリックし、テーブルバケット名(例:
mybucket)を入力して Create table bucket をクリックします。バケット作成後、そのバケットをクリックしてテーブル一覧に移動します。
Create table with Athena をクリックします。ポップアップが表示され、ネームスペースの指定を求められます。
Create a namespace を選択し、ネームスペース名を入力して作成を確定します。
ネームスペース作成後、再度 Create table with Athena をクリックして続行します。
Iceberg テーブルのスキーマを定義します:
Query table with Athena をクリックし、Query editor で:
- Catalog セレクターからカタログ(例:バケット名が
mybucketの場合はs3tablescatalog/mybucket)を選択。 - Database セレクターから先ほど作成したネームスペースを選択。
- Catalog セレクターからカタログ(例:バケット名が
以下の DDL を実行し、テーブルタイプが
ICEBERGに設定されていることを確認します。例:sqlCREATE TABLE testtable ( c_str string, c_long int ) TBLPROPERTIES ('table_type' = 'ICEBERG');これは EMQX からの構造化 MQTT データを格納する Iceberg ベースのテーブルを定義します。
テーブルを検証します。テーブルが正常に作成され、空であることを確認するため、以下を実行します:
sqlselect * from testtableTIP
Athena で SQL を実行する前に、正しい Catalog と Database(ネームスペース)が選択されていることを必ず確認してください。これにより、意図した S3 テーブルバケット内にテーブルが作成されます。
Amazon S3 コネクターの作成
S3 Tables ルールを追加する前に、EMQX Cloud が S3 Tables にデータを送信できるように対応するコネクターを作成する必要があります。
デプロイメントに移動し、左ナビゲーションメニューから Data Integration をクリックします。
初めてコネクターを作成する場合は、Data Persistence カテゴリの下にある S3 Tables を選択します。既にコネクターを作成済みの場合は、New Connector を選択し、続いて Data Persistence カテゴリの S3 Tables を選択します。
New Connector ページで以下を設定します:
- Connector Name:システムが自動的にコネクター名を生成します。
- S3Tables ARN:AWS コンソールの Table buckets セクションで確認できる S3 テーブルバケットの Amazon リソースネーム(ARN)を入力します。
- Access Key ID と Secret Access Key:S3 Tables と Athena へのアクセス権限を持つ IAM ユーザーまたはロールの AWS アクセス認証情報を入力します。
- Enable TLS:S3 Tables への接続時に TLS を有効または無効にします。TLS 接続オプションの詳細は TLS for External Resource Access を参照してください。
- Health Check Timeout:コネクターが S3 Tables との接続の自動ヘルスチェックを行う際のタイムアウト時間を指定します。
その他の設定はデフォルト値のままにします。
New をクリックする前に、Test ボタンでコネクターが S3 Tables サーバーに接続できるかをテストできます。
ページ下部の New ボタンをクリックしてコネクターの作成を完了します。
これでコネクターの作成が完了し、次に S3 Tables サービスに書き込むデータを指定するアクション付きのルール作成に進みます。
ルールの作成
このセクションでは、ソース MQTT トピック t/# からのメッセージを処理し、処理結果を設定した S3 Tables の mybucket バケットに書き込むルールの作成方法を示します。
ルールエリアで New Rule をクリックするか、作成したコネクターの Actions 列にある新規ルールアイコンをクリックします。
SQL Editor に以下のルール SQL を入力します:
TIP
出力フィールドが Iceberg テーブルで定義したスキーマと一致していることを必ず確認してください。必須カラムが欠落または名前が異なる場合、データのテーブルへの追加に失敗する可能性があります。
sqlSELECT payload.str as c_str, payload.int as c_long FROM "t/#"TIP
SQL に不慣れな場合は、SQL Examples や Enable Debug をクリックしてルール SQL の結果を学習・テストできます。
Next をクリックしてアクションを追加します。
Connector ドロップダウンから先ほど作成したコネクターを選択します。
アクション設定を行います:
- Namespace:テーブルが存在するネームスペース。複数セグメントの場合はドット区切りで指定(例:
my.name.space)。 - Table:データを追加する Iceberg テーブル名(例:
testtable)。 - Max Records:S3 へ書き込む前にバッチする最大レコード数。上限に達すると即時フラッシュされアップロードされます。
- Time Interval:Max Records に達していなくても、指定した時間(ミリ秒)経過後にデータをフラッシュする最大待機時間。
- Namespace:テーブルが存在するネームスペース。複数セグメントの場合はドット区切りで指定(例:
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義可能です。詳細は Fallback Actions を参照してください。
Advanced Settings を展開し、必要に応じて詳細設定を行います(任意)。
Confirm ボタンをクリックしてルール設定を完了します。
Successful new rule ポップアップで Back to Rules をクリックし、データ統合設定の一連の作業を完了します。
ルールのテスト
このセクションでは、S3 Tables アクションを設定したルールのテスト方法を説明します。
MQTTX を使ってトピック
t/1にメッセージをパブリッシュします:bashmqttx pub -i emqx_c -t t/1 -m '{ "str": "hello S3 Tables", "int": 123 }'このメッセージは、ルール SQL と先に定義したテーブルスキーマに対応する
payload.strとpayload.intフィールドを含みます。Rules ページでルールのメトリクスとアクションのステータスを監視します。新規の受信メッセージと送信メッセージがそれぞれ 1 件ずつあるはずです。
Athena クエリエディターを開き、正しい Catalog(例:
s3tablescatalog/mybucket)と Database(ネームスペース)が選択されていることを確認します。以下の SQL クエリを実行します:
sqlSELECT * FROM testtable以下のような行が表示されるはずです:
c_str c_long hello S3 Tables 123