Apache KafkaへのMQTTデータストリーミング
Apache Kafka は、アプリケーションやシステム間のリアルタイムデータフローを処理できる広く利用されているオープンソースの分散イベントストリーミングプラットフォームです。しかし、KafkaはエッジIoT通信向けに設計されておらず、Kafkaクライアントは安定したネットワーク接続とより多くのハードウェアリソースを必要とします。IoT分野では、デバイスやアプリケーションが生成するデータは軽量なMQTTプロトコルを用いて送信されます。EMQX CloudとKafka/Confluentの統合により、ユーザーはMQTTデータをシームレスにKafkaへストリーミングできます。MQTTデータストリームはKafkaのトピックに導入され、リアルタイムの処理、保存、分析が可能となります。現在、EMQX CloudはKafkaへのデータ転送のみをサポートしています。
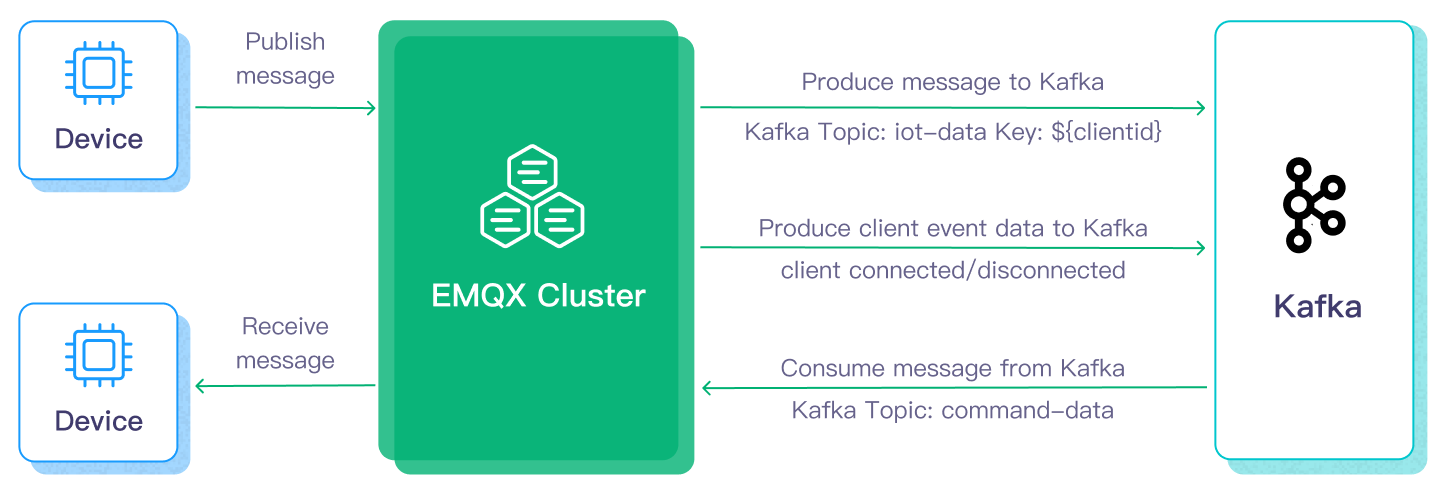
本ページでは、Kafkaデータ統合の機能的特徴を詳述し、データ統合の作成手順について実践的なガイダンスを提供します。
動作概要
Apache Kafkaデータ統合はEMQX Cloudに標準搭載された機能であり、MQTTベースのIoTデータとKafkaの強力なデータ処理機能を橋渡しします。組み込みのルールエンジンコンポーネントを通じて、複雑なコーディングなしに両プラットフォーム間のデータフローと処理を簡素化します。
Kafkaへのメッセージデータ転送の基本的なワークフローは以下の通りです:
- メッセージパブリッシュ:デバイスはMQTTプロトコルを介してEMQX Cloudデプロイメントに正常に接続し、定期的に状態データを含むメッセージをパブリッシュします。EMQX Cloudはこれらのメッセージを受信すると、ルールエンジン内でマッチング処理を開始します。
- メッセージデータ処理:これらのMQTTメッセージは、組み込みのルールエンジンを通じてトピックマッチングルールに基づき処理されます。メッセージが到着しルールエンジンを通過すると、エンジンはそのメッセージに対して事前定義された処理ルールを評価します。ペイロード変換を指定するルールがあれば、データ形式変換、特定情報のフィルタリング、追加コンテキストによるペイロードの強化などの変換が適用されます。
- Kafkaへの送信:ルールエンジンで定義されたルールがKafkaへのメッセージ転送アクションをトリガーします。Kafkaデータ統合を利用し、MQTTトピックは事前定義されたKafkaトピックにマッピングされ、すべての処理済みメッセージとデータがKafkaトピックに書き込まれます。
Kafkaからのメッセージ消費の基本的なワークフローは以下の通りです:
- Kafkaトピックのサブスクライブ:ルールエンジンの入力ソースでKafkaコンシューマのアクションを定義し、消費するKafkaトピック名を設定します。EMQXデプロイメントはこれらのメッセージを受信すると、ルールエンジン内でマッチング処理を開始します。
- メッセージデータ処理:組み込みのルールエンジンを通じて、メッセージが到着しルールエンジンを通過すると、ルールエンジンはそのメッセージに対して事前定義された処理ルールを評価します。ペイロード変換を指定するルールがあれば、データ形式変換、特定情報のフィルタリング、追加コンテキストによるペイロードの強化などの変換が適用されます。
- MQTTクライアントへの転送:ルールエンジンで定義されたルールがMQTTトピックへのメッセージ転送アクションをトリガーします。Kafkaデータ統合を利用し、Kafkaトピックは事前定義されたMQTTトピックにマッピングされ、すべての処理済みメッセージとデータがMQTTクライアントによって消費可能となります。
特徴と利点
Apache Kafkaとのデータ統合は、以下の特徴と利点をビジネスにもたらします:
- ペイロード変換:転送中にメッセージペイロードを定義されたSQLルールで処理可能です。例えば、総メッセージ数、成功/失敗配信数、メッセージレートなどのリアルタイム指標を含むペイロードは、Kafkaに入力される前にデータ抽出、フィルタリング、強化、変換が行えます。
- 効果的なトピックマッピング:設定されたKafkaデータ統合を通じて、多数のIoTビジネストピックをKafkaトピックにマッピング可能です。EMQXはMQTTユーザープロパティをKafkaヘッダーにマッピングすることをサポートし、1対1、1対多、多対多、MQTTトピックフィルター(ワイルドカード)対応など多様なトピックマッピング手法を採用しています。
- 柔軟なパーティション選択戦略:MQTTトピックやクライアントに基づいてメッセージを同一Kafkaパーティションに転送することをサポートします。
- 高スループット下での処理能力:EMQX Kafkaプロデューサーは同期/非同期書き込みモードをサポートし、リアルタイム優先と性能優先のデータ書き込み戦略を柔軟に選択可能です。
- ランタイムメトリクス:各データブリッジの総メッセージ数、成功/失敗数、現在のレートなどのランタイムメトリクスの閲覧をサポートします。
これらの特徴は統合能力と柔軟性を高め、効果的かつ堅牢なIoTプラットフォームアーキテクチャの構築を支援します。増大するIoTデータは安定したネットワーク接続のもとで送信され、さらに効果的に保存・管理されます。
はじめる前に
本節では、EMQX CloudでKafkaデータ統合を作成するための準備作業を紹介します。
前提条件
ネットワーク設定
データ統合を構成する前に、EMQX Cloudのデプロイメントを作成し、EMQX Cloudと対象サービス間のネットワーク接続を確立していることを確認してください。
Dedicated Flexデプロイメントの場合:
EMQX CloudのVPCと対象サービスのVPC間でVPCピアリング接続を作成します。ピアリング接続が確立されると、EMQX Cloudは対象サービスのプライベートIPアドレスを介してアクセス可能になります。
パブリックIP経由でのアクセスが必要な場合は、NATゲートウェイを構成してアウトバウンド接続を有効にしてください。
BYOC(Bring Your Own Cloud)デプロイメントの場合:
BYOCデプロイメントが稼働しているVPCと対象サービスをホストするVPC間でVPCピアリング接続を作成します。ピアリングが確立されると、対象サービスのプライベートIPアドレスを介してアクセス可能になります。
対象サービスにパブリックIP経由でアクセスする必要がある場合は、クラウドプロバイダーのコンソールを使用してBYOC VPCにNATゲートウェイを構成してください。
Kafkaのインストールとトピック作成
Kafkaをインストールします。
bash# Zookeeperのインストール docker run -d --restart=always \ --name zookeeper \ -p 2181:2181 \ zookeeper # Kafkaのインストール(ポート9092を開放) docker run -d --restart=always --name mykafka \ -p 9092:9092 \ -e HOST_IP=localhost \ -e KAFKA_ADVERTISED_PORT=9092 \ -e KAFKA_ADVERTISED_HOST_NAME=<Server IP> \ -e KAFKA_BROKER_ID=1 \ -e KAFKA_LOG_RETENTION_HOURS=12 \ -e KAFKA_LOG_FLUSH_INTERVAL_MESSAGES=100000 \ -e KAFKA_ZOOKEEPER_CONNECT=<Server IP>:2181 \ -e ZK=<Server IP> \ wurstmeister/kafkaトピックを作成します。
bash# Kafkaインスタンスに入り、emqxトピックを作成 $ docker exec -it mykafka /opt/kafka/bin/kafka-topics.sh --zookeeper <broker IP>:2181 --replication-factor 1 --partitions 1 --topic emqx --create
"Created topic emqx." と表示されれば作成成功です。
メッセージデータをKafkaへストリーミング
本節では、MQTTプロトコルを介して温度・湿度のシミュレーションデータをEMQXデプロイメントに報告し、設定済みのデータ統合を通じてKafkaに転送する方法を示します。内容はKafkaプロデューサーコネクターの作成、ルールの作成、ルールのテストを含みます。
Kafkaプロデューサーコネクターの作成
データ統合ルールを作成する前に、まずKafkaサーバーにアクセスするためのKafkaプロデューサーコネクターを作成します。
- デプロイメントにアクセスし、左ナビゲーションメニューから データ統合 をクリックします。
- 初めてコネクターを作成する場合は、データ転送 カテゴリの中から Kafka Producer を選択します。すでにコネクターを作成済みの場合は、新規コネクター を選択し、続いて データ転送 カテゴリの中から Kafka Producer を選択します。
- 新規コネクター ページで以下のオプションを設定します:
- コネクター名:システムが自動的にコネクター名を生成しますが、自分で命名することも可能です。本例では
my_kafkaserverを使用できます。 - Bootstrap Hosts:ホストリストを入力し、Kafkaサービスにネットワーク経由で正常にアクセスできることを確認します。
- その他の設定はデフォルト値を使用するか、ビジネスニーズに応じて設定してください。
- コネクター名:システムが自動的にコネクター名を生成しますが、自分で命名することも可能です。本例では
- テスト ボタンをクリックします。Kafkaサービスにアクセス可能であれば成功メッセージが返されます。
- 新規作成 ボタンをクリックして作成を完了します。
ルールの作成
次に、書き込むデータを指定し、処理済みデータをKafkaに転送するアクションをルールに追加するためのルールを作成します。
ルールエリアの 新規ルール をクリックするか、作成したコネクターの アクション 列の新規ルールアイコンをクリックします。
SQLエディター にルールマッチング用のSQL文を入力します。以下のSQL例は、
temp_hum/emqxトピックに送信されたメッセージから報告時間timestamp、クライアントID、メッセージ本文(ペイロード)を読み取り、温度と湿度を抽出します。sqlSELECT timestamp, clientid, payload.temp as temp, payload.hum as hum FROM "temp_hum/emqx"Try It Out 機能でデータ入力をシミュレーションし、結果をテストできます。
次へ をクリックしてアクションを追加します。
コネクター ドロップダウンから先ほど作成したコネクターを選択します。
以下の情報を設定します:
アクション名:システムが自動生成しますが、任意で命名可能です。
Kafkaトピック名:先に作成したトピック
emqxを入力します。Kafkaヘッダー:ビジネスニーズに応じてKafkaヘッダーを定義します。
メッセージ本文設定では、メッセージキー はルールから取得したクライアントIDがデフォルトですが、必要に応じて変更可能です。メッセージ値 には転送する温度・湿度の値を入力します。
bash# Kafkaメッセージ値 {"temp": ${temp}, "hum": ${hum}}その他の設定はデフォルト値を使用するか、ビジネスニーズに応じて設定してください。
確認 ボタンをクリックしてルール作成を完了します。
新規ルール成功 ポップアップで ルールに戻る をクリックし、データ統合の設定チェーンを完了します。
作成成功後は新規ルールページに戻り、ルール リストに新規作成したルールが表示されます。アクション(シンク) リストにはデータ取り込みアクションの一覧が表示されます。
ルールのテスト
MQTTX を利用して温度・湿度データの報告をシミュレーションすることを推奨しますが、他のクライアントでも可能です。
MQTTXでデプロイメントに接続し、以下のトピックにメッセージを送信します。
トピック:
temp_hum/emqxペイロード:
json{ "temp": "27.5", "hum": "41.8" }
メッセージがKafkaに転送されているか確認します。
bash# Kafkaインスタンスに入り、emqxトピックを確認 $ docker exec -it mykafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server <broker IP>:9092 --topic emqx --from-beginningコンソールで運用データを確認します。ルールリストのルールIDをクリックすると、そのルールの統計情報およびすべてのアクションの統計が表示されます。
Kafkaからのメッセージ消費
本節では、EMQXデプロイメントがKafkaからメッセージを消費し、メッセージデータをMQTTトピックに再パブリッシュする方法を示します。内容はKafkaコンシューマーコネクターの作成、ルールの作成、ルールのテストを含みます。
Kafkaコンシューマーコネクターの作成
Kafkaコンシューマーを追加する前に、EMQXデプロイメントとKafka間の接続を確立するためのKafkaコンシューマーコネクターを作成します。
- デプロイメントメニューで データ統合 を選択し、データ取り込み サービスカテゴリの中から Kafka Consumer を選択します。すでに他のコネクターを作成済みの場合は、新規コネクター作成 をクリックし、続いて データ取り込み カテゴリの中から Kafka Consumer を選択します。
- コネクター作成ページで以下を設定します:
- コネクター名:システムが自動的に
connector-で始まる名前を生成します。 - ホストリスト:Kafkaサービスにネットワーク経由で正常にアクセスできるホストリストを入力します。
- 認証:必要に応じて認証方式を入力します。ここではBasic認証を使用します。
- 認証方式:Kafkaサービスの認証要件に応じて
plain、SHA256、SHA512から選択します。 - ユーザー名:Kafkaサービスのユーザー名(通常はAPIキー)。
- パスワード:Kafkaサービスの認証パスワード(通常はAPIシークレット)。
- 認証方式:Kafkaサービスの認証要件に応じて
- その他の設定はデフォルト値を使用するか、ビジネスニーズに応じて設定してください。
- コネクター名:システムが自動的に
- 接続テスト ボタンをクリックし、Kafkaサービスに正常にアクセスできる場合は成功メッセージが返されます。
- 作成 ボタンをクリックして設定を完了します。
ルールの作成
次に、入力データとルールエンジン処理ルールを指定し、ルールで処理したデータを対応するトピックに転送する出力アクションを追加するルールを作成します。
コネクターリストの アクション 列の新規ルールアイコンをクリックするか、ルール リスト上部の 新規ルール をクリックして 新規ルール ステップページに入ります。
コンシューマールールでは、まず入力アクションを設定する必要があります。ルール編集ページで自動的に入力アクション設定がポップアップするか、アクション(ソース) -> 新規アクション(ソース) を選択し、パネルで Kafka Consumer を選択して 次へ をクリックします。
- Kafkaコンシューマーコネクターを選択します。
- Kafkaトピック:Kafkaから消費するトピック名を入力します。例:
temp_hum/emqx。 - グループID:このソースのコンシューマーグループ識別子を指定します。空欄の場合はソース名に基づくグループIDが自動生成されます。英数字、アンダースコア、ドット、ハイフンのみ使用可能です。
- キーエンコーディングモード と 値エンコーディングモード:Kafkaメッセージのキーと値のエンコーディングモードを選択します。
- オフセットリセットポリシー:コンシューマーがKafkaトピックパーティションの読み取りを開始する際のオフセットリセット戦略を選択します。コンシューマーオフセットが存在しないか無効な場合に適用されます。
- 最新のオフセットから読み始め、開始前のメッセージをスキップしたい場合は
latestを選択。 - パーティションの先頭から読み始め、開始前のメッセージも含めてすべての履歴データを読みたい場合は
earliestを選択。
- 最新のオフセットから読み始め、開始前のメッセージをスキップしたい場合は
確認 ボタンをクリックして設定を完了します。
SQLエディターはデータソースフィールドを更新し、
SELECTで転送するフィールドを選択できます。sqlSELECT key as key, value as value, topic as topic FROM "$bridges/kafka_consumer:source-812985f2"次へ をクリックし、出力アクションを作成します。
新規出力アクションで 再パブリッシュ を選択します。
出力アクション情報を設定します:
- トピック:転送先のMQTTトピック。
${var}形式のプレースホルダーをサポートします。ここではsub/${topic}と入力し、元のトピックにsub/プレフィックスを付加して転送します。例えば、元のメッセージトピックがt/1の場合、転送先はsub/t/1となります。 - QoS:メッセージパブリッシュのQoS。
0、1、2または${qos}から選択、他のフィールドからQoSを設定するためのプレースホルダーも入力可能です。ここでは元メッセージのQoSに従う${qos}を選択します。 - 保持フラグ(Retain):
true、false、${flags.retain}から選択し、メッセージを保持メッセージとしてパブリッシュするかどうかを指定します。他のフィールドから保持フラグを設定するプレースホルダーも使用可能です。ここでは元メッセージの保持フラグに従う${flags.retain}を選択します。 - メッセージテンプレート:転送するメッセージペイロードの生成テンプレート。デフォルトは空欄でルール出力結果を転送します。ここでは
${.}と入力し、ルールエンジンのすべてのフィールドを転送します。
- トピック:転送先のMQTTトピック。
その他の設定はデフォルトのままにし、確認 ボタンをクリックして出力アクションの作成を完了します。
作成成功後は新規ルールページに戻り、ルール リストに新規作成したルールが表示されます。再パブリッシュアクションは現在 アクション(ソース) には表示されません。必要に応じてルール編集ボタンをクリックすると、ルール設定の下部に再パブリッシュ出力アクションが確認できます。
ルールのテスト
Kafkaトピック temp_hum/emqx にメッセージを送信し、デプロイメント内の転送先トピックをサブスクライブしてルールをテストできます。temp_hum/emqx トピックにメッセージがパブリッシュされると、デプロイメント内の sub/temp_hum/emqx トピックに転送されます。
以下の手順は、MQTTX を使用して転送されたMQTTトピックをサブスクライブしメッセージを受信する方法を示します。
MQTTXで現在のデプロイメントのトピック
sub/#をサブスクライブします。Kafkaプロデューサーや他のツールを使って
temp_hum/emqxトピックにメッセージをパブリッシュします:json{ "temp": 55, "hum": 32 }MQTTXは現在のデプロイメント内の
sub/temp_hum/emqxトピックでメッセージを受信します:json{ "key": "", "value": { "temp": 55, "hum": 32 } }