InfluxDBへのMQTTデータ取り込み
InfluxDBは時系列データの保存と解析に特化したデータベースです。高いデータスループット性能と安定した動作により、IoT分野での活用に非常に適しています。EMQX Cloudは現在、InfluxDB Cloud、InfluxDB OSS、InfluxDB Enterpriseの主流バージョンとの接続をサポートしています。
本ページでは、EMQX CloudとInfluxDB間のデータ統合について、実践的な手順を交えて包括的に解説します。
動作概要
InfluxDBデータ統合はEMQX Cloudに標準搭載された機能であり、EMQX Cloudのリアルタイムデータキャプチャ・転送機能とInfluxDBのデータ保存・解析機能を組み合わせています。組み込みのルールエンジンコンポーネントにより、EMQX CloudからInfluxDBへのデータ取り込みを簡素化し、複雑なコーディングを不要にします。EMQX CloudはルールエンジンとSinkを介してデバイスデータをInfluxDBに転送し保存・解析します。InfluxDBは解析結果をレポートやグラフとして生成し、InfluxDBの可視化ツールを通じてユーザーに提供します。
以下の図は、エネルギー貯蔵シナリオにおけるEMQXとInfluxDBの典型的なデータ統合アーキテクチャを示しています。
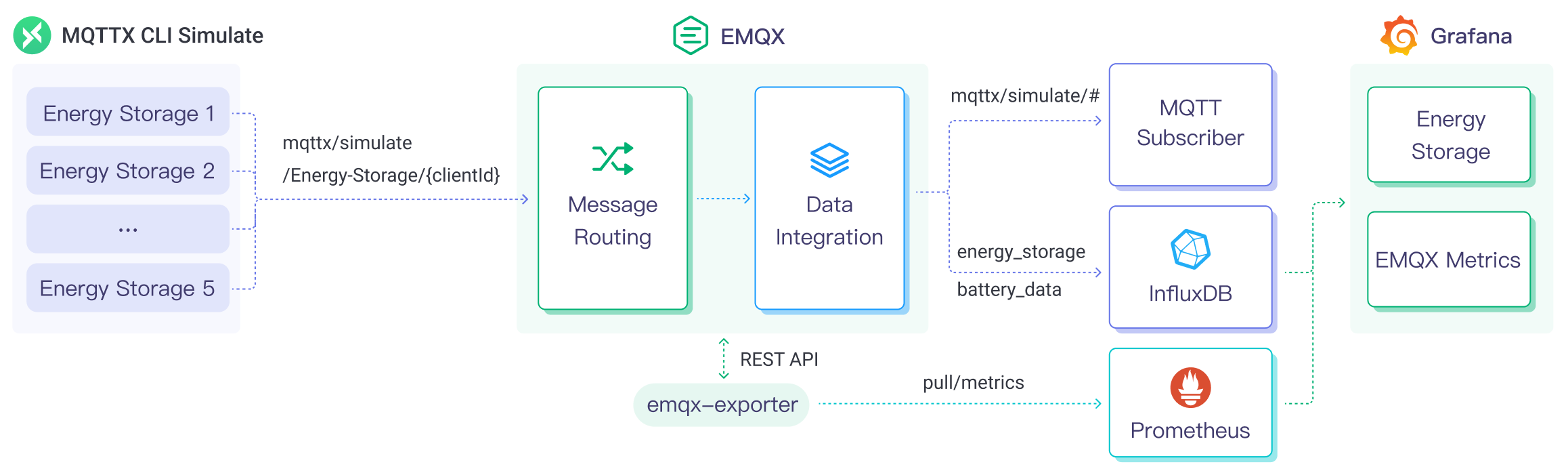
EMQX CloudとInfluxDBは、エネルギー消費データをリアルタイムに効率的に収集・解析するための拡張可能なIoTプラットフォームを提供します。このアーキテクチャでは、EMQX Cloudがデバイス接続、メッセージ送受信、データルーティングを担当するIoTプラットフォームとして機能し、InfluxDBがデータ保存・解析プラットフォームとして機能します。ワークフローは以下の通りです。
- メッセージのパブリッシュと受信:エネルギー貯蔵デバイスや産業用IoTデバイスはMQTTプロトコルを通じてEMQX Cloudに接続し、電力消費量、入出力電力などのエネルギー消費データを定期的にパブリッシュします。EMQX Cloudはこれらのメッセージを受信すると、ルールエンジン内でマッチング処理を開始します。
- メッセージデータの処理:組み込みのルールエンジンを用いて、特定のトピックに基づくメッセージを処理します。メッセージが到着するとルールエンジンを通過し、対応するルールとマッチングしてデータ形式の変換、特定情報のフィルタリング、コンテキスト情報の付加などの処理を行います。
- InfluxDBへのデータ取り込み:ルールエンジンで定義されたルールがトリガーとなり、InfluxDBへの書き込み操作が実行されます。InfluxDB SinkはLine Protocolのテンプレートを提供し、メッセージの特定フィールドをInfluxDBの測定値やフィールドに柔軟にマッピングできます。
エネルギー消費データがInfluxDBに書き込まれた後は、Line Protocolを活用してデータ解析が可能です。例えば:
- Grafanaなどの可視化ツールに接続し、エネルギー貯蔵データを基にしたグラフを生成する。
- 業務システムに接続し、エネルギー貯蔵デバイスの状態監視やアラート通知を行う。
特長と利点
InfluxDBデータ統合は以下の特長と利点を提供します。
- 効率的なデータ処理:EMQX Cloudは大量のIoTデバイス接続とメッセージスループットを処理可能であり、InfluxDBはデータ書き込み・保存・クエリに優れた性能を発揮し、IoTシナリオのデータ処理ニーズをシステム負荷を抑えて満たします。
- メッセージ変換:EMQX Cloudのルールを通じてメッセージを高度に処理・変換した上でInfluxDBに書き込み可能です。
- スケーラビリティ:EMQX CloudとInfluxDBはどちらもクラスター拡張に対応し、ビジネスの成長に応じて柔軟に水平拡張できます。
- 豊富なクエリ機能:InfluxDBは最適化された関数、演算子、インデックス技術を備え、時系列データの効率的なクエリと解析を可能にし、IoTデータから価値ある洞察を正確に抽出します。
- 効率的なストレージ:InfluxDBは高圧縮率のエンコード方式を採用し、ストレージコストを大幅に削減します。また、データ種別ごとに保存期間をカスタマイズでき、不必要なデータのストレージ占有を防止します。
はじめる前に
本セクションでは、EMQX CloudでInfluxDBデータ統合を作成するための準備作業を紹介します。
前提条件
- InfluxDB line protocolの知識
- ルールの理解
- データ統合の理解
ネットワーク設定
データ統合を構成する前に、EMQX Cloudのデプロイメントを作成し、EMQX Cloudと対象サービス間のネットワーク接続を確立していることを確認してください。
Dedicated Flexデプロイメントの場合:
EMQX CloudのVPCと対象サービスのVPC間でVPCピアリング接続を作成します。ピアリング接続が確立されると、EMQX Cloudは対象サービスのプライベートIPアドレスを介してアクセス可能になります。
パブリックIP経由でのアクセスが必要な場合は、NATゲートウェイを構成してアウトバウンド接続を有効にしてください。
BYOC(Bring Your Own Cloud)デプロイメントの場合:
BYOCデプロイメントが稼働しているVPCと対象サービスをホストするVPC間でVPCピアリング接続を作成します。ピアリングが確立されると、対象サービスのプライベートIPアドレスを介してアクセス可能になります。
対象サービスにパブリックIP経由でアクセスする必要がある場合は、クラウドプロバイダーのコンソールを使用してBYOC VPCにNATゲートウェイを構成してください。
InfluxDBのインストールと設定
DockerによるInfluxDBのインストール
- Dockerを使ってInfluxDBをインストールし、Dockerイメージを起動します。
# InfluxDBのDockerイメージを起動する
docker run --name influxdb -p 8086:8086 influxdb:2.5.1InfluxDBが起動したら、ポート8086のサーバーアドレスにアクセスし、ユーザー名、パスワード、組織名、バケット名を設定します。
InfluxDBのUIで、Load Data -> API Tokenをクリックし、全権限トークンの作成の手順に従います。
InfluxDB Cloudでのサービス作成
InfluxDB Cloudにログインします。
InfluxDBのUIで、ユーザー名、パスワード、組織名、バケット名を設定します。
Load Data -> API Tokenをクリックし、全権限トークンの作成の手順に従います。
InfluxDBコネクターの作成
データ統合ルールを作成する前に、InfluxDBサーバーにアクセスするためのコネクターを作成する必要があります。
デプロイメントに移動し、左側ナビゲーションメニューからデータ統合をクリックします。
初めてコネクターを作成する場合は、データ転送カテゴリの中からInfluxDBを選択します。すでにコネクターを作成済みの場合は、新規コネクターを選択し、続いてデータ転送カテゴリの中からInfluxDBを選択します。
コネクター名はシステムが自動生成します。
接続情報を入力します:
- 必要に応じてInfluxDBのバージョンを選択します。サポートされているバージョンは
V1、V2(デフォルト)、V3です。 - サーバーホスト:サーバーのIPアドレスとポート。InfluxDB Cloudを使用する場合はポート443を指定し、
{url}:443と入力してTLSを有効化をクリックしTLS接続を有効にします。 - InfluxDBのインストールと設定に従い、トークン、組織、バケットを設定します。注意:InfluxDB v1を選択した場合は、データベース、ユーザー名、パスワードの設定も完了してください。
- 必要に応じてInfluxDBのバージョンを選択します。サポートされているバージョンは
テストボタンをクリックし、InfluxDBサービスにアクセスできることを確認します。
新規作成ボタンをクリックして作成を完了します。
ルールの作成
次に、書き込むデータを指定し、処理したデータをInfluxDBに転送するためのアクションを追加するルールを作成します。
ルールエリアで新規ルールをクリックするか、作成したコネクターのアクション列にある新規ルールアイコンをクリックします。
使用する機能に基づいてSQLエディターでルールを設定します。ここでは、クライアントが
temp_hum/emqxトピックに温湿度メッセージを送信した際にエンジンをトリガーするSQL例を示します。sqlSELECT timestamp, payload.location as location, payload.temp as temp, payload.hum as hum FROM "temp_hum/emqx"TIP
初心者の方はSQL例をクリックし、試してみるでSQLルールを学習・テストできます。
次へをクリックしてアクションを追加します。
コネクターのドロップダウンから先ほど作成したコネクターを選択します。
時間精度を指定します。デフォルトは
millisecondです。データフォーマットを
JSONまたはLine Protocolから選択し、InfluxDBへのデータ解析・書き込み方法を指定します。JSONフォーマットの場合、Measurement、Timestamp、Fields、Tagsのデータ解析方法を定義します。すべてのキー値は変数やプレースホルダーにできます。また、InfluxDB line protocolに従って設定可能です。FieldsはCSVファイルのインポートによる一括設定もサポートします。詳細は一括設定を参照してください。
Line Protocolフォーマットの場合、測定値、タグセット、フィールドセット、タイムスタンプをテキスト形式で指定し、プレースホルダーも利用可能です。詳細はInfluxDB 2.3 Line ProtocolおよびInfluxDB 1.8 Line Protocolを参照してください。
例:
bashtemp_hum,location=${location} temp=${temp},hum=${hum} ${timestamp}TIP
- InfluxDB 1.xまたは2.xに符号付き整数型の値を書き込む場合、プレースホルダーの後に
iを付けます。例:${payload.int}i。詳細はInfluxDB 1.8 整数値の書き込みを参照してください。 - 符号なし整数型の値を書き込む場合は
uを付けます。例:${payload.int}u。詳細は同上。
- InfluxDB 1.xまたは2.xに符号付き整数型の値を書き込む場合、プレースホルダーの後に
高度な設定(任意):高度な設定を参照してください。
確認ボタンをクリックしてルール作成を完了します。
新規ルール作成成功のポップアップでルールに戻るをクリックし、データ統合設定の一連の流れを完了します。
一括設定
InfluxDBのデータエントリーは数百のフィールドを含むことが多く、データフォーマットの設定は複雑になりがちです。これを解決するため、EMQX Cloudはフィールドの一括設定機能を提供しています。
JSONフォーマットでデータ形式を設定する際、CSVファイルからフィールドのキー・バリューを一括インポートできます。
Fieldsテーブルのインポートボタンをクリックし、一括設定インポートポップアップを開きます。
指示に従い、一括設定テンプレートファイルをダウンロードし、テンプレートにフィールドのキー・バリューを入力します。テンプレートのデフォルト内容は以下の通りです。
フィールド 値 備考(任意) temp ${payload.temp} hum ${payload.hum} precip ${payload.precip}i フィールド値の末尾に iを付け、InfluxDBに整数として保存する- フィールド:フィールドキー。定数または
${var}形式のプレースホルダーをサポート。 - 値:フィールド値。定数またはプレースホルダーをサポートし、Line Protocolに従い型識別子を付加可能。
- 備考:CSVファイル内の注釈用であり、EMQXにはインポートされません。
CSVファイルの一括設定データは2048行を超えないようにしてください。
- フィールド:フィールドキー。定数または
入力済みテンプレートファイルを保存し、一括設定インポートポップアップにアップロードしてインポートをクリックし、一括設定を完了します。
インポート後、Fields設定テーブルでキー・バリューをさらに調整可能です。
ルールのテスト
温湿度データの送信をシミュレートする際は、MQTTXの使用を推奨しますが、他の任意のクライアントでも構いません。
MQTTXでデプロイメントに接続し、以下のトピックにメッセージを送信します。
トピック:
temp_hum/emqxペイロード:
json{ "temp": 27.5, "hum": 41.8, "location": "Prague" }
InfluxDBのUIで、Data Explorerウィンドウを使い、メッセージがInfluxDBに書き込まれているか確認します。
InfluxDB V1を使用している場合は、InfluxDBコンテナに入り、データを確認します。
bash$ docker exec -it influxdb influx $ use dbbash> select * from "temp_hum" name: temp_hum time hum location temp ---- --- -------- ---- 1711093437420000000 41.8 Prague 27.5 >コンソールで運用データを確認します。ルール一覧でルールIDをクリックすると、ルールの統計情報およびそのルールに紐づくすべてのアクションの統計情報が表示されます。