Ingest MQTT Data into InfluxDB
InfluxDB is a database for storing and analyzing time series data. Its powerful data throughput capability and stable performance make it very suitable to be applied in the field of Internet of Things (IoT). EMQX Cloud now supports connection to mainstream versions of InfluxDB Cloud, InfluxDB OSS, or InfluxDB Enterprise.
This page provides a comprehensive introduction to the data integration between EMQX Cloud and InfluxDB with practical instructions on creating and validating the data integration.
How It Works
InfluxDB data integration is an out-of-the-box feature in EMQX Cloud that combines EMQX Cloud's real-time data capturing and transmission capabilities with InfluxDB's data storage and analysis functionality. With a built-in rule engine component, the integration simplifies the process of ingesting data from EMQX Cloud to InfluxDB for storage and analysis, eliminating the need for complex coding. EMQX Cloud forwards device data to InfluxDB for storage and analysis through the rule engine and Sink. After analyzing the data, InfluxDB generates reports, charts, and other data analysis results, and then presents them to users through InfluxDB's visualization tools.
The diagram below illustrates the typical data integration architecture between EMQX and InfluxDB in an energy storage scenario.
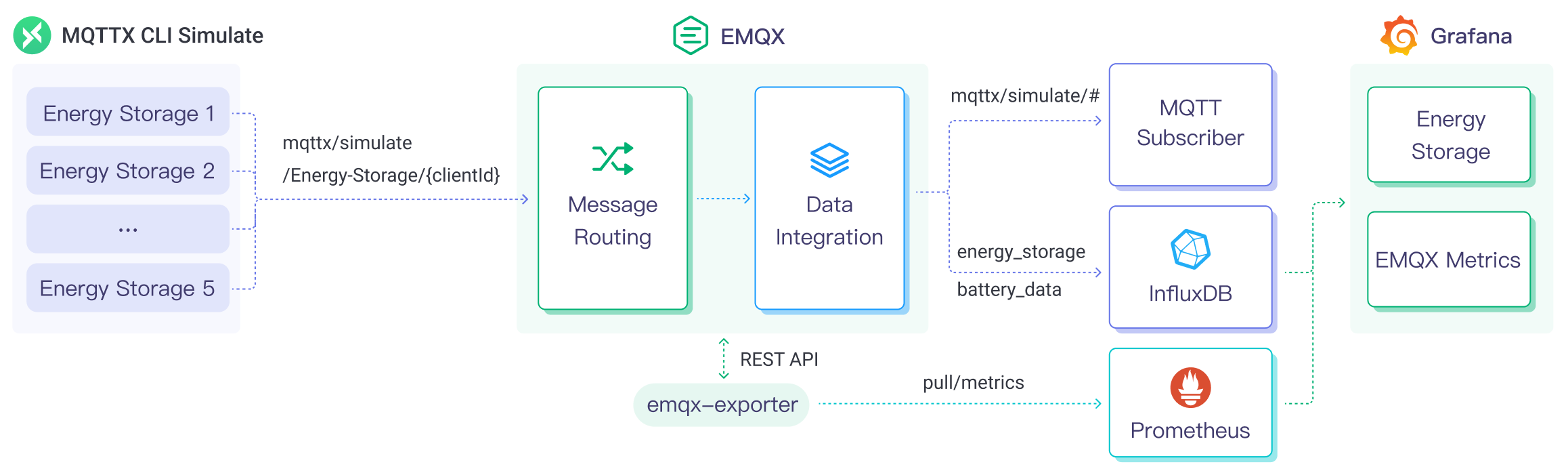
EMQX Cloud and InfluxDB provide an extensible IoT platform for efficiently collecting and analyzing energy consumption data in real-time. In this architecture, EMQX Cloud serves as the IoT platform, handling device access, message transmission, and data routing, while InfluxDB serves as the data storage and analysis platform, responsible for data storage and analysis functions. The workflow is as follows:
- Message publication and reception: Energy storage devices and Industrial IoT devices establish successful connections to EMQX Cloud through the MQTT protocol and regularly publish energy consumption data using the MQTT protocol, including information such as power consumption, input/output power, etc. When EMQX Cloud receives these messages, it initiates the matching process within its rules engine.
- Message data processing: Using the built-in rule engine, messages from specific sources can be processed based on topic matching. When a message arrives, it passes through the rule engine, which matches it with the corresponding rule and processes the message data, such as transforming data formats, filtering specific information, or enriching messages with contextual information.
- Data ingestion into InfluxDB: Rules defined in the rule engine trigger the operation of writing messages to InfluxDB. The InfluxDB Sink provides Line Protocol templates that allow flexible definitions of the data format to be written, mapping specific fields from the message to the corresponding measurement and field in InfluxDB.
After energy consumption data is written to InfluxDB, you can use Line Protocol flexibly to analyze the data, for example:
- Connect to visualization tools like Grafana to generate charts based on the data, displaying energy storage data.
- Connect to business systems for monitoring and alerting on the status of energy storage devices.
Features and Benefits
The InfluxDB data integration offers the following features and advantages:
- Efficient Data Processing: EMQX Cloud can handle a massive number of IoT device connections and message throughput, while InfluxDB excels in data writing, storage, and querying, providing outstanding performance to meet the data processing needs of IoT scenarios without overburdening the system.
- Message Transformation: Messages can undergo extensive processing and transformation through EMQX Cloud rules before being written into InfluxDB.
- Scalability: Both EMQX Cloud and InfluxDB are capable of cluster scaling, allowing flexible horizontal expansion of clusters as business needs grow.
- Rich Query Capabilities: InfluxDB offers optimized functions, operators, and indexing techniques, enabling efficient querying and analysis of timestamped data, and accurately extracting valuable insights from IoT time-series data.
- Efficient Storage: InfluxDB uses encoding methods with high compression ratios, significantly reducing storage costs. It also allows customization of storage durations for different data types to avoid unnecessary data occupying storage space.
Before You Start
This section introduces the preparatory work needed to create InfluxDB Data Integration in EMQX Cloud.
Prerequisites
Knowledge about InfluxDB line protocol.
Understand rules.
Understand data integration.
Set up Network
Before configuring data integration, you must create an EMQX Cloud deployment and ensure network connectivity between EMQX Cloud and the target service.
For Dedicated Flex deployments:
Create a VPC Peering Connection between the EMQX Cloud VPC and the target service VPC. After the peering connection is established, EMQX Cloud can access the target service through its private IP address.
If access through a public IP is required, configure a NAT Gateway to enable outbound connectivity.
For BYOC (Bring Your Own Cloud) deployments:
Create a VPC peering connection between the VPC where the BYOC deployment is running and the VPC hosting the target service. Once peering is in place, the target service can be accessed via its private IP address.
If the target service must be accessed through a public IP, configure a NAT Gateway in the BYOC VPC using your cloud provider’s console.
Install and Set up InfluxDB
Install InfluxDB via Docker
- Install InfluxDB via Docker, and then run the docker image.
# TO start the InfluxDB docker image
docker run --name influxdb -p 8086:8086 influxdb:2.5.1With InfluxDB running, visit the server address on port 8086. Set the Username, Password, Organization Name, and Bucket Name.
In the InfluxDB UI, click Load Data -> API Token and then follow the instructions to create all-access tokens.
Create InfluxDB Service using InfluxDB Cloud
Login to the InfluxDB Cloud.
In the InfluxDB UI, Set the Username, Password, Organization Name, and Bucket Name.
In the InfluxDB UI, click Load Data -> API Token and then follow the instructions to create all-access tokens.
Create an InfluxDB Connector
Before creating data integration rules, you need to first create a InfluxDB connector to access the InfluxDB server.
Go to your deployment. Click Data Integration from the left-navigation menu.
If it is the first time for you to create a connector, select InfluxDB under the Data Forward category. If you have already created connectors, select New Connector and then select InfluxDB under the Data Forward category.
Connector Name: The system will automatically generate a connector name.
Enter the connection information:
- Select the Version of InfluxDB as needed. Supported versions are
V1,V2(default), andV3. - Server Host: IP address and port of the server. If using InfluxDB Cloud, specify port 443, i.e., enter
{url}:443and click Enable TLS to activate TSL connection. - Complete the Token, Organization, and Bucket settings according to the setup in Install and Set Up InfluxDB. Note: If choosing InfluxDB v1, please complete the settings for Database, Username, and Password.
- Select the Version of InfluxDB as needed. Supported versions are
Click the Test button. If the InfluxDB service is accessible, a success prompt will be returned.
Click the New button to complete the creation.
Create a Rule
Next, you need to create a rule to specify the data to be written and add corresponding actions in the rule to forward the processed data to InfluxDB.
Click New Rule in Rules area or click the New Rule icon in the Actions column of the connector you just created.
Set the rules in the SQL Editor based on the feature to use, Our goal is to trigger the engine when the client sends a temperature and humidity message to the temp_hum/emqx topic. Here you need a certain process of SQL:
sqlSELECT timestamp, payload.location as location, payload.temp as temp, payload.hum as hum FROM "temp_hum/emqx"TIP
If you are a beginner user, click SQL Examples and Try It Out to learn and test the SQL rule.
Click Next to add an action.
Select the connector you just created from the Connector dropdown box.
Specify the Time Precision: Select
millisecondby default.Select Data Format as
JSONorLine Protocolfor how data should be parsed and written into InfluxDB.For JSON format, define data parsing method, including Measurement, Timestamp, Fields, and Tags. Note: All key values can be variables or placeholders, and you can also follow the InfluxDB line protocol to set them. The Fields field supports batch setting by importing a CSV file; for details, refer to Batch Setting.
For Line Protocol format, specify a text-based format that provides the measurement, tag set, field set, timestamp of a data point, and placeholder supported. See also InfluxDB 2.3 Line Protocol and InfluxDB 1.8 Line Protocol.
For example:
bashtemp_hum,location=${location} temp=${temp},hum=${hum} ${timestamp}TIP
- To write a signed integer type value to InfluxDB 1.x or 2.x, add
ias the type identifier after the placeholder, for example,${payload.int}i. See InfluxDB 1.8 write integer value. - To write an unsigned integer type value to InfluxDB 1.x or 2.x, add
uas the type identifier after the placeholder, for example,${payload.int}u. See InfluxDB 1.8 write integer value.
- To write a signed integer type value to InfluxDB 1.x or 2.x, add
Advanced Settings (Optional): Refer to Advanced Configuration.
Click the Confirm button to complete the rule creation.
In the Successful new rule pop-up, click Back to Rules, thus completing the entire data integration configuration chain.
Batch Setting
In InfluxDB, a data entry typically includes hundreds of fields, making the setup of data formats a challenging task. To address this, EMQX Cloud offers a feature for batch setting of fields.
When setting data formats via JSON, you can use the batch setting feature to import key-value pairs of fields from a CSV file.
Click the Import button in the Fields table to open the Import Batch Setting popup.
Follow the instructions to first download the batch setting template file, then fill in the key-value pairs of Fields in the template file. The default template file content is as follows:
Field Value Remarks (Optional) temp ${payload.temp} hum ${payload.hum} precip ${payload.precip}i Append an i to the field value to tell InfluxDB to store the number as an integer. - Field: Field key, supports constants or ${var} format placeholders.
- Value: Field value, supports constants or placeholders, can append type identifiers according to the line protocol.
- Remarks: Used only for notes within the CSV file, cannot be imported into EMQX.
Note that the data in the CSV file for batch setting should not exceed 2048 rows.
Save the filled template file and upload it to the Import Batch Setting popup, then click Import to complete the batch setting.
After importing, you can further adjust the key-value pairs of fields in the Fields setting table.
Test the Rule
You are recommended to use MQTTX to simulate temperature and humidity data reporting, but you can also use any other client.
Use MQTTX to connect to the deployment and send messages to the following Topic.
topic:
temp_hum/emqxpayload:
json{ "temp": 27.5, "hum": 41.8, "location": "Prague" }
In the InfluxDB UI, you can confirm whether the message is written into the InfluxDB via the Data Explorer window.
If using InfluxDB V1, enter the InfluxDB container and view the data in InfluxDB.
bash$ docker exec -it influxdb influx $ use dbbash> select * from "temp_hum" name: temp_hum time hum location temp ---- --- -------- ---- 1711093437420000000 41.8 Prague 27.5 >View operational data in the console. Click the rule ID in the rule list, and you can see the statistics of the rule and the statistics of all actions under this rule.