Elasticsearch に MQTT データを取り込む
Elasticsearch は、分散型の検索およびデータ分析エンジンであり、多様なデータタイプに対して全文検索、構造化検索、分析機能を提供します。EMQX Cloud と Elasticsearch を連携させることで、MQTT データをシームレスに Elasticsearch に取り込み、保存できます。この連携により、Elasticsearch の強力なスケーラビリティと分析機能を活用し、IoT アプリケーション向けに効率的かつスケーラブルなデータ保存および分析ソリューションを提供します。
本ページでは、EMQX Cloud と Elasticsearch 間のデータ統合について詳述し、ルールおよびアクションの作成方法について実践的なガイダンスを提供します。
動作概要
Elasticsearch とのデータ統合は EMQX Cloud の標準機能であり、EMQX Cloud のデバイスアクセスおよびメッセージ送受信機能と Elasticsearch のデータ保存・分析機能を組み合わせています。簡単な設定で MQTT データのシームレスな統合が可能です。
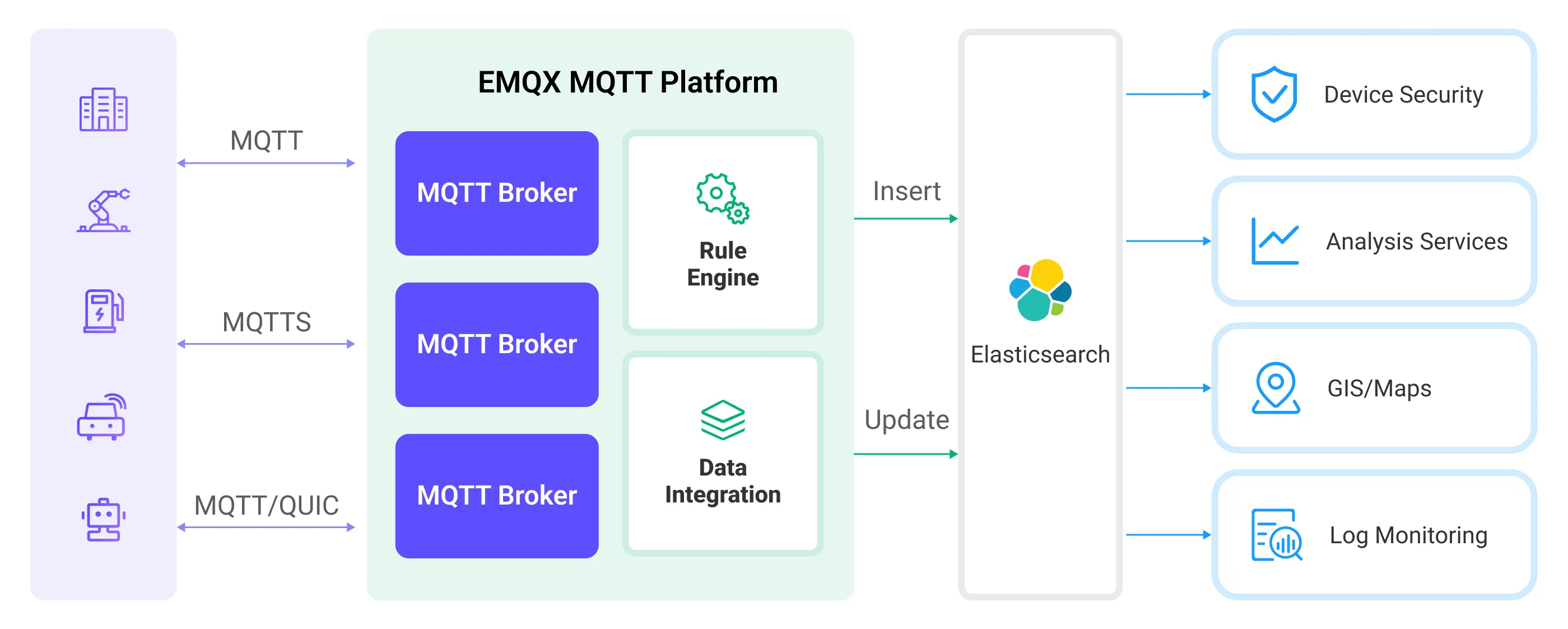
EMQX Cloud と Elasticsearch は、リアルタイムのデバイスデータを効率的に収集・分析するスケーラブルな IoT プラットフォームを提供します。このアーキテクチャでは、EMQX Cloud がデバイスアクセス、メッセージ送信、データルーティングを担う IoT プラットフォームとして機能し、Elasticsearch はデータ保存および分析プラットフォームとしてデータの保存、検索、分析を担当します。
EMQX Cloud はルールエンジンとアクションを通じてデバイスデータを Elasticsearch に転送し、Elasticsearch は強力な検索・分析機能を活用してレポートやチャートなどのデータ分析結果を生成し、Kibana の可視化ツールを通じてユーザーに表示します。ワークフローは以下の通りです。
- デバイスのメッセージパブリッシュと受信:IoT デバイスは MQTT プロトコルで接続し、特定のトピックにテレメトリやステータスデータをパブリッシュします。EMQX Cloud はこれを受信し、ルールエンジンで比較します。
- ルールエンジンによるメッセージ処理:組み込みのルールエンジンを用いて、特定のトピックにマッチする MQTT メッセージを処理します。ルールエンジンは対応するルールをマッチングし、データ形式の変換、特定情報のフィルタリング、コンテキスト情報の付加などの処理を行います。
- Elasticsearch への書き込み:ルールエンジンで定義されたルールがトリガーとなり、メッセージを Elasticsearch に書き込む操作を実行します。Elasticsearch アクションは柔軟な操作方法とドキュメントテンプレートを提供し、希望する形式のドキュメントを構築して、メッセージの特定フィールドを Elasticsearch の対応するインデックスに書き込みます。
デバイスデータが Elasticsearch に書き込まれた後は、Elasticsearch の検索および分析機能を柔軟に活用して以下のような処理が可能です。
- ログ監視:IoT デバイスは大量のログデータを生成し、これを Elasticsearch に送信して保存・分析できます。Kibana などの可視化ツールと連携することで、これらログデータに基づくチャートを作成し、デバイスの状態、稼働記録、エラーメッセージをリアルタイムに表示可能です。これにより開発者や運用者は潜在的な問題を迅速に特定・解決できます。
- 地理情報(マップ):IoT デバイスは地理位置情報を生成することが多く、これを Elasticsearch に保存できます。Kibana の Maps 機能を使うことで、デバイスの位置情報を地図上に可視化し、追跡や分析が可能です。
- エンドポイントセキュリティ:IoT デバイスのセキュリティログデータを Elasticsearch に送信し、Elastic Security と連携してセキュリティレポートを生成、デバイスのセキュリティ状況をリアルタイムで監視し、潜在的な脅威を検出して対応できます。
特長と利点
Elasticsearch データ統合は、以下の特長と利点をビジネスに提供します。
- 効率的なデータインデックス作成と検索:Elasticsearch は EMQX Cloud からの大規模リアルタイムメッセージデータを容易に処理できます。強力な全文検索およびインデックス作成機能により、IoT メッセージデータの迅速かつ効率的な検索・照会が可能です。
- データの可視化:Elastic Stack の一部である Kibana と連携することで、IoT データの強力な可視化が可能となり、データの理解と分析を支援します。
- 柔軟なデータ操作:EMQX Cloud の Elasticsearch 統合は、インデックス名、ドキュメント ID、ドキュメントテンプレートの動的設定をサポートし、ドキュメントの作成、更新、削除が可能で、より幅広い IoT データ統合シナリオに対応します。
- スケーラビリティ:Elasticsearch と EMQX Cloud の両方がクラスタリングをサポートし、ノードの追加により処理能力を容易に拡張でき、ビジネスの継続的な拡大を支援します。
はじめる前に
このセクションでは、EMQX Cloud で Elasticsearch データ統合を作成する前に必要な準備作業について説明します。Elasticsearch のインストールやインデックス作成が含まれます。
前提条件
ネットワーク設定
データ統合を構成する前に、EMQX Cloudのデプロイメントを作成し、EMQX Cloudと対象サービス間のネットワーク接続を確立していることを確認してください。
Dedicated Flexデプロイメントの場合:
EMQX CloudのVPCと対象サービスのVPC間でVPCピアリング接続を作成します。ピアリング接続が確立されると、EMQX Cloudは対象サービスのプライベートIPアドレスを介してアクセス可能になります。
パブリックIP経由でのアクセスが必要な場合は、NATゲートウェイを構成してアウトバウンド接続を有効にしてください。
BYOC(Bring Your Own Cloud)デプロイメントの場合:
BYOCデプロイメントが稼働しているVPCと対象サービスをホストするVPC間でVPCピアリング接続を作成します。ピアリングが確立されると、対象サービスのプライベートIPアドレスを介してアクセス可能になります。
対象サービスにパブリックIP経由でアクセスする必要がある場合は、クラウドプロバイダーのコンソールを使用してBYOC VPCにNATゲートウェイを構成してください。
Elasticsearch のデプロイとインデックス作成
EMQX Cloud はプライベートにデプロイされた Elasticsearch またはクラウド上の Elastic と連携可能です。Docker または Elastic Cloud を利用して Elasticsearch インスタンスをデプロイできます。
Docker で Elasticsearch をデプロイ
Docker 環境がない場合は、Docker をインストールしてください。
X-Pack セキュリティ認証を有効にして Elasticsearch コンテナを起動します。デフォルトのユーザー名
elasticとパスワードpublicを設定します。bashdocker run -d --name elasticsearch \ -p 9200:9200 \ -p 9300:9300 \ -e "discovery.type=single-node" \ -e "xpack.security.enabled=true" \ -e "ELASTIC_PASSWORD=public" \ docker.elastic.co/elasticsearch/elasticsearch:7.10.1デバイスがパブリッシュするメッセージを保存するための
device_dataインデックスを作成します。Elasticsearch のユーザー名とパスワードは適宜置き換えてください。bashcurl -u elastic:public -X PUT "localhost:9200/device_data?pretty" -H 'Content-Type: application/json' -d' { "mappings": { "properties": { "ts": { "type": "date" }, "clientid": { "type": "keyword" }, "payload": { "type": "object", "dynamic": true } } } }'
Elastic Cloud でのデプロイ
Elastic Cloud の利用方法については、公式ガイドをご参照ください。
- Elastic Cloud は 14日間の無料トライアルを提供しており、アカウント登録後に独自のデプロイメントを作成できます。登録後、Elastic Cloud コンソールが表示されます。
- デプロイメントを開始するには、Create deployment をクリックします。
- Elasticsearch のエンドポイント情報および認証情報を控えておき、後の接続に使用します。
- デバイスがパブリッシュするメッセージを保存するための
device_dataインデックスを作成します。Elasticsearch のユーザー名とパスワードは適宜置き換えてください。
curl -u elastic:xxxx -X PUT "{Elasticsearch endpoint}/device_data?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"ts": { "type": "date" },
"clientid": { "type": "keyword" },
"payload": {
"type": "object",
"dynamic": true
}
}
}
}'コネクターの作成
データ統合ルールを作成する前に、Elasticsearch サーバーにアクセスするためのコネクターを作成する必要があります。
デプロイメントに移動し、左側のナビゲーションメニューから データ統合 をクリックします。初めてコネクターを作成する場合は、Data Forward カテゴリの下にある Elasticsearch を選択します。すでにコネクターを作成済みの場合は、New Connector を選択し、続いて Data Forward カテゴリの下の Elasticsearch を選択します。
コネクター名:システムが自動的にコネクター名を生成します。
接続情報を入力します:
- Server:Elasticsearch サービスの REST インターフェース URL を
http://{host}:9200など適切に入力します。 - Username:Elasticsearch サービスのユーザー名を
elasticと指定します。 - Password:Elasticsearch サービスのパスワードを入力します。
- Enable TLS:暗号化接続を確立する場合はトグルスイッチをオンにします。
- ビジネスニーズに応じて詳細設定を行います(任意)。
- Server:Elasticsearch サービスの REST インターフェース URL を
Test ボタンをクリックします。Elasticsearch にアクセス可能であれば、connector available のメッセージが表示されます。
New ボタンをクリックして作成を完了します。
これで、このコネクターを基にデータブリッジルールを作成できます。
ルールの作成
このセクションでは、EMQX Cloud コンソールを使って Elasticsearch ルールを作成し、ルールにアクションを追加する方法を説明します。
ルールエリアの New Rule をクリックするか、作成したコネクターの Actions 列にある新規ルールアイコンをクリックします。
利用したい機能に基づいて SQL Editor でルールを設定します。ここでは、クライアントが
temp_hum/emqxトピックに温度と湿度のメッセージを送信した際にエンジンをトリガーすることを目標としています。SQL は以下のように記述します。sqlSELECT timestamp as up_timestamp, clientid as client_id, payload FROM "temp_hum/emqx"TIP
初心者の方は、SQL Examples と Try It Out をクリックして、SQL ルールの学習とテストを行うことをおすすめします。
Next をクリックしてアクションを追加します。
Connector のドロップダウンボックスから先ほど作成したコネクターを選択します。
EMQX Cloud から Elasticsearch サービスにメッセージをパブリッシュするための情報を設定します:
Action:任意の操作
Create、Update、Deleteを選択可能です。Index Name:操作対象のインデックス名またはインデックスエイリアス名を指定します。
${var}形式のプレースホルダーが使用可能です。Document ID:
Createアクションでは任意、その他のアクションでは必須です。インデックス内のドキュメントの一意識別子を指定します。${var}形式のプレースホルダーが使用可能です。指定しない場合は Elasticsearch が自動生成します。Routing:ドキュメントを格納するインデックスのシャードを指定します。空欄の場合は Elasticsearch が決定します。
Document Template:カスタムドキュメントテンプレートで、JSON オブジェクトに変換可能である必要があります。
${var}形式のプレースホルダーをサポートします。例:{ "field": "${payload.field}"}または${payload}。Max Retries:書き込み失敗時の最大リトライ回数。デフォルトは 3 回です。
Overwrite Document(
Createアクション特有):既存ドキュメントが存在する場合に上書きするかどうか。Noの場合は書き込みが失敗します。本例では、インデックス名を
device_dataに設定し、クライアント ID とタイムスタンプの組み合わせ${clientid}_${ts}をドキュメント ID としています。ドキュメントはクライアント ID、現在のタイムスタンプ、メッセージ本文全体を保存します。ドキュメントテンプレートは以下の通りです。json{ "clientid": "${clientid}", "ts": ${ts}, "payload": ${payload} }
Advanced Settings を展開し、同期/非同期モード、キューやキャッシュなどのパラメータを適宜設定します(任意)。
Confirm ボタンをクリックしてルール作成を完了します。
Successful new rule ポップアップで Back to Rules をクリックし、データ統合の設定チェーンを完了します。
ルールのテスト
温度・湿度データの報告をシミュレートするために MQTTX の使用を推奨しますが、他のクライアントでも構いません。
MQTTX でデプロイメントに接続し、以下のトピックにメッセージを送信します。
トピック:
temp_hum/emqxクライアント ID:
test_clientペイロード:
json{ "temp": "27.5", "hum": "41.8" }
_searchAPI を使ってインデックス内のドキュメント内容を確認し、device_dataインデックスにデータが書き込まれているかを確認します。bashcurl -u elastic:public -X GET "localhost:9200/device_data/_search?pretty"正常なレスポンス例は以下の通りです。
json{ "took": 484, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 1.0, "hits": [ { "_index": "device_data", "_type": "_doc", "_id": "mqttx_a2acfd19_1711359139238", "_score": 1.0, "_source": { "clientid": "mqttx_a2acfd19", "ts": 1711359139238, "payload": { "temp": "27.5", "hum": "41.8" } } } ] } }