将 MQTT 数据写入到 Datalayers
Datalayers 是一款面向工业物联网、车联网、能源等行业的多模、超融合数据库。其强大的数据吞吐能力以及稳定的性能表现使其非常适合物联网领域。EMQX 目前已支持通过 Sink 将消息和数据存储到 Datalayers 中,以便进行数据分析和可视化。
本页详细介绍了 EMQX 与 Datalayers 的数据集成并提供了实用的规则和 Sink 创建指导。
工作原理
Datalayers 数据集成是 EMQX 中开箱即用的功能,可将来自设备的 MQTT 消息转发至 Datalayers 进行存储与分析。通过规则引擎与 Sink 配置,用户可以灵活地将处理后的数据写入 Datalayers,实现 MQTT 数据的无缝集成。
下图展示了储能场景中 EMQX 和 Datalayers 数据集成的典型架构。
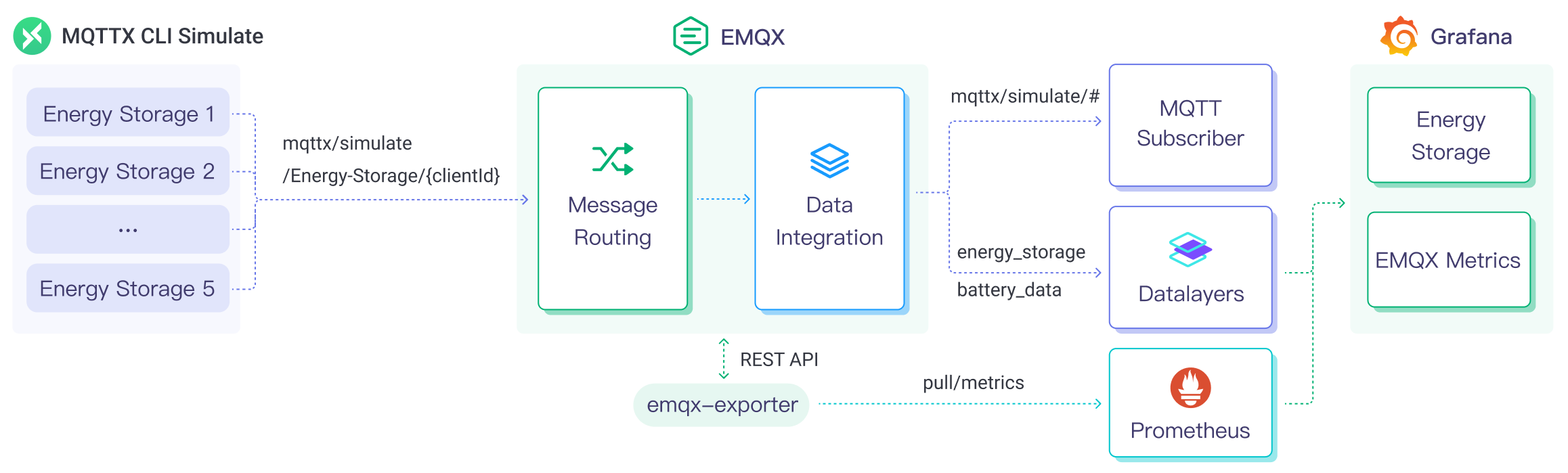
在此架构中,EMQX 负责设备接入、消息传输与规则处理,Datalayers 负责数据存储、数据分析和可视化展示。二者结合,构建了一个可扩展的物联网平台,用于高效地实时收集和分析能耗数据。
从 EMQX 6.0.0 开始,Datalayers 增加了对 Arrow Flight SQL 驱动的支持,基于 Apache Arrow 实现更高效、低延迟的数据传输。相比传统的 InfluxDB 行协议写入,Arrow Flight 提供了更强的结构化写入能力。
注意
Arrow Flight Driver 由 Rust 编写,并通过 Erlang NIF 绑定至 Erlang 虚拟机。当前为实验性功能,建议在测试环境中评估使用效果。
Datalayers 数据集成具体的工作流程如下:
消息发布与接收:储能设备通过 MQTT 协议连接成功后定期发布能耗数据,这些数据包括电量、输入输出功率信息。EMQX 接收到消息后将在规则引擎中进行比对。
规则引擎处理消息:通过内置的规则引擎,可以根据主题匹配处理特定来源的消息。当消息到达时,它会通过规则引擎,规则引擎会匹配对应的规则,并对消息数据进行处理,例如转换数据格式、过滤掉特定信息或使用上下文信息丰富消息。
写入到 Datalayers:规则引擎中定义的规则触发将消息写入到 Datalayers 的动作。Datalayers Sink 提供了 SQL 模板,能够灵活地定义写入的数据格式,将消息中的特定字段写入到 Datalayers 的对应的表和列中。EMQX 提供两种写入方式:
- 使用 InfluxDB 行协议
- 使用 Arrow Flight SQL 驱动
Sink 的配置方式将根据所选择的驱动类型而异。
储能数据写入到 Datalayers 后,您可以灵活的使用查询工具(如行协议)对数据进行分析,例如:
- 连接到可视化工具,例如 Grafana,根据数据生成图表,展示储能数据。
- 连接业务系统,进行储能设备状态监控与告警。
特性与优势
Datalayers 数据集成具有以下特性与优势:
- 高效的数据处理能力:EMQX 能够处理海量物联网设备连接与消息吞吐,Datalayers 在数据写入、存储和查询方面具有出色的性能表现,能够满足物联网场景下的数据处理需求,不会导致系统不堪重负。
- 消息转换:消息可以写入 Datalayers 之前,通过 EMQX 规则中进行丰富的处理和转换。
- 可扩展性:EMQX 与 Datalayers 都具备集群扩展能力,能够随着业务的发展,利用灵活地进行集群水平扩展,满足业务的发展需求。
- 丰富的查询能力:Datalayers 提供包括优化的函数、运算符和索引技术,可实现对时间戳数据的高效查询和分析,准确地从 IoT 时间序列数据中提取有价值的见解。
- 高效存储:Datalayers 使用高压缩比的编码方式,可以大幅降低存储成本。也可以自定义不同数据的存储时间,避免不必要的数据占用存储空间。
准备工作
本节介绍了在 EMQX 中创建 Datalayers Sink 之前需要做的准备工作,包括安装 Datalayers、设置数据库与表结构等。
前置准备
- 了解 Datalayers 行协议或 Arrow Flight SQL,根据您选用的驱动类型,准备相应的写入方式。
- 了解规则。
- 了解数据集成。
安装和设置 Datalayers
通过 Docker 安装并启动 Datalayers,详细步骤请参考通过 Docker 快速体验 Datalayers。
bash# 启动一个 Datalayers 容器 docker run -d --name datalayers -p 8360:8360 -p 8361:8361 datalayers/datalayers:latest8360是用于 Arrow Flight SQL 的 gRPC 默认端口;8361是 HTTP 接口,通常用于行协议写入或管理 API。
Datalayers 服务启动后,您可以通过以下步骤进入 Datalayers CLI 中创建数据库,默认的用户和密码为
admin/public:进入 Datalayers 容器:
bashdocker exec -it datalayers bash进入 Datalayers CLI:
bashdlsql -u admin -p public创建数据库:
sqlcreate database mqtt
如果您打算使用 Arrow Flight SQL 驱动,则需要预先在数据库中创建目标表。
注意
如果您使用的是 InfluxDB 行协议驱动,则无需预先建表,Datalayers 会根据行协议中的 measurement 和字段自动建表。
例如,使用以下 SQL 将创建一个名为
t_mqtt_msg的数据表:sqlCREATE TABLE IF NOT EXISTS `t_mqtt_msg` ( time TIMESTAMP(3) NOT NULL, msgid STRING NOT NULL, sender STRING NOT NULL, topic STRING NOT NULL, qos INT8 NOT NULL, payload STRING, arrived TIMESTAMP(3) NOT NULL, timestamp key(time) ) PARTITION BY HASH (msgid, sender) PARTITIONS 1 ENGINE=TimeSeries with (ttl='14d');
创建 Datalayers 连接器
本节演示了如何创建一个用于将 Sink 连接到 Datalayers 服务器的连接器。
以下步骤假定 EMQX 与 Datalayers 均在本地运行。如您在远程环境中部署 EMQX 或 Datalayers,请根据实际地址修改相应配置。
进入 EMQX Dashboard,点击集成 -> 连接器。
点击页面右上角的创建。
在创建连接器页面,点击选择 Datalayers,然后点击下一步。
在配置信息步骤页中填写连接器信息:
- 连接器名称:必须以字母或数字开头,可以包含字母、数字、连字符(-)或下划线(_),例如:
my_datalayers。 - 描述(可选):为连接器添加说明信息,方便后续管理。
- 连接器名称:必须以字母或数字开头,可以包含字母、数字、连字符(-)或下划线(_),例如:
配置 Datalayers 服务器连接信息:
驱动类型:
选择
InfluxDB 行协议:使用兼容 InfluxDB 的行协议进行写入,支持自动建表;选择
Arrow Flight:使用结构化 SQL 模板进行高性能数据写入,适合对数据结构和写入效率有更高要求的场景。注意
Arrow Flight Driver 由 Rust 编写,并通过 Erlang Nif 绑定到 Erlang 虚拟机。此功能目前仍为实验性功能。
服务器地址:
- 默认地址为
127.0.0.1:8361; - 若选择
Arrow Flight驱动,实际数据通信使用 gRPC,端口为8360。
- 默认地址为
数据库名字:写入数据的目标数据库,本示例中为
mqtt。用户名 / 密码:填写 Datalayers 管理员或授权用户的登录凭据,本示例中为
admin/public。启用 TLS(可选):是否启用加密连接。开启后可配置证书文件路径、校验证书等。有关 TLS 连接选项的详细信息,请参阅启用 TLS 加密访问外部资源。
TIP
使用 Arrow Flight SQL 协议连接 Datalayers 时,由于依赖库限制,不能跳过证书校验(即不支持
verify_none模式)。请确保 Datalayers gRPC 服务端证书合法,Common Name 与服务器地址匹配。
若选择的是
Arrow Flight驱动,还需设置是否启用预处理语句,用于控制是否允许 Sink 使用 SQL 模板方式写入数据;默认为开启。在点击创建之前,您可以点击测试连接,以测试连接器是否能够连接到 Datalayers 服务器。
点击最下方的创建按钮完成连接器的创建。在弹出对话框中,您可以点击返回连接器列表或点击创建规则继续创建规则和 Sink,将数据写入 Datalayers。具体步骤请参见创建 Datalayers 规则。
创建 Datalayers 规则
本节演示了如何在 EMQX 中创建一条规则,用于处理来自源 MQTT 主题 t/# 的消息,并通过配置的 Sink,将处理后的结果写入 Datalayers。
创建规则并配置规则处理 SQL
点击 Dashboard 左侧导航菜单中的数据集成 -> 规则。
在规则页面点击右上角的创建按钮。
在规则创建页面,输入规则 ID,例如
my_rule。在 SQL 编辑器中输入规则,例如将
t/#主题的 MQTT 消息存储至 Datalayers,可以输入以下 SQL 语句:注意
如果您希望指定自己的 SQL 规则,必须确保
SELECT语句中包含之后 Sink 写入模板中所引用的所有变量。例如,如果 Sink 模板中引用了${clientid}、${payload.temp}等字段,则这些字段必须包含在 SQL 结果中。sqlSELECT * FROM "t/#"TIP
如果您初次使用 SQL,可以点击 SQL 示例和启用调试来学习和测试规则 SQL 的结果。
为规则添加带有 Datalayers Sink,用于将规则处理结果写入 Datalayers。
- 若使用 InfluxDB 行协议方式写入,参考:添加 InfluxDB 行协议 Sink。
- 若使用 Arrow Flight SQL 驱动写入,参考:添加 Arrow Flight SQL Sink。
在创建规则页面,验证配置的信息。点击保存按钮生成规则。
现在您已成功创建规则,您可以在规则页面上看到新的规则。点击动作 (Sink) 标签,您可以看到新的 Datalayers Sink。
您还可以点击集成 -> Flow 设计器查看拓扑。可以看到 t/# 主题的消息经过名为 my_rule 的规则处理,处理结果交由 Datalayers 进行存储。
添加 InfluxDB 行协议 Sink
本节演示了如何在规则中添加一个使用 InfluxDB 行协议的 Sink,可将规则处理后的结果通过 InfluxDB 行协议写入 Datalayers。
点击右侧的添加动作按钮,为规则在被触发的情况下指定一个动作。通过这个动作,EMQX 会将经规则处理的数据转发到 Datalayers。
在动作下拉框中选择
Datalayers,将动作下拉框保留为默认的创建动作。您也可以选择一个之前已经创建好的 Datalayers Sink。本次演示将创建一个新的 Sink。设置 Sink 名称,例如
dl_sink_influx。建议使用大小写字母与数字组合。从连接器下拉框中选择已创建的连接器,驱动类型应配置为
InfluxDB 行协议。如尚未创建连接器,可点击右侧按钮新建,详见创建 Datalayers 连接器。设定时间精度,默认为毫秒。
定义解析数据, 指定数据格式与内容,使其能被解析并写入到 Datalayers 中,可选项为
JSON或Line Protocol。对于 JSON 格式,需设置数据的 Measurement,Fields,Timestamp 与 Tags,键值均支持常量或占位符变量,可按照行协议进行设置。其中 Fields 字段支持通过 CSV 文件批量设置,详细请参考使用 CSV 批量设置字段。
对于 Line Protocol 格式,请通过一段语句指定数据点的 Measurement、Fields、Timestamp 与 Tags,键值均支持常量或占位符变量,可按照行协议进行设置。
TIP
由于 Datalayers 的写入完全兼容 InfluxDB v1 行协议,因此您可以参考 InfluxDB 行协议来设置数据格式。
例如,输入带符号的整型值,请在占位符后添加
i作为类型标识,例如${payload.int}i。参见 InfluxDB 1.8 写入整型值。此处,我们可以使用 Line Protocol 格式,将其设置为:
sqldevices,clientid=${clientid} temp=${payload.temp},hum=${payload.hum},precip=${payload.precip}i ${timestamp}
备选动作(可选):如果您希望在消息投递失败时提升系统的可靠性,可以为 Sink 配置一个或多个备选动作。当 Sink 无法成功处理消息时,这些备选动作将被触发。更多信息请参见:备选动作。
展开高级设置,根据需要配置高级设置选项(可选),详细请参考高级设置。
在点击创建之前,您可以点击测试连接,以测试 Sink 是否能够连接到 Datalayers 服务器。
点击创建完成 Sink 的创建。回到创建规则页面,您将看到新的 Sink 出现在动作输出页签下。
使用 CSV 批量设置字段
TIP
该功能仅适用于使用 InfluxDB 行协议写入 的 Sink,并在数据格式选择为 JSON 时启用。可用于批量导入 Fields 字段配置。
在 Datalayers 中,一个数据条目通常包含数百个字段(Fields),这使得数据格式的设置变得具有挑战性。为了解决这个问题,EMQX 提供了批量设置字段的功能。
当通过 JSON 设置数据格式时,您可以使用批量设置功能,从 CSV 文件中导入字段的键值对。
点击 Fields 表格中的批量设置按钮,打开导入批量设置弹窗。
根据指引,先下载批量设置模板文件,然后在模板文件中填入 Fields 键值对,默认的模板文件内容如下:
Field Value Remarks (Optional) temp ${payload.temp} hum ${payload.hum} precip ${payload.precip}i 在字段值后追加 i,Datalayers 则将该数值存储为整数类型。 - Field: 字段键,支持常量或 ${var} 格式的占位符。
- Value: 字段值,支持常量或占位符,可以按照行协议追加类型标识。
- Remarks: 仅用于 CSV 文件内字段的备注,无法导入到 EMQX 中。
注意,批量设置 CSV 文件中数据不能超过 2048 行。
将填好的模板文件保存并上传到导入批量设置弹窗中,点击导入完成批量设置。
导入完成后,您可以在 Fields 设置表格中进一步调整字段的键值对。
添加 Arrow Flight SQL Sink
本节演示如何为规则添加一个使用 Arrow Flight SQL 驱动的 Sink,将数据以 SQL 插入方式写入 Datalayers。
注意
使用 Arrow Flight SQL 驱动写入目前仍为实验性功能。
点击右侧的添加动作按钮,为规则在被触发的情况下指定一个动作。通过这个动作,EMQX 会将经规则处理的数据转发到 Datalayers。
在动作下拉框中选择
Datalayers,将动作下拉框保留为默认的创建动作。您也可以选择一个之前已经创建好的 Datalayers Sink。本次演示将创建一个新的 Sink。设置 Sink 名称,例如
dl_sink_arrow。建议使用大小写字母与数字组合。从连接器下拉框中选择已创建的连接器,驱动类型应配置为
Arrow Flight。如尚未创建连接器,可点击右侧按钮新建,详见创建 Datalayers 连接器。配置 SQL 模板,用于指定数据写入方式。例如,可以使用如下 SQL 完成数据插入:
TIP
此处为预处理 SQL,字段不应当包含引号,SQL 末尾不要带分号
;。占位符${}中的变量应来自规则 SQL 的 SELECT 字段。TIP
如果需要将数据插入到非连接器配置中的数据库,请在 SQL 模板中添加对应的数据库名字。 请注意,连接器仍会检查目标数据库是否存在。
sqlinsert into t_mqtt_msg(time, msgid, sender, topic, qos, payload, arrived) values (${timestamp}, ${id}, ${clientid}, ${topic}, ${qos}, ${payload}, ${timestamp})备选动作(可选):如果您希望在消息投递失败时提升系统的可靠性,可以为 Sink 配置一个或多个备选动作。当 Sink 无法成功处理消息时,这些备选动作将被触发。更多信息请参见:备选动作。
展开高级设置,根据需要配置高级设置选项(可选),详细请参考高级设置。
在点击创建之前,您可以点击测试连接,以测试 Sink 是否能够连接到 Datalayers 服务器。
点击创建完成 Sink 的创建。回到创建规则页面,您将看到新的 Sink 出现在动作输出页签下。
测试规则和 Sink
完成规则与 Sink 配置后,您可以通过发布一条 MQTT 消息,验证是否成功写入 Datalayers。
使用 MQTTX 向
t/1主题发布消息,此操作同时会触发上下线事件:bashmqttx pub -i emqx_c -t t/1 -m '{ "temp": "23.5", "hum": "62", "precip": 2}'此消息将触发规则引擎,并被转发至已配置的 Datalayers Sink。若规则中启用了会话事件(例如上线/下线),该消息也可能触发额外事件处理。
查看 Sink 运行统计。在 Dashboard 中,进入规则的列表页,切换到 动作 (Sink) 标签页,确认目标 Sink 的命中次数与发送成功次数已增加 1。
使用 Datalayers CLI 验证数据写入。
进入 Datalayers 容器并启动 CLI 工具:
bashdocker exec -it datalayers bash dlsql -u admin -p public接下来,根据使用的数据写入类型,执行相应的 SQL 查询数据是否成功写入到数据库。
如果使用 InfluxDB 行协议写入,默认情况下,表名为 Sink 中指定的 Measurement 名称,例如
devices:sqluse mqtt select * from devices使用 Arrow Flight SQL 驱动写入,表名为提前创建好的
t_mqtt_msg:sqluse mqtt select * from t_mqtt_msg
高级设置
本节将深入介绍可用于 Datalayers 连接器和 Sink 的高级配置选项。在 Dashboard 中配置连接器和 Sink 时,您可以根据您的特定需求展开高级设置,调整以下参数。
| 字段名称 | 描述 | 默认值 |
|---|---|---|
| 缓存池大小 | 指定缓冲区工作进程数量。这些工作进程将被分配用于管理 EMQX 与 Datalayers 的出口 (egress)类型 Sink 中的数据流,它们负责在将数据发送到目标服务之前临时存储和处理数据。此设置对于优化性能并确保出口(egress)场景中的数据传输顺利进行尤为重要。对于仅处理入口 (ingress)数据流的桥接,此选项可设置为 0,因为不适用。 | 4 |
| 请求超期 | “请求 TTL”(生存时间)配置设置指定了请求在进入缓冲区后被视为有效的最长持续时间(以秒为单位)。此计时器从请求进入缓冲区时开始计时。如果请求在缓冲区内停留的时间超过了此 TTL 设置或者如果请求已发送但未能在 Datalayers 中及时收到响应或确认,则将视为请求已过期。 | 45 |
| 健康检查间隔 | 指定 Sink 将对与 Datalayers 的连接执行自动健康检查的时间间隔(以秒为单位)。 | 15 |
| 缓存队列最大长度 | 指定可以由 Datalayers Sink 中的每个缓冲区工作进程缓冲的最大字节数。缓冲区工作进程在将数据发送到 Datalayers 之前会临时存储数据,充当处理数据流的中介以更高效地处理数据流。根据系统性能和数据传输要求调整该值。 | 1 |
| 最大批量请求大小 | 指定可以在单个传输操作中从 EMQX 发送到 Datalayers 的数据批处理的最大大小。通过调整此大小,您可以微调 EMQX 与 Datalayers 之间数据传输的效率和性能。 如果将“最大批处理大小”设置为 1,则数据记录将单独发送,而不会分组成批处理。 | 100 |
| 请求模式 | 允许您选择同步或异步请求模式,以根据不同要求优化消息传输。在异步模式下,写入到 Datalayers 不会阻塞 MQTT 消息发布过程。但是,这可能导致客户端在它们到达 Datalayers 之前就收到了消息。 | 异步 |
| 请求飞行队列窗口 | “飞行队列请求”是指已启动但尚未收到响应或确认的查询。此设置控制 Sink 与 Datalayers 通信时可以同时存在的最大飞行队列请求数。 当 请求模式 设置为 异步 时,“请求飞行队列窗口”参数变得特别重要。如果对于来自同一 MQTT 客户端的消息严格按顺序处理很重要,则应将此值设置为 1。 | 100 |