将 MQTT 数据写入到 Amazon S3 存储桶中
Amazon S3 是一种面向互联网的存储服务,具有高度的可靠性、稳定性和安全性,能够快速部署和使用。EMQX 能够将 MQTT 消息高效地存储至 Amazon S3 存储桶中,实现灵活的物联网数据存储功能。
本页详细介绍了 EMQX 与 Amazon S3 的数据集成并提供了实用的规则和 Sink 创建指导。
TIP
EMQX 也兼容其他支持 S3 协议的存储服务,例如:
- MinIO: MinIO 是一款高性能、分布式的对象存储系统。它是兼容 Amazon S3 API 的开源对象存储服务器,可以用于构建私有云。
- Google Cloud Storage: Google Cloud Storage 是 Google Cloud 的统一对象存储,用于开发者和企业存储大量数据。它提供了与 Amazon S3 兼容的接口。
您可以根据自己的业务需求和场景选择合适的存储服务。
工作原理
Amazon S3 数据集成是 EMQX 中开箱即用的功能,通过简单的配置即可实现复杂的业务开发。在一个典型的物联网应用中,EMQX 作为物联网平台,负责接入设备进行消息传输,Amazon S3 作为数据存储平台,负责消息数据的存储。
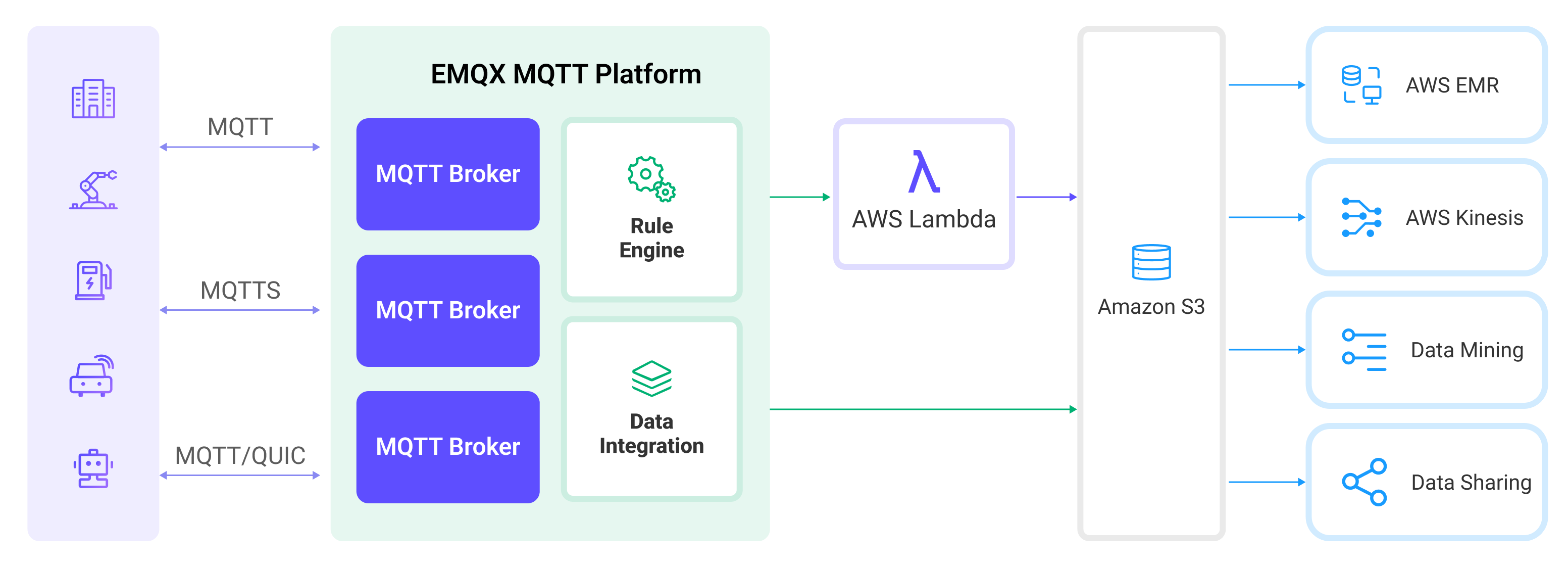
EMQX 通过规则引擎与 Sink 将设备事件和数据转发至 Amazon S3,应用读取 Amazon S3 中数据即可进行数据的应用。其具体的工作流程如下:
- 设备连接到 EMQX:物联网设备通过 MQTT 协议连接成功后将触发上线事件,事件包含设备 ID、来源 IP 地址以及其他属性等信息。
- 设备消息发布和接收:设备通过特定的主题发布遥测和状态数据,EMQX 接收到消息后将在规则引擎中进行比对。
- 规则引擎处理消息:通过内置的规则引擎,可以根据主题匹配处理特定来源的消息和事件。规则引擎会匹配对应的规则,并对消息和事件进行处理,例如转换数据格式、过滤掉特定信息或使用上下文信息丰富消息。
- 写入到 Amazon S3:规则触发后,消息会被写入到 Amazon S3。通过使用 Amazon S3 Sink,用户可以从处理结果中提取数据并发送到 S3。消息可以以文本、二进制格式存储,或者将多行结构化数据聚合成一个 CSV 文件、 JSON Lines 文件或 Parquet 格式文件,具体取决于消息内容和 Sink 的配置。
事件和消息数据写入到 Amazon S3 后,您可以连接到 Amazon S3 读取数据,进行灵活的应用开发,例如:
- 数据归档:将设备消息作为对象存储,长期保存在 Amazon S3 中,以满足数据保留和合规性要求。
- 数据分析:将 S3 中的数据导入到分析服务例如 Snowflake 中,实现预测性维护、设备效能评估等数据分析业务。
特性与优势
在 EMQX 中使用 Amazon S3 数据集成能够为您的业务带来以下特性与优势:
- 消息转换:消息可以在写入 Amazon S3 之前,通过 EMQX 规则中进行丰富的处理和转换,方便后续的存储和使用。
- 灵活数据操作:通过 S3 Sink,可以方便地将特定字段的数据写入到 Amazon S3 存储桶中,支持动态设置存储桶与对象键,实现数据的灵活存储。
- 整合业务流程:通过 S3 Sink 可以将设备数据与 Amazon S3 丰富的生态应用结合,以实现更多的业务场景,例如数据分析、数据归档等。
- 低成本长期存储:相较于数据库,Amazon S3 提供了高可用、高可靠、低成本的对象存储服务,可以满足长期存储的需求。
通过以上特性,您可以构建高效、可靠和可扩展的物联网应用,并在业务决策和优化方面受益。
准备工作
本节介绍了在 EMQX 中创建 Amazon S3 Sink 之前需要做的准备工作。
前置准备
在开始之前,请确保您已了解以下内容:
EMQX 相关概念:
AWS 相关概念:
如果您是第一次使用 AWS S3 存储服务,请了解以下概念:
- EC2:AWS 的虚拟机服务(计算实例)。
- IAM:AWS 身份与权限管理,实例角色可给在该实例上运行的程序签发临时凭证。
- IMDSv2:EC2 的实例元数据/临时凭证获取接口,采用令牌机制,更安全。
准备 S3 存储桶
EMQX 支持 Amazon S3 以及兼容 S3 的存储服务,您可以使用 AWS 云服务或者 Docker 部署一个 MinIO 实例。
创建连接器
在添加 S3 Sink 前,您需要创建对应的连接器,创建步骤如下:
转到 Dashboard 集成 -> 连接器页面。
点击页面右上角的创建。
在连接器类型中选择 Amazon S3,点击下一步。
输入连接器名称。名称必须以字母或数字开头,可以包含字母、数字、连字符或下划线。例如:
my-s3。输入连接信息:
如果使用 AWS S3 存储桶,请输入以下信息:
主机:根据区域不同,格式为
s3.{region}.amazonaws.com。端口:填写
443。访问密钥 ID 和私有访问密钥:
- 填写在 AWS 中创建的访问密钥,或者
- 如果 EMQX 运行在已绑定 IAM 角色的 EC2 上,可留空。
详细说明请参见准备 S3 存储桶中的 Amazon S3 标签页。
如果使用 MinIO:
- 主机:填写
127.0.0.1(如果 MinIO 在远程运行,填写实际地址)。 - 端口:填写
9000。 - 访问密钥 ID 和私有访问密钥:填写 MinIO 中创建的访问密钥。
- 主机:填写
点击创建之前,您可以先点击测试连接来测试连接器是否可以连接到 S3 服务。
点击最下方创建按钮完成连接器创建。
至此您已经完成连接器创建,接下来将继续创建一条规则和 Sink 来指定需要写入的数据。
创建 Amazon S3 Sink 规则
本节演示了如何在 EMQX 中创建一条规则,用于处理来自源 MQTT 主题 t/# 的消息,并通过配置的 Sink 将处理后的结果写入到 S3 的 iot-data 存储桶中。
转到 Dashboard 集成 -> 规则页面。
点击页面右上角的创建。
输入规则 ID
my_rule,在 SQL 编辑器中输入规则 SQL 如下:sqlSELECT * FROM "t/#"TIP
如果您初次使用 SQL,可以点击 SQL 示例 和启用调试来学习和测试规则 SQL 的结果。
添加动作,从动作类型下拉列表中选择
Amazon S3,保持动作下拉框为默认的“创建动作”选项,您也可以从动作下拉框中选择一个之前已经创建好的 Amazon S3 动作。此处我们创建一个全新的 Sink 并添加到规则中。在下方的表单中输入 Sink 的名称与描述。
在连接器下拉框中选择刚刚创建的
my-s3连接器。您也可以点击下拉框旁边的创建按钮,在弹出框中快捷创建新的连接器,所需的配置参数可以参考创建连接器。设置存储桶,此处输入
iot-data,此处也支持${var}格式的占位符,但要注意需要在 S3 中预先创建好对应名称的存储桶。根据情况选择 ACL,指定上传对象的访问权限。
选择上传方式,两种方式区别如下:
- 直接上传:每次规则触发时,按照预设的对象键和内容直接上传到 S3,适合存储二进制或体积较大的文本数据。这种方法可能会生成大量的文件。
- 聚合上传:将多次规则触发的结果打包为一个文件(如 CSV 文件)并上传到 S3,适合存储结构化数据。这种方法可以减少文件数量,提高写入效率。
两种方式配置的参数不同,请根据所选方式进行配置:
备选动作(可选):如果您希望在消息投递失败时提升系统的可靠性,可以为 Sink 配置一个或多个备选动作。当 Sink 无法成功处理消息时,这些备选动作将被触发。更多信息请参见:备选动作。
展开高级设置,根据需要配置高级设置选项(可选),详细请参考高级设置。
其余参数使用默认值即可。点击创建按钮完成 Sink 的创建,创建成功后页面将回到创建规则,新的 Sink 将添加到规则动作中。
回到规则创建页面,点击创建按钮完成整个规则创建。
现在您已成功创建了规则,你可以在规则页面上看到新建的规则,同时在动作(Sink) 标签页看到新建的 S3 Sink。
您也可以点击 集成 -> Flow 设计器查看拓扑,通过拓扑可以直观的看到,主题 t/# 下的消息在经过规则 my_rule 解析后被写入到 S3 中。
Parquet 格式选项
当聚合上传文件格式 设置为 parquet 时,EMQX 会将聚合后的规则处理结果以 Apache Parquet 格式存储到目标存储中。Parquet 是一种列式、支持压缩的文件格式,针对大规模分析型工作负载进行了优化。
本节介绍 Parquet 输出格式的可配置参数。
Parquet Schema (Avro)
该选项定义 MQTT 消息字段与 Parquet 文件列之间的映射关系。EMQX 使用 Apache Avro 的 Schema 规范描述 Parquet 数据结构。
可选择以下两种配置方式:
Schema Registry 中已添加的 Avro Schema: 使用已在 EMQX Schema Registry 中注册的 Avro Schema。选择此项时,需要在 Schema 名称 字段中指定已注册的 Schema 名称。EMQX 会在写入 Parquet 文件时自动从注册表中加载对应的 Schema。
TIP
如果你希望集中管理数据结构并保持多系统间 Schema 的一致性,建议使用此方式。
Avro Schema 定义:在 EMQX 中直接定义 Avro Schema。在 Schema 定义字段中输入以 JSON 格式定义的 Avro Schema。
示例:
json{ "type": "record", "name": "MessageRecord", "fields": [ {"name": "clientid", "type": "string"}, {"name": "timestamp", "type": "long"}, {"name": "payload", "type": "string"} ] }TIP
请确保字段名称与规则 SQL 输出字段一致,否则可能导致写入 Parquet 时序列化失败。
Parquet 默认压缩算法
该选项指定用于压缩 Parquet 行组中数据页的默认压缩算法。压缩有助于减少存储空间,并在执行分析查询时提升 I/O 效率。
支持的取值:
| 取值 | 说明 |
|---|---|
snappy(默认) | 压缩速度快、解压高效、压缩率适中。推荐大多数场景使用。 |
zstd | 压缩率更高但 CPU 开销略大,适合大规模或长期存储场景。 |
None | 不使用压缩,仅用于调试或对压缩无需求的情况。 |
Parquet 最大行组大小
该选项指定每个 Parquet 行组的最大缓冲大小(单位:MB)。行组是 Parquet 文件中读写数据的基本单位,当行组大小超过此值时,EMQX 将刷新当前行组并开始新的行组。
- 默认值:
128 MB
使用建议:
- 增大该值可提高分析查询性能;
- 减小该值可降低写入时的内存占用,适合小规模数据。
TIP
Parquet 读取器以行组为单位读取数据。较大的行组可减少元数据开销,从而提升分析查询性能。
测试规则
此处以直接上传为例进行测试。使用 MQTTX 向 t/1 主题发布消息:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "hello S3" }'发送几条消息后,访问 Amazon S3 控制台或 MinIO 控制台查看结果。
高级设置
本节将深入介绍可用于 S3 Sink 的高级配置选项。在 Dashboard 中配置 Sink 时,您可以根据您的特定需求展开高级设置,调整以下参数。
| 字段名称 | 描述 | 默认值 |
|---|---|---|
| 缓存池大小 | 指定缓冲区工作进程数量,这些工作进程将被分配用于管理 EMQX 与 S3 的数据流,它们负责在将数据发送到目标服务之前临时存储和处理数据。此设置对于优化性能并确保 Sink 数据传输顺利进行尤为重要。 | 16 |
| 请求超期 | “请求 TTL”(生存时间)设置指定了请求在进入缓冲区后被视为有效的最长持续时间(以秒为单位)。此计时器从请求进入缓冲区时开始计时。如果请求在缓冲区内停留的时间超过了此 TTL 设置或者如果请求已发送但未能在 S3 中及时收到响应或确认,则将视为请求已过期。 | 45 秒 |
| 健康检查间隔 | 指定 Sink 对与 S3 的连接执行自动健康检查的时间间隔(以秒为单位)。 | 15 秒 |
| 健康检查间隔抖动 | 在健康检查间隔中添加一个均匀的随机延迟(抖动),用于避免多个节点在相同时间触发健康检查请求。当多个 Sink 或 Source 使用同一连接器时,启用抖动可确保它们在不同时间启动健康检查,提升系统稳定性。 | 0 毫秒 |
| 健康检查超时 | 指定对与 S3 Tables 服务的连接执行自动健康检查的超时时间。 | 60 秒 |
| 缓存队列最大长度 | 指定可以由 S3 Sink 中的每个缓冲器工作进程缓冲的最大字节数。缓冲器工作进程在将数据发送到 S3 之前会临时存储数据,充当处理数据流的中介以更高效地处理数据流。根据系统性能和数据传输要求调整该值。 | 256 MB |
| 请求模式 | 允许您选择同步或异步请求模式,以根据不同要求优化消息传输。在异步模式下,写入到 S3 不会阻塞 MQTT 消息发布过程。但是,这可能导致客户在它们到达 S3 之前就收到了消息。 | 异步 |
| 请求飞行队列窗口 | “飞行队列请求”是指已启动但尚未收到响应或确认的请求。此设置控制 Sink 与 S3 通信时可以同时存在的最大飞行队列请求数。 当 请求模式 设置为 异步 时,“请求飞行队列窗口”参数变得特别重要。如果对于来自同一 MQTT 客户端的消息严格按顺序处理很重要,则应将此值设置为 1。 | 100 |
| 最小分片大小 | 聚合完成后的分片上传的最小块大小,上传的数据将在内存中累积,直到达到此大小。 | 5MB |
| 最大分片大小 | 分块上传的最大分块大小。S3 Sink 不会尝试上传超过此大小的分片。 | 5GB |