将 MQTT 数据导入 Snowflake
Snowflake 是一个基于云的数据平台,提供高度可扩展且灵活的数据仓库、分析和安全数据共享解决方案。Snowflake 以其处理结构化和半结构化数据的能力而闻名,专为存储海量数据并提供快速查询性能设计,能够无缝集成各种工具和服务。
本页面详细介绍了 EMQX 与 Snowflake 之间的数据集成,并为规则和 Sink 的创建提供了实用指南。
工作原理
EMQX 中的 Snowflake 数据集成是一项开箱即用的功能,可以轻松配置以满足复杂的业务开发需求。在典型的物联网应用中,EMQX 作为物联网平台,负责设备连接和消息传输,而 Snowflake 作为数据存储和处理平台,负责消息数据的摄取、存储和分析。
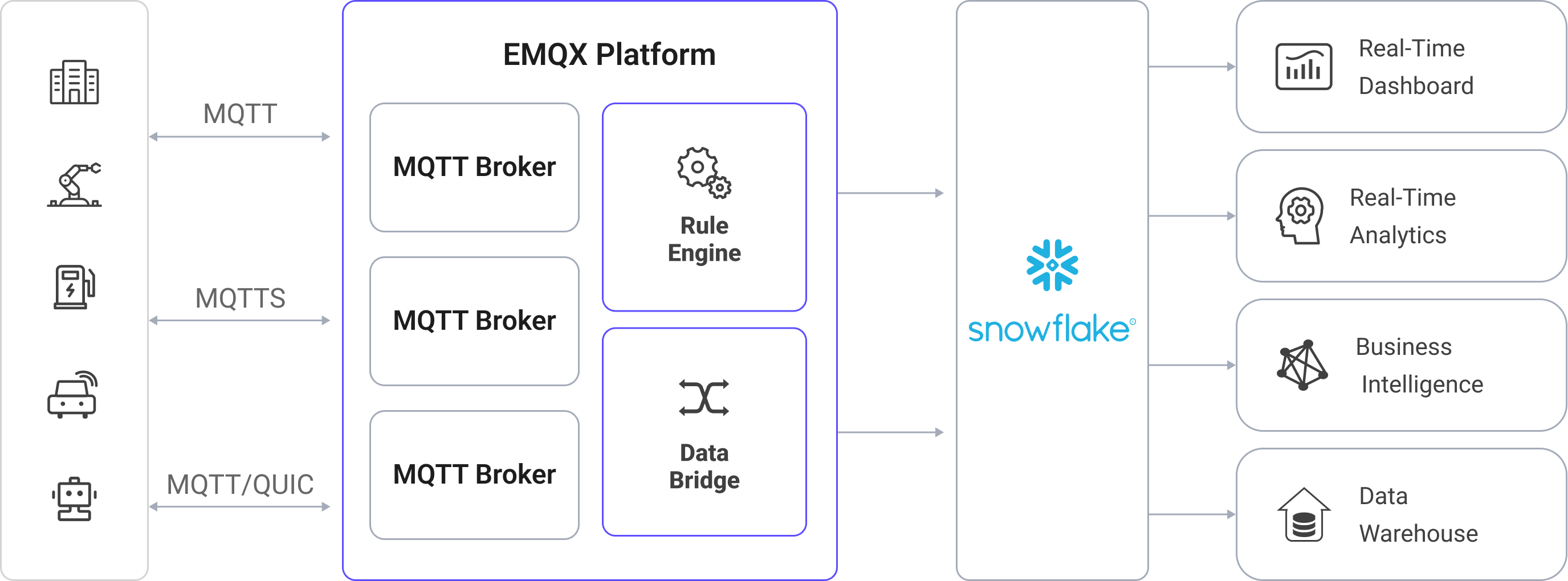
EMQX 利用规则引擎和 Sink 将设备事件和数据转发到 Snowflake。最终用户和应用程序可以访问 Snowflake 表中的数据。具体工作流程如下:
设备连接到 EMQX:物联网设备通过 MQTT 协议成功连接时,会触发在线事件。该事件包括设备 ID、源 IP 地址以及其他属性信息。
设备消息发布与接收:设备通过特定主题发布遥测和状态数据。EMQX 接收这些消息,并通过规则引擎进行匹配。
规则引擎处理消息:内置的规则引擎根据主题匹配处理来自特定来源的消息和事件。它匹配相应的规则并处理消息和事件,如数据格式转换、过滤特定信息或用上下文信息丰富消息。
写入 Snowflake:规则触发一个动作,将消息数据写入 Snowflake。写入方式可以是将消息批量写入文件后,通过存储区 (Stage) 和 Pipe 加载到表中(聚合模式),也可以是通过 Snowpipe Streaming API 实时流式写入(流式模式)。
当事件和消息数据写入 Snowflake 后,可用于各种业务和技术用途,包括:
- 数据归档:将物联网数据安全地存储在 Snowflake 中进行长期归档,确保合规性和历史数据可用性。
- 数据分析:利用 Snowflake 的数据仓库和分析功能,进行实时或批量分析,实现预测性维护、运营洞察和设备性能评估。
功能与优势
在 EMQX 中使用 Snowflake 数据集成可以为您的业务带来以下功能和优势:
- 消息转换:消息可以在写入 Snowflake 之前,通过 EMQX 规则进行深入的处理和转换,便于后续存储和使用。
- 灵活的数据操作:Snowflake Sink 提供了灵活的数据处理方式,允许用户选择特定字段写入 Snowflake,实现根据业务需求的高效、动态存储配置。
- 集成的业务流程:Snowflake Sink 允许将设备数据与 Snowflake 的丰富生态系统应用相结合,支持更多业务场景,如数据分析和归档。
- 低成本的长期存储:Snowflake 的可扩展存储基础设施针对长期数据保留进行了优化,成本比传统数据库更低,是存储海量物联网数据的理想解决方案。
这些功能使您能够构建高效、可靠且可扩展的物联网应用,并从业务决策和优化中获益。
准备工作
本节介绍在 EMQX 中创建 Snowflake Sink 之前所需的准备工作。
前置准备
选择上传模式
TIP
请先选择上传模式,因为它将决定你在 EMQX 和 Snowflake 中的配置方式。
EMQX 支持两种将数据发送到 Snowflake 的方式:
| 上传模式 | 描述 | 是否需要 ODBC |
|---|---|---|
| 聚合 | EMQX 将 MQTT 消息缓存在本地文件中,并上传至 Snowflake 的 Stage。然后由配置了 COPY INTO 语句的管道 (Pipe) 自动将这些文件加载到目标表中。更多详情可参考 Snowflake Snowpipe 文档。 | 是 |
| 流式 | 通过 Snowpipe Streaming API 将数据实时发送至 Snowflake 表,逐行写入。 | 是 |
初始化 Snowflake ODBC 驱动程序
为了使 EMQX 能够与 Snowflake 进行通信并高效传输数据,必须安装并配置 Snowflake 的开放数据库连接(ODBC)驱动程序。它充当数据传输的桥梁,确保数据格式化、身份验证及传输的正确性。
请参考官方文档 ODBC Driver 页面及 Snowflake ODBC Driver License Agreement 获取更多信息。
Linux
运行以下脚本来安装 Snowflake ODBC 驱动程序并配置 odbc.ini 文件:
scripts/install-snowflake-driver.sh注意
该脚本仅用于测试环境,并非生产环境中 ODBC 驱动设置的推荐方式。请参考官方文档 Installing for Linux。
macOS
在 macOS 上安装并配置 Snowflake ODBC 驱动程序,请按照以下步骤操作:
安装 unixODBC,例如:
bashbrew install unixodbc参考 macOS 上的 ODBC 驱动安装和配置说明进行详细的安装和配置。
安装完成后,更新以下配置文件:
更新 Snowflake ODBC 驱动的权限和配置:
bashchown $(id -u):$(id -g) /opt/snowflake/snowflakeodbc/lib/universal/simba.snowflake.ini echo 'ODBCInstLib=libiodbcinst.dylib' >> /opt/snowflake/snowflakeodbc/lib/universal/simba.snowflake.ini创建或更新
~/.odbc.ini文件以配置 ODBC 连接:bashcat << EOF > ~/.odbc.ini [ODBC] Trace=no TraceFile= [ODBC Drivers] Snowflake = Installed [ODBC Data Sources] snowflake = Snowflake [Snowflake] Driver = /opt/snowflake/snowflakeodbc/lib/universal/libSnowflake.dylib EOF
创建用户账户设置 Snowflake 资源
无论使用哪种上传模式,你都需要先配置 Snowflake 环境,包括创建用户账户、数据库以及相关的数据接入资源。以下信息在后续配置 EMQX 的 Connector 和 Sink 时将被使用:
| 字段名 | 值 | 描述 |
|---|---|---|
| 数据源名称 (DSN) | snowflake(仅适用于聚合模式) | 在 /etc/odbc.ini 中配置的 ODBC 数据源,用于聚合模式上传。 |
| 用户名 | snowpipeuser | 用于连接认证的 Snowflake 用户,在两种模式下都需具备相应权限。 |
| 密码 | Snowpipeuser99 | 若使用密钥对认证,则该字段为可选。 |
| 数据库名称 | testdatabase | 存储目标表的 Snowflake 数据库。 |
| 模式 (Schema) | public | 包含目标表和管道的数据库模式。 |
| 存储区(聚合模式) | emqx | Snowflake 中用于临时存放上传文件的 Stage。 |
| 管道(聚合模式) | emqx | 从存储区加载数据至目标表的管道。 |
| 管道(流式模式) | emqxstreaming | 通过 DATA_SOURCE(TYPE => 'STREAMING') 创建的流式管道。 |
| 私钥文件路径 | file://<path to snowflake_rsa_key.private.pem> | 用于 API 认证的 RSA 私钥路径。 |
生成 RSA 密钥对(聚合模式可选)
Snowflake 支持多种认证方式。在 EMQX 中,应根据所选上传模式和连接配置选择合适的认证方式:
| 上传模式 | 支持的认证方式 | 是否必须使用密钥对 |
|---|---|---|
| 流式(HTTPS) | RSA 密钥对 + JWT(唯一支持方式) | 是 |
| 聚合(ODBC) | 用户名/密码(通过 DSN 或直接在 EMQX 中配置) RSA 密钥对 + JWT(可选,仅在 EMQX 中配置) | 否(可选) |
密钥对认证是流式模式下的唯一认证方式,在该模式中,EMQX 使用私钥签发 JWT,用于安全地向 Snowflake Streaming API 认证。
在聚合模式下,你可以选择用户名/密码或 RSA 密钥对中的任一种方式进行认证。具体方法包括:
- 在 EMQX 控制台的 Connector 配置中填写用户名和密码;
- 或填写私钥路径(使用密钥对认证时);
- 或者,如果 EMQX 中未配置认证信息,确保系统的 ODBC DSN 文件(如
/etc/odbc.ini或 macOS 上的~/.odbc.ini)中配置了相应的凭证。
TIP
认证方式二选一:使用密码或私钥,不要同时使用。
如果在 EMQX 中都未配置,则将自动使用 /etc/odbc.ini 中的认证信息。
示例:使用用户名/密码的 ODBC 配置(Linux /etc/odbc.ini)
[snowflake]
Driver=SnowflakeDSIIDriver
Server=<account>.snowflakecomputing.com
UID=snowpipeuser
PWD=Snowpipeuser99
Database=testdatabase
Schema=public
Warehouse=compute_wh
Role=snowpipe采用此方式时,EMQX 可通过配置中的
DSN(如snowflake)间接使用认证信息,而无需显式写入用户名和密码。
如果你使用密钥对认证
若你选择或必须使用 RSA 密钥对认证(如在流式模式中),可使用以下命令生成密钥:
# 生成私钥
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out snowflake_rsa_key.private.pem -nocrypt
# 生成公钥
openssl rsa -in snowflake_rsa_key.private.pem -pubout -out snowflake_rsa_key.public.pem当 EMQX 使用密钥对认证时(在聚合和流式模式中均支持):
- EMQX 使用 RSA 私钥签发 JWT 作为安全、可验证的身份凭证;
- Snowflake 使用预先上传的公钥验证该签名的合法性。
如需了解更多信息,请参考官方文档:Key-pair authentication and key-pair rotation。
使用 SQL 设置 Snowflake 资源
生成 RSA 密钥对后,你需要使用 SQL 命令为聚合或流式模式设置必要的 Snowflake 对象,包括:
- 创建数据库和数据表
- 创建存储区和管道(用于聚合模式)
- 创建流式管道(用于流式模式)
- 创建用户和角色,并授予访问权限
在 Snowflake 控制台中,打开 SQL 工作表并执行以下 SQL 命令来创建数据库、表、存储区和管道:
sqlUSE ROLE accountadmin; -- 创建用于存储数据的数据库(如果不存在) CREATE DATABASE IF NOT EXISTS testdatabase; -- 创建用于接收 MQTT 数据的表 CREATE OR REPLACE TABLE testdatabase.public.emqx ( clientid STRING, topic STRING, payload STRING, publish_received_at TIMESTAMP_LTZ ); -- 创建用于聚合模式的存储区,用于上传文件 CREATE STAGE IF NOT EXISTS testdatabase.public.emqx FILE_FORMAT = (TYPE = CSV PARSE_HEADER = TRUE FIELD_OPTIONALLY_ENCLOSED_BY = '"') COPY_OPTIONS = (ON_ERROR = CONTINUE PURGE = TRUE); -- 创建用于聚合模式的管道,从存储区中复制数据 CREATE PIPE IF NOT EXISTS testdatabase.public.emqx AS COPY INTO testdatabase.public.emqx FROM @testdatabase.public.emqx MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE; -- 创建用于流式模式的管道,直接摄取数据 CREATE PIPE IF NOT EXISTS testdatabase.public.emqxstreaming AS COPY INTO testdatabase.public.emqx ( clientid, topic, payload, publish_received_at ) FROM ( SELECT $1:clientid::STRING, $1:topic::STRING, $1:payload::STRING, $1:publish_received_at::TIMESTAMP_LTZ FROM TABLE(DATA_SOURCE(TYPE => 'STREAMING')) );COPY INTO语句确保 Snowflake 能自动将存储区或 Streaming 中的数据加载到目标表。- 流式管道中的
$1:字段名语法用于从 EMQX 发送的 JSON 数据中提取字段。
创建一个专用于 EMQX 认证的用户(如
snowpipeuser),并绑定 RSA 公钥:sql-- 创建用户账号 CREATE USER IF NOT EXISTS snowpipeuser PASSWORD = 'Snowpipeuser99' MUST_CHANGE_PASSWORD = FALSE; -- 将 RSA 公钥绑定到该用户 ALTER USER snowpipeuser SET RSA_PUBLIC_KEY = ' <YOUR_PUBLIC_KEY_CONTENTS_LINE_1> <YOUR_PUBLIC_KEY_CONTENTS_LINE_2> <YOUR_PUBLIC_KEY_CONTENTS_LINE_3> <YOUR_PUBLIC_KEY_CONTENTS_LINE_4> ';TIP
请移除 PEM 文件中的
-----BEGIN PUBLIC KEY-----和-----END PUBLIC KEY-----行,只保留中间的内容并保持换行。上述密钥将上传至 Snowflake 并绑定到指定用户。
创建并分配所需角色,赋予该用户访问 Snowflake 资源的权限:
sqlCREATE OR REPLACE ROLE snowpipe; -- 授权数据库和表的使用与读写权限 GRANT USAGE ON DATABASE testdatabase TO ROLE snowpipe; GRANT USAGE ON SCHEMA testdatabase.public TO ROLE snowpipe; GRANT INSERT, SELECT ON testdatabase.public.emqx TO ROLE snowpipe; -- 聚合模式需要访问存储区和管道 GRANT READ, WRITE ON STAGE testdatabase.public.emqx TO ROLE snowpipe; GRANT OPERATE, MONITOR ON PIPE testdatabase.public.emqx TO ROLE snowpipe; -- 流式模式需要访问流式管道 GRANT OPERATE, MONITOR ON PIPE testdatabase.public.emqxstreaming TO ROLE snowpipe; -- 将角色授予用户,并设置为默认角色 GRANT ROLE snowpipe TO USER snowpipeuser; ALTER USER snowpipeuser SET DEFAULT_ROLE = snowpipe;
创建 Snowflake 连接器(聚合模式)
如果您计划在 Snowflake Sink 中使用聚合上传模式,则需要创建一个 Snowflake 连接器,以建立与 Snowflake 环境的连接。该连接器通过 ODBC(使用 DSN)连接到 Snowflake 的存储区(Stage)。
进入 Dashboard 集成 -> 连接器页面。
点击右上角的创建按钮。
选择 Snowflake 作为连接器类型,然后点击下一步。
输入连接器名称,由大小写字母和数字组成。这里输入
my-snowflake。输入连接信息:
服务器地址:服务器地址为 Snowflake 的端点 URL,通常格式为
<你的 Snowflake 组织 ID>-<你的 Snowflake 账户名>.snowflakecomputing.com。您需要用自己 Snowflake 实例的子域替换<你的 Snowflake 组织 ID>-<你的 Snowflake 账户名称>。账户:输入您的 Snowflake 组织 ID 和账户名,用连字符(
-)分隔,可以在 Snowflake 控制台中找到该信息,通常也是您访问 Snowflake 平台的 URL 中的一部分。数据源名称:输入
snowflake,与您在 ODBC 驱动设置中配置的.odbc.ini文件中的 DSN 名称相对应。用户名:输入
snowpipeuser,这是之前设置过程中定义的用户名。密码:输入用于通过用户名和密码进行 ODBC 连接认证。此字段为可选项,用户可以选择:
在此处填写密码,例如:
Snowpipeuser99,这是之前设置过程中定义的密码。或在系统的
/etc/odbc.ini文件中配置;如果使用密钥对认证(Key-pair authentication),则无需提供密码。
TIP
使用密码或私钥进行身份验证,而不是两者兼用。如果此处未配置这两种方式,请确保在
/etc/odbc.ini中设置了适当的凭证。
私钥路径: 用于通过 ODBC 认证连接 Snowflake 的 RSA 私钥的绝对文件路径。此路径在集群的所有节点上必须保持一致。例如:
/etc/emqx/certs/snowflake_rsa_key.private.pem。私钥密码:用于解密 RSA 私钥文件的密码(如果该私钥已加密)。如果私钥是在未加密的情况下生成的(例如使用 OpenSSL 的
-nocrypt选项),则此字段应留空。代理:用于通过 HTTP 代理服务器连接到 Snowflake 的配置。不支持 HTTPS 代理。默认情况下不使用代理。若需启用代理支持,请选择
开启代理并填写以下信息:- 代理主机:代理服务器的主机名或 IP 地址。
- 代理端口:代理服务器使用的端口号。
如果您想建立一个加密连接,单击启用 TLS 切换按钮。有关 TLS 连接的更多信息,请参见启用 TLS 加密访问外部资源。流式模式必须启用 TLS,因为通信是通过 HTTPS 进行的。
高级配置(可选),请参考高级设置。
在点击创建之前,可以点击测试连接来测试连接器是否能够连接到 Snowflake。
点击页面底部的创建按钮,完成连接器创建。
现在,您已经成功创建了连接器,可以继续创建规则,以指定如何将数据写入 Snowflake。
创建 Snowflake Streaming 连接器
如果您计划在 Snowflake Sink 中使用流式上传模式,则需要创建一个 Snowflake Streaming 连接器,以建立与 Snowflake 环境的连接。该连接器通过 HTTPS 和 Snowpipe Streaming REST API 进行连接。
进入 Dashboard 集成 -> 连接器页面。
点击右上角的创建按钮。
选择 Snowflake 作为连接器类型,然后点击下一步。
输入连接器名称,由大小写字母和数字组成。这里输入
my-snowflake-streaming。输入连接信息:
- 服务器地址:服务器地址为 Snowflake 的端点 URL,通常格式为
<你的 Snowflake 组织 ID>-<你的 Snowflake 账户名>.snowflakecomputing.com。您需要用自己 Snowflake 实例的子域替换<你的 Snowflake 组织 ID>-<你的 Snowflake 账户名称>。 - 账户:输入您的 Snowflake 组织 ID 和账户名,用连字符(
-)分隔,可以在 Snowflake 控制台中找到该信息,通常也是您访问 Snowflake 平台的 URL 中的一部分。 - 用户名:(可选)如果您在
odbc.ini中已配置,在此输入绑定了 RSA 公钥的 Snowflake 用户名(如snowpipeuser)。 - 私钥路径: EMQX 使用此 RSA 私钥签发 JWT 令牌,用于向 Snowflake API 进行身份认证。您可以直接将完整的 PEM 格式私钥内容粘贴为字符串,或指定私钥文件的路径,路径需以
file://开头,例如:/etc/emqx/certs/snowflake_rsa_key.private.pem。 - 私钥密码:用于解密 RSA 私钥文件的密码(如果该私钥已加密)。如果私钥是在未加密的情况下生成的(例如使用 OpenSSL 的
-nocrypt选项),则此字段应留空。 - 代理:用于通过 HTTP 代理服务器连接到 Snowflake 的配置。不支持 HTTPS 代理。默认情况下不使用代理。若需启用代理支持,请选择
开启代理并填写以下信息:- 代理主机:代理服务器的主机名或 IP 地址。
- 代理端口:代理服务器使用的端口号。
- 服务器地址:服务器地址为 Snowflake 的端点 URL,通常格式为
如果您想建立一个加密连接,单击启用 TLS 切换按钮。有关 TLS 连接的更多信息,请参见启用 TLS 加密访问外部资源。流式模式必须启用 TLS,因为通信是通过 HTTPS 进行的。
高级配置(可选),请参考高级设置。
在点击创建之前,可以点击 测试连接 来测试连接器是否能够连接到 Snowflake。
点击页面底部的创建按钮,完成连接器创建。
现在,您已经成功创建了连接器,可以继续创建规则,以指定如何将数据写入 Snowflake。
创建 Snowflake 规则
本节演示如何在 EMQX 中创建规则,以处理消息(例如,来自源 MQTT 主题 t/#),并通过配置的 Sink 将规则处理结果写入 Snowflake。
创建规则并配置规则处理 SQL
进入 Dashboard 集成 -> 规则页面。
点击右上角的创建按钮。
输入规则 ID
my_rule,并在 SQL 编辑器中输入以下规则 SQL:sqlSELECT clientid, unix_ts_to_rfc3339(publish_received_at, 'millisecond') as publish_received_at, topic, payload FROM "t/#"TIP
如果您不熟悉 SQL,可以通过点击 SQL 示例和启用调试来学习和测试规则 SQL 的结果。
TIP
对于 Snowflake 集成,选择的字段必须与在 Snowflake 中定义的表的列名和数量完全匹配,因此避免 SELECT
*或添加额外的字段。为规则添加动作输出。
- 如果您想要使用聚合上传模式将规则处理结果写入 Snowflake,参考添加使用聚合上传模式的 Snowflake Sink。
- 如果您想要使用流式上传模式将规则处理结果写入 Snowflake,参考添加使用流式上传模式的 Snowflake Sink。
动作添加完成后,您可以看到新添加的 Sink 出现在动作输出栏下。点击创建规则页面上的保存按钮完成整个规则创建过程。
现在,您已成功创建了规则。您可以在规则页面看到新创建的规则,并在动作 (Sink) 标签页中查看新创建的 Snowflake Sink。
您还可以点击集成 -> Flow 设计器来查看拓扑图,拓扑图可视化显示了主题 t/# 下的消息在经过规则 my_rule 解析后如何写入 Snowflake。
添加使用聚合上传模式的 Snowflake Sink
本节演示了为规则添加一个使用聚合上传模式的 Sink,将规则处理结果写入 Snowflake。该模式会将多次规则触发的结果合并到一个文件(例如 CSV 文件)中,再上传至 Snowflake,从而减少文件数量并提升写入效率。
在创建规则页面右侧点击添加动作按钮,从动作类型下拉列表中选择
Snowflake,将动作下拉选项保留为默认的创建动作,或从下拉列表中选择之前创建的 Snowflake 动作。此示例将创建一个新的 Sink 并将其添加到规则中。输入 Sink 的名称(例如
snowflake_sink)和简短描述。从连接器下拉列表中选择之前创建的
my-snowflake连接器。您也可以点击下拉列表旁的创建按钮,在弹出的对话框中快速创建新的连接器。所需的配置参数请参考创建 Snowflake 连接器(聚合模式)。配置以下 Sink 选项:
数据库名字:输入
testdatabase,这是为存储 EMQX 数据而创建的 Snowflake 数据库。模式:输入
public,这是testdatabase中的数据表所在的模式 (Schema) 名称。存储区:输入
emqx,这是在 Snowflake 中预先创建的用于临时存储数据的存储区 (Stage) 名称。管道:输入
emqx,这是用于将数据从存储区自动加载到表中的管道。管道用户:输入
snowpipeuser,这是具有管理该管道权限的 Snowflake 用户。私钥:管道用户用于安全访问 Snowflake 管道的 RSA 私钥。您可以通过以下两种方式之一提供该密钥:
- 明文内容:直接粘贴完整的 PEM 格式私钥内容,作为字符串填写。
- 文件路径:指定私钥文件的路径,路径需以
file://开头。例如:file:///etc/emqx/certs/snowflake_rsa_key.private.pem。该路径在集群所有节点上必须保持一致,并确保 EMQX 应用用户具备读取权限。
私钥密码:用于解密 RSA 私钥文件的密码(如果该私钥已加密)。如果私钥是在未加密的情况下生成的(例如使用 OpenSSL 的
-nocrypt选项),则此字段应留空。聚合上传文件格式:目前仅支持
csv。数据将以逗号分隔的 CSV 格式存储到 Snowflake。列排序:从下拉列表中选择列的顺序,生成的 CSV 文件将首先按选定的列排序,未选定的列将按字母顺序排序。
最大记录数:设置触发聚合前的最大记录数。例如,您可以设置为
1000,在收集 1000 条记录后触发上传。当达到最大记录数时,单个文件的聚合将完成并上传,重置时间间隔。时间间隔:设置触发聚合的时间间隔(秒)。例如,如果设置为
60,即使未达到最大记录数,也将在 60 秒后上传数据,并重置记录数。代理:用于通过 HTTP 代理服务器连接到 Snowflake 的配置。不支持 HTTPS 代理。默认情况下不使用代理。若需启用代理支持,请选择
开启代理并填写以下信息:- 代理主机:代理服务器的主机名或 IP 地址。
- 代理端口:代理服务器使用的端口号。
备选动作(可选):如果您希望在消息投递失败时提升系统的可靠性,可以为 Sink 配置一个或多个备选动作。当 Sink 无法成功处理消息时,这些备选动作将被触发。更多信息请参见:备选动作。
展开高级设置,根据需要配置高级设置选项(可选)。更多详细信息请参考高级设置。
点击添加按钮完成 Sink 创建。成功创建后,页面将返回到规则创建页面,并将新创建的 Sink 添加到规则动作中。
添加使用流式上传模式的 Snowflake Sink
本节演示了为规则添加一个使用流式上传模式的 Sink,将规则处理结果写入 Snowflake。此模式使用 Snowpipe Streaming API 实现实时写入。
在创建规则页面右侧点击添加动作按钮,从动作类型下拉列表中选择
Snowflake-Streaming,将动作下拉选项保留为默认的创建动作,或从下拉列表中选择之前创建的 Snowflake 动作。此示例将创建一个新的 Sink 并将其添加到规则中。输入 Sink 的名称(例如
snowflake_sink_streaming)和简短描述。从连接器下拉列表中选择之前创建的
my-snowflake-streaming连接器。您也可以点击下拉列表旁的创建按钮,在弹出的对话框中快速创建新的连接器。所需的配置参数请参考创建 Snowflake Streaming 连接器。配置以下 Sink 选项:
- 数据库名字:输入
testdatabase,这是为存储 EMQX 数据而创建的 Snowflake 数据库。 - 模式:输入
public,这是testdatabase中的数据表所在的模式 (Schema) 名称。 - 管道:输入
emqxstreaming,该名称需与在 Snowflake 中创建的流式管道名称完全一致。 - HTTP 流水线:在等待响应之前可以发送的最大 HTTP 请求数。默认值:
100。 - 连接超时:建立与 Snowflake 的连接的最长等待时间,超过此时间将中止连接尝试。默认值:
15秒。 - 连接池大小:EMQX 为此 Sink 与 Snowflake 保持的最大并发连接数。默认值:
8。 - 最大空闲时间:空闲连接在被关闭前允许保持打开状态的最长时间。默认值:
10秒。
- 数据库名字:输入
备选动作(可选):如果您希望在消息投递失败时提升系统的可靠性,可以为 Sink 配置一个或多个备选动作。当 Sink 无法成功处理消息时,这些备选动作将被触发。更多信息请参见:备选动作。
展开高级设置,根据需要配置高级设置选项(可选)。更多详细信息请参考高级设置。
其余设置保持默认值,点击创建按钮完成 Sink 创建。成功创建后,页面将返回到规则创建页面,并将新创建的 Sink 添加到规则动作中。
测试规则
本节介绍如何测试已配置的规则。
发布测试消息
使用 MQTTX 向主题 t/1 发布一条消息:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "Hello Snowflake" }'重复此步骤几次以生成多条测试消息。
验证 Snowflake 中的数据
发送测试消息后,您可以通过访问 Snowflake 实例并查询目标表来验证数据是否成功写入 Snowflake。
打开 Snowflake Web 界面,并使用您的凭据登录 Snowflake 控制台。
在 Snowflake 控制台中,执行以下 SQL 查询,查看通过规则写入
emqx表的数据:sqlSELECT * FROM testdatabase.public.emqx;此查询将显示上传到
emqx表的所有记录,包括clientid、topic、payload和publish_received_at字段。您应该能够看到所发送的测试消息,例如消息内容
{ "msg": "Hello Snowflake" },以及其他元数据,如主题和时间戳。
高级设置
本节深入介绍 Snowflake Sink 的高级配置选项。在 Dashboard 中配置 Sink 时,可以展开高级设置,根据您的具体需求调整以下参数。
| 字段名称 | 描述 | 默认值 |
|---|---|---|
| 缓存池大小 | 指定缓冲工作进程的数量,这些进程用于管理 EMQX 与 Snowflake 之间的数据流。缓冲进程在数据发送到目标服务之前临时存储和处理数据,对于优化性能和确保数据传输的顺畅至关重要。 | 16 秒 |
| 请求超期 | “请求超期”(生存时间)配置指定请求在进入缓冲区后被视为有效的最长持续时间(以秒为单位)。计时器从请求进入缓冲区时开始,如果请求在超过 TTL 时间后仍未发送或未收到来自 Snowflake 的响应或确认,该请求将被视为已过期。 | 45 秒 |
| 健康检查间隔 | 指定 Sink 与 Snowflake 之间自动进行健康检查的时间间隔(以秒为单位)。 | 15 秒 |
| 健康检查间隔抖动 | 在健康检查间隔中添加一个均匀的随机延迟(抖动),用于避免多个节点在相同时间触发健康检查请求。当多个 Sink 或 Source 使用同一连接器时,启用抖动可确保它们在不同时间启动健康检查,提升系统稳定性。 | 15 秒 |
| 健康检查超时 | 指定对与 Snowflake 服务的连接执行自动健康检查的超时时间。 | 60 秒 |
| 缓存队列最大长度 | 指定每个缓冲工作进程在 Snowflake Sink 中可以缓冲的最大字节数。缓冲工作进程临时存储数据,以便更有效地处理数据流。在系统性能和数据传输要求下,可以调整此值。 | 256 MB |
| 请求模式 | 允许您在 同步 和 异步 请求模式之间进行选择,以根据不同需求优化消息传输。在异步模式下,写入 Snowflake 不会阻塞 MQTT 消息的发布过程,但这可能会导致客户端在消息到达 Snowflake 之前就收到消息。 | 异步 |
| 最大批量请求大小 | 指定从 EMQX 向 Snowflake 传输数据时的单次传输最大数据批大小。通过调整批处理大小,您可以微调 EMQX 和 Snowflake 之间数据传输的效率和性能。 如果将“批处理大小”设置为 "1",则数据记录将单独发送,而不会被分组为批处理。 | 100 |
| 请求飞行队列窗口 | “在途请求队列”指已启动但尚未收到响应或确认的请求。此设置控制 Sink 与 Snowflake 通信期间同时存在的最大在途请求数量。 当请求模式设置为 异步 时,“在途请求队列窗口”参数尤其重要。如果需要严格按顺序处理来自同一 MQTT 客户端的消息,则应将此值设置为 1。 | 100 |