将 MQTT 数据导入 BigQuery
BigQuery 是一个企业级数据仓库,适用于处理大量关系型结构化数据。它针对大规模、临时性的基于 SQL 的分析和报表进行了优化,非常适合用于获取组织层面的业务洞察。EMQX 支持与 BigQuery 的无缝集成,可实现对 MQTT 数据的实时提取、处理与分析。
本页面详细介绍了 EMQX 与 BigQuery 之间的数据集成,并为规则和 Sink 的创建提供了实用指南。
工作原理
BigQuery 数据集成是 EMQX 提供的开箱即用功能,旨在帮助用户将 MQTT 数据流无缝集成到 Google Cloud 中,并利用其丰富的服务和能力来构建物联网应用。
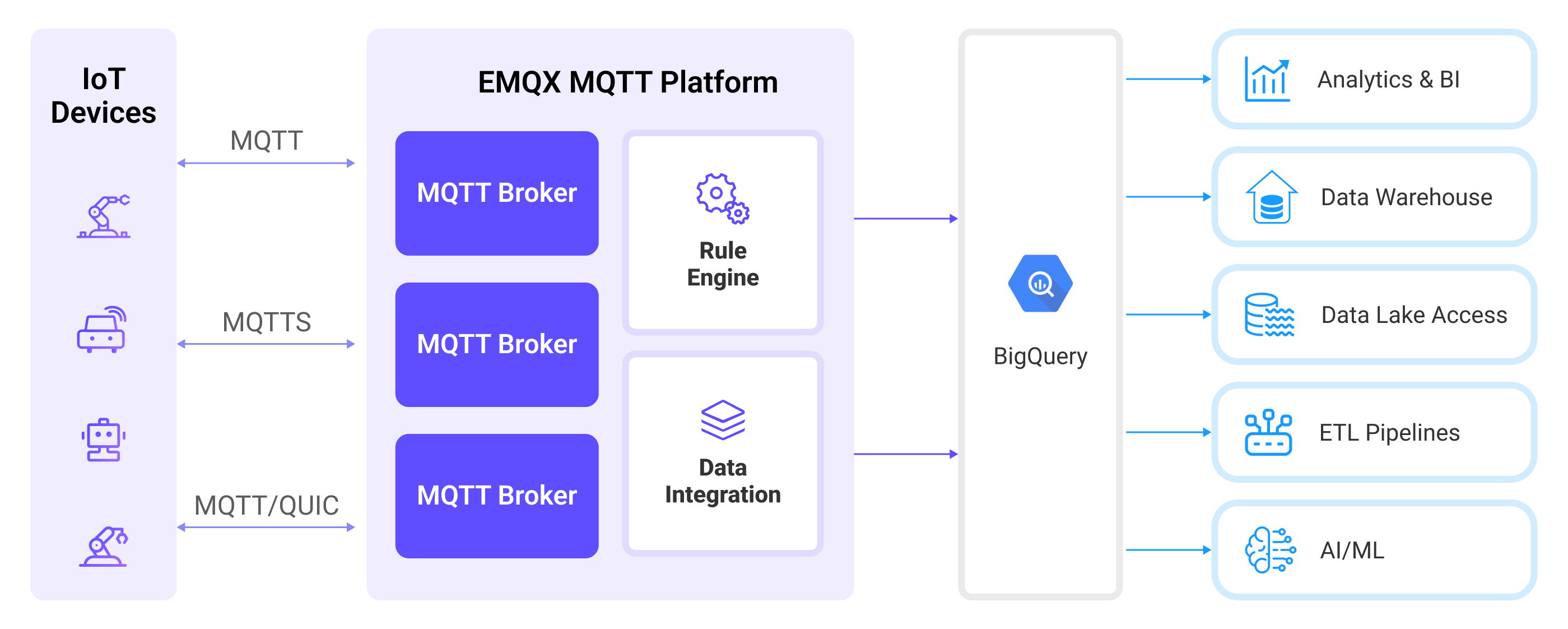
EMQX 通过规则引擎和 Sink 将 MQTT 数据转发至 BigQuery,完整流程如下:
- 物联网设备发布消息:设备通过特定的主题发布遥测数据和状态信息,从而触发规则引擎。
- 规则引擎处理消息:利用内置规则引擎,根据主题匹配处理来自特定来源的 MQTT 消息。规则引擎会匹配对应的规则,并对消息进行处理,例如转换数据格式、过滤特定信息,或添加上下文信息以丰富消息内容。
- 桥接至 BigQuery:规则会触发将消息转发至 BigQuery 的动作,支持轻松配置数据属性、排序键,以及将 MQTT 主题映射到 BigQuery 表字段。这提供了更丰富的上下文信息和数据顺序保证,使物联网数据处理更加灵活高效。
特性与优势
将 EMQX 与 BigQuery 集成,可构建一个强大、可扩展、支持实时处理的 MQTT 数据管道。以下功能特性和优势有助于简化物联网数据分析和数据驱动的决策过程:
- 实时数据摄取:将 MQTT 消息从 EMQX 低延迟地流式传输到 BigQuery,支持对物联网数据进行即时处理与分析,满足对时效性要求较高的应用场景。
- 灵活的数据映射:支持自定义将 MQTT 主题和消息负载映射到 BigQuery 表及字段的方式,适应不同数据结构需求。
- 可扩展的无服务器分析能力:利用 BigQuery 完全托管的无服务器架构,在无需管理基础设施的情况下对大规模 IoT 数据进行分析。
- 轻松集成 Google Cloud 生态:原生兼容 Google Cloud 服务,如 Data Studio、Looker 和 AI Platform,支持可视化分析与机器学习,帮助轻松构建从数据采集到洞察输出的端到端处理流程。
准备工作
本节描述了在 EMQX Dashboard 上配置 BigQuery 集成需要完成的准备工作。
前置准备
创建服务账户凭证
为了使 EMQX 能够连接到 BigQuery 服务,您需要在 Google Cloud 中创建一个服务账户,并生成一个 JSON 格式的密钥。
在您的 GCP 账户中创建一个服务账户。确保该服务账号拥有访问所需数据集和数据表的权限。例如,您可以授予其 “BigQuery Data Editor” 角色,以便对相关数据集或数据表进行读写操作,或者至少确保其具备读取和写入数据的权限。
点击您创建的服务账户的电子邮件地址。然后,点击密钥选项卡。在添加密钥下拉列表中,选择创建新密钥,为该账户生成一个服务账户密钥,并以 JSON 格式下载。
TIP
请妥善存储服务账户密钥,以便后续使用。
配置工作负载身份联合
工作负载身份联合(WIF)允许 EMQX 无需持有服务账号密钥文件即可访问 GCP 资源。EMQX 将从外部身份提供商(如 Microsoft Azure)获取的 token 通过 GCP Security Token Service 换取临时 GCP token,再凭此模拟指定的 GCP 服务账号。Token 续期由 EMQX 自动处理。
要使用 WIF,请在创建连接器之前在 GCP 项目中完成以下配置。
在 Google Cloud 控制台中,进入 IAM 和管理 -> 工作负载身份联合,创建一个工作负载身份池,并记录池 ID 和项目编号。
向该池添加提供商并记录提供商 ID。如使用基于 OIDC 的认证,请从外部身份提供商处获取 OAuth 2.0 客户端凭证(客户端 ID、客户端密钥和令牌端点 URI)。
授予工作负载身份池权限,使其能够模拟具有 BigQuery 数据集和数据表访问权限的 GCP 服务账号。配置连接器时需要填写服务账号的电子邮件地址。
TIP
详细配置步骤请参阅 配置工作负载身份联合。
示例:Microsoft Azure(Entra ID)
在 Microsoft Entra ID 中注册一个公开 API 的应用程序,并为其创建客户端密钥。配置连接器时使用以下值:
| 连接器字段 | 值 |
|---|---|
| OAuth Token 端点 URI | https://login.microsoftonline.com/<租户 ID>/oauth2/v2.0/token |
| OAuth 客户端 ID | 应用程序(客户端)ID,格式为 api://<应用程序 ID> |
| OAuth 客户端密钥 | 为该应用程序生成的客户端密钥 |
| OAuth 请求范围 | api://<应用程序 ID>/.default |
注意
OAuth 请求范围必须与应用程序的受众(aud)完全匹配,否则与 GCP STS 的令牌交换将会失败。详情请参阅 Microsoft 文档中的 OAuth 2.0 客户端凭证流。
向 WIF 池授予服务账号访问权限时,请使用对象 ID(而非应用程序 ID)作为主体标识符(Subject)。对象 ID 显示在 Azure 门户企业应用程序下对应应用的概述页面中。
在 GCP 中创建和管理数据集与数据表
在配置 EMQX 的 BigQuery 数据集成之前,您需要在 GCP 中创建所需的数据集和数据表,并了解其基本管理操作。
在 Google Cloud 控制台中,进入 BigQuery -> Studio 页面。 如需详细指导,请参阅使用 Google Cloud 控制台加载和查询数据教程。
TIP
服务账号必须拥有对目标数据集中的表进行写入的权限。
在探索器面板中,点击项目名称旁的三点图标(⋮),然后选择创建数据集。设置数据集名称并点击创建数据集。
在探索器面板中,点击刚刚创建的数据集,然后点击 (+)创建表。
将数据源设置为空表。
指定表名称。
定义表的架构,例如点击以文本方式编辑,并粘贴如下架构配置:
clientid:string,payload:bytes,topic:string,publish_received_at:timestamp点击创建表完成表的创建。
配置权限以允许 EMQX 写入数据:
- 点击数据集名称,然后点击共享。
- 添加服务账号的邮箱作为 principal(主体)。
- 分配相应的角色,例如:
- 数据集授予 BigQuery Data Viewer(只读权限)
- 表授予 Editor 或 BigQuery Data Editor(读写权限)
点击数据表,然后点击查询。通过 SQL 语句查询表中的数据,例如:
sqlSELECT * FROM `my_project.my_dataset.my_tab` LIMIT 1000
创建 BigQuery 连接器
在添加 BigQuery 生产者 Sink 动作之前,您需要先创建一个 BigQuery 连接器,以建立 EMQX 与 BigQuery 之间的连接。
- 进入 EMQX Dashboard,点击集成 -> 连接器。
- 点击页面右上角的创建按钮,在连接器选择页面中选择 BigQuery,然后点击下一步。
- 输入连接器名称和描述,例如
my_bigquery。此名称用于将 BigQuery Sink 与该连接器关联,且在集群内必须唯一。 - 在认证下拉菜单中选择以下认证方式之一并填写相应字段:
- 服务账号 JSON:上传您在创建服务账户凭证步骤中导出的 JSON 格式服务账户凭证。
- 工作负载身份联合 (WIF):填写以下字段。此方式无需服务账号 JSON 文件。前置条件请参见配置工作负载身份联合。
- GCP 项目 ID:连接器所访问资源的 GCP 项目 ID。
- GCP 项目编号:连接器所访问资源的 GCP 项目编号。
- 服务账号邮箱:需要模拟的服务账号电子邮件地址。
- 工作负载身份池 ID:WIF 令牌交换中使用的工作负载身份池 ID。
- 工作负载身份提供商 ID:WIF 令牌交换中使用的工作负载身份提供商 ID。
- 凭证类型:外部身份提供商使用的凭证类型,目前支持 OIDC 客户端凭证,选择后填写以下字段:
- OAuth 客户端 ID:用于向 OAuth 服务器请求令牌的客户端 ID。
- OAuth 客户端密钥:用于向 OAuth 服务器请求令牌的客户端密钥。
- OAuth Token 端点 URI:OIDC 提供商的 OAuth Token 端点 URI。
- OAuth 请求范围:向 OAuth 服务器请求访问令牌时指定的
scope(如提供商要求则需填写)。
- 在点击创建之前,您可以点击测试连接按钮,测试连接器是否能够成功连接到 BigQuery 服务。
- 点击页面底部的创建按钮完成连接器的创建。 在弹出的对话框中,您可以选择点击返回连接器列表,或点击创建规则,继续创建包含 Sink 的规则,以指定要转发到 BigQuery 的数据。 有关详细步骤,请参阅创建 BigQuery Sink 规则。
创建 BigQuery Sink 规则
本节将演示如何创建一条包含 BigQuery Sink 的规则,用于指定要保存到 BigQuery 的数据。
在 EMQX Dashboard 中点击集成 -> 规则。
点击页面右上角的创建按钮。
在规则 ID 中输入
my_rule。在 SQL 编辑器中设置规则。如果您希望将主题为
t/bq的 MQTT 消息保存到 BigQuery,可以使用如下 SQL 语法:注意:如果您想自定义 SQL 语句,请确保
SELECT部分包含 Sink 中模板所需的所有字段。sqlSELECT clientid, topic, payload, publish_received_at FROM "t/bq"提示
请确保只选择那些在 BigQuery 表中已定义的字段,否则 BigQuery 无法识别未知字段。
TIP
如果您是初学者用户,可以点击 SQL 示例和启用测试来学习和测试规则 SQL。
点击添加动作按钮,为该规则定义一个触发动作。从动作类型下拉框中选择
BigQuery,使 EMQX 将规则处理后的数据发送到 BigQuery。保持动作下拉框中的值为
创建动作。您也可以选择一个之前创建的 BigQuery Sink。本示例中我们将创建一个新的 Sink 并添加到规则中。在名称字段中,为该 Sink 输入一个名称。名称可包含大小写字母和数字组合。
在连接器下拉框中选择之前创建的
my_bigquery。您也可以点击下拉框旁的按钮新建一个连接器。关于配置参数的说明,请参阅创建连接器。在数据集和表字段中,填写您在在 GCP 中创建和管理数据集与数据表中创建的名称。
备选动作(可选):如果您希望在消息投递失败时提升系统的可靠性,可以为 Sink 配置一个或多个备选动作。当 Sink 无法成功处理消息时,这些备选动作将被触发。更多信息请参见:备选动作。
高级设置(可选):更多详细说明,请参阅 高级设置。
在点击创建之前,您可以先点击测试连接,验证连接器是否能够成功连接到 BigQuery 服务。
点击创建按钮完成 Sink 的配置。新创建的 Sink 将显示在动作输出标签下。
返回创建规则页面,点击创建按钮以创建该规则。
现在您已成功创建了规则。您可以在集成 -> 规则页面看到新建的规则。点击动作(Sink) 标签,即可看到新添加的 BigQuery Sink。
您也可以点击集成 -> Flow 设计器查看拓扑图,在图中可以看到主题 t/bq 的消息经过规则 my_rule 处理后被发送并保存到 BigQuery 中。
测试规则
使用 MQTTX 向主题
t/bq发送消息:bashmqttx pub -i emqx_c -t t/bq -m '{ "msg": "hello BigQuery" }'检查 Sink 的运行状态,此时应能看到一条新的传入消息和一条新的传出消息。
登录 GCP 控制台,进入 BigQuery -> Studio,点击您的数据表,然后点击查询 并执行查询语句,您应该可以看到刚发送的消息。
高级设置
本节深入介绍 BigQuery Sink 的高级配置选项。在 Dashboard 中配置 Sink 时,可以展开高级设置,根据您的具体需求调整以下参数。
| 字段名称 | 描述 | 默认值 |
|---|---|---|
| 缓存池大小 | 指定缓冲工作进程的数量,这些进程用于管理 EMQX 与 BigQuery 之间的数据流。缓冲进程在数据发送到目标服务之前临时存储和处理数据,对于优化性能和确保数据传输的顺畅至关重要。 | 16 |
| 请求超期 | “请求超期”(生存时间)配置指定请求在进入缓冲区后被视为有效的最长持续时间(以秒为单位)。计时器从请求进入缓冲区时开始,如果请求在超过 TTL 时间后仍未发送或未收到来自 BigQuery 的响应或确认,该请求将被视为已过期。 | 45 秒 |
| 健康检查间隔 | 指定 Sink 与 BigQuery 之间自动进行健康检查的时间间隔(以秒为单位)。 | 15 秒 |
| 健康检查间隔抖动 | 在健康检查间隔中添加一个均匀的随机延迟(抖动),用于避免多个节点在相同时间触发健康检查请求。当多个 Sink 或 Source 使用同一连接器时,启用抖动可确保它们在不同时间启动健康检查,提升系统稳定性。 | 0 毫秒 |
| 健康检查超时 | 指定对与 BigQuery 服务的连接执行自动健康检查的超时时间。 | 60 秒 |
| 缓存队列最大长度 | 指定每个缓冲工作进程在 BigQuery Sink 中可以缓冲的最大字节数。缓冲工作进程临时存储数据,以便更有效地处理数据流。在系统性能和数据传输要求下,可以调整此值。 | 256 MB |
| 请求模式 | 允许您在 同步 和 异步 请求模式之间进行选择,以根据不同需求优化消息传输。在异步模式下,写入 BigQuery 不会阻塞 MQTT 消息的发布过程,但这可能会导致客户端在消息到达 BigQuery 之前就收到消息。 | 异步 |
| 最大批量请求大小 | 指定从 EMQX 向 BigQuery 传输数据时的单次传输最大数据批大小。通过调整批处理大小,您可以微调 EMQX 和 BigQuery 之间数据传输的效率和性能。 如果将“批处理大小”设置为 "1",则数据记录将单独发送,而不会被分组为批处理。 | 1000 |
| 请求飞行队列窗口 | “在途请求队列”指已启动但尚未收到响应或确认的请求。此设置控制 Sink 与 BigQuery 通信期间同时存在的最大在途请求数量。 当请求模式设置为 异步 时,“在途请求队列窗口”参数尤其重要。如果需要严格按顺序处理来自同一 MQTT 客户端的消息,则应将此值设置为 1。 | 100 |