GPT-Realtime 概述
GPT-Realtime 是 OpenAI 开发的能够实时接收语音输入并生成语音输出的多模态实时模型。该模型使用语音数据集进行训练,使用上更加贴近人类的语音交流习惯。
该模型具有以下特点:
- 协议上: 支持 WebRTC, WebSocket 和 SIP 协议,实时处理文字和语音输入并流式给出回答。
- 对话体验上: 延迟低、语音合成自然流畅、对话中可以处理多次被打断的情况,更加贴近人类对话体验。
- 函数调用和工具能力: 支持工具调用和 MCP 工具。
- 开发体验上: 在 WebRTC 协议方面,支持两种级别的集成方式:Voice Agents SDK(封装更高层次的能力,开箱即用)和 WebRTC SDK(更底层的音视频传输能力,可自定义程度高)。
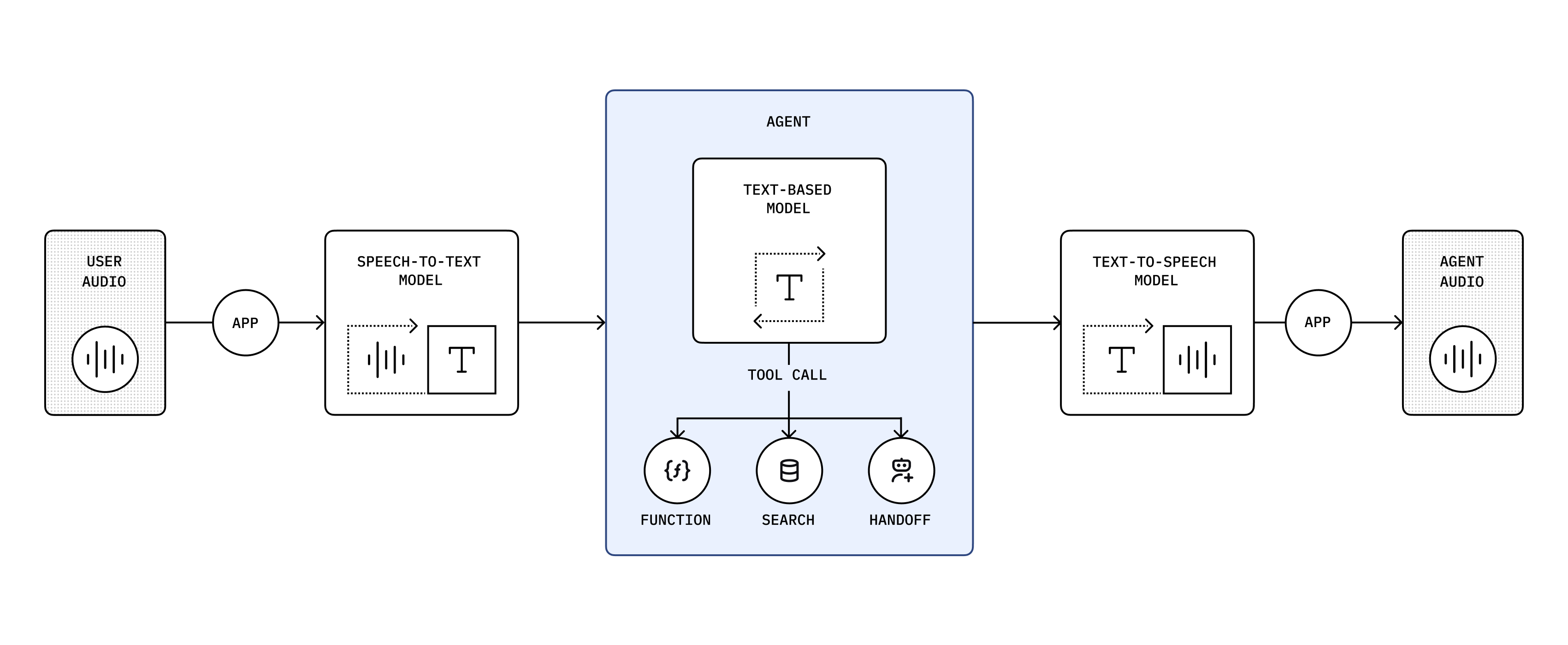
其他串联多种类型模型的 RTC 实时语音方案
在传统的 RTC 实时语音方案中,通常需要将多种类型的模型串联起来完成语音交互功能:首先将语音转录为文字,再输入给大模型处理,最后将大模型的输出合成为语音推送给用户。
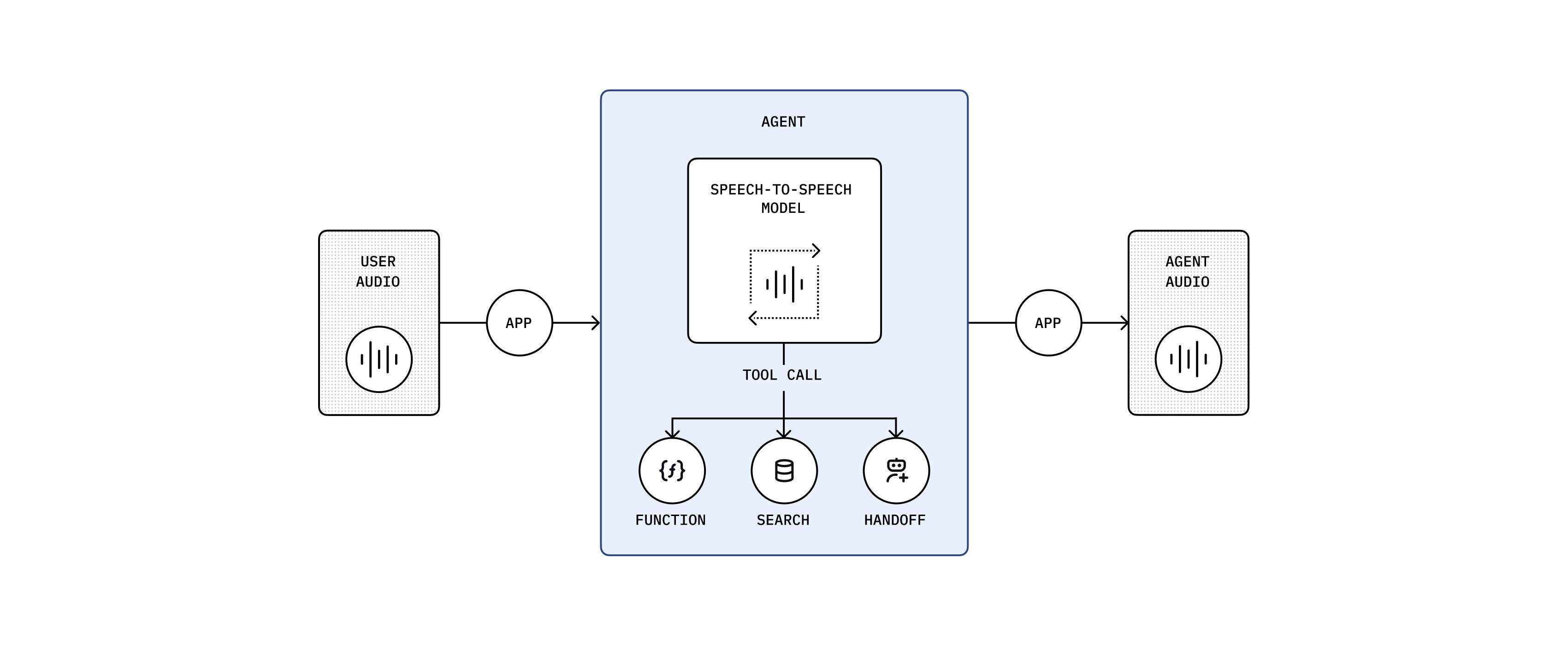
GPT-Realtime 将多种能力集成在单一模型中
GPT-Realtime 模型不再需要串联多种类型的模型,而是将整个过程都在单个模型内部完成,因此它的端到端延迟非常低。