将 MQTT 数据导入 Databricks
Databricks 是一个基于 Apache Spark 构建的统一数据分析平台,专为大规模数据工程、机器学习和协作分析而设计。EMQX 通过将 MQTT 数据写入 Databricks 管理的 Amazon S3 存储桶来实现与 Databricks 的集成,Databricks 可通过外部位置(External Location)直接查询该存储桶中的数据。
本页详细介绍了 EMQX 与 Databricks 的数据集成,并提供了连接器和 Sink 创建的实用指导。
工作原理
Databricks 数据集成基于 EMQX 的 Amazon S3 集成实现。EMQX 将 MQTT 数据写入 Databricks 工作区管理的 S3 存储桶,Databricks 通过外部位置访问该存储桶,从而可以直接使用 SQL 查询存储的数据。
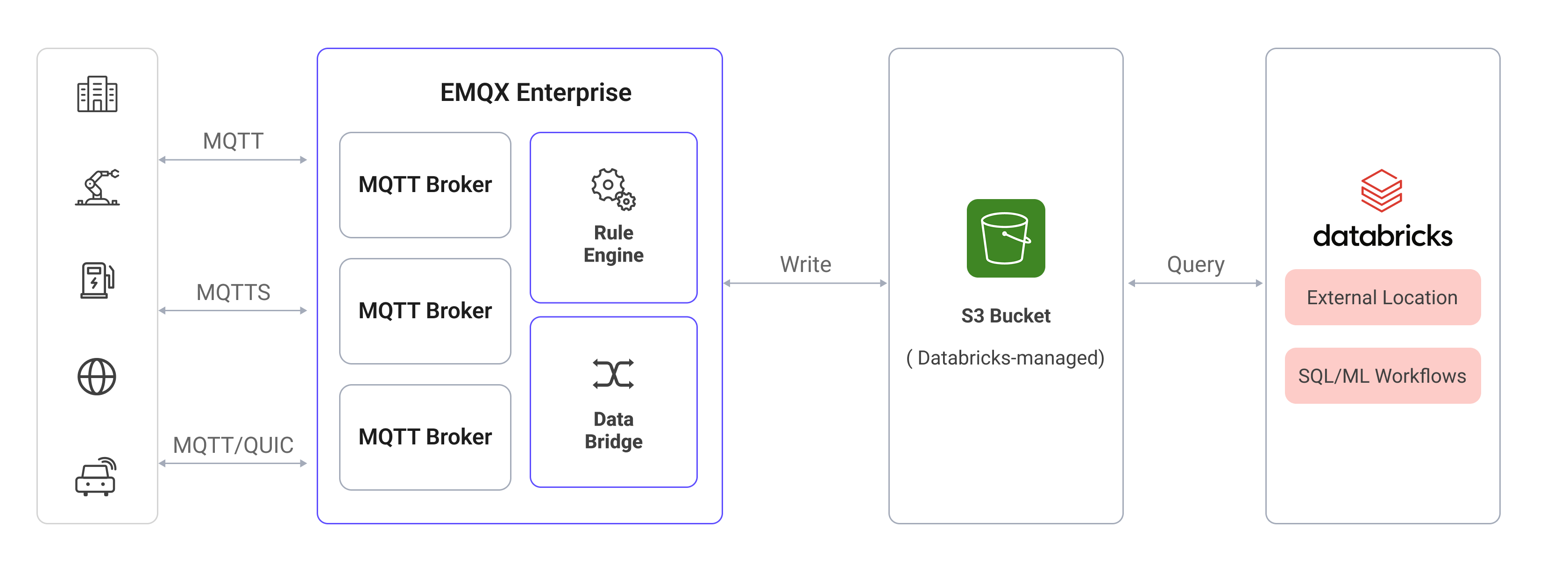
具体工作流程如下:
- 设备连接到 EMQX:物联网设备通过 MQTT 协议连接成功后将触发上线事件,事件包含设备 ID、来源 IP 地址以及其他属性等信息。
- 设备消息发布和接收:设备通过特定的主题发布遥测和状态数据,EMQX 接收到消息后将在规则引擎中进行比对。
- 规则引擎处理消息:通过内置的规则引擎,可以根据主题匹配处理特定来源的消息和事件。规则引擎会匹配对应的规则,并对消息和事件进行处理,例如转换数据格式、过滤掉特定信息或使用上下文信息丰富消息。
- 写入 Amazon S3:规则触发后,消息通过 Amazon S3 Sink 写入 Databricks 工作区关联的 S3 存储桶中。
- Databricks 从 S3 读取数据:Databricks 通过外部位置直接查询 S3 存储桶中的数据,支持实时分析和机器学习工作流。
特性与优势
在 EMQX 中使用 Databricks 数据集成能够为您的业务带来以下特性与优势:
- 消息转换:消息可以在写入 S3 之前,通过 EMQX 规则进行丰富的处理和转换,方便后续的存储和使用。
- 灵活数据操作:通过 Amazon S3 Sink,可以方便地将特定字段的数据写入 Databricks 管理的 S3 存储桶,支持动态设置对象键,实现数据的灵活存储。
- 统一分析平台:将 EMQX 与 Databricks 集成后,物联网数据可立即用于 Databricks 工作区内的 SQL 分析、机器学习和数据工程流水线。
- 低成本长期存储:以 S3 作为底层存储,提供高可用、高可靠、低成本的对象存储服务,适合大规模物联网数据的长期存储需求。
准备工作
本节介绍了在 EMQX 中创建 Amazon S3 连接器和 Sink 之前需要做的准备工作。
前置准备
在开始之前,请确保您已了解以下内容:
EMQX 相关概念:
Databricks 相关概念:
- 工作区(Workspace):Databricks 工作区是访问所有 Databricks 资产的环境。
- 外部位置(External Location):Databricks 的一项功能,将外部 S3 路径映射到 Databricks,使该路径下的数据可通过 SQL 直接查询。
- 存储凭证(Storage Credential):Databricks 中用于授权读写外部存储位置的访问凭证。
在 AWS Marketplace 上订阅 Databricks
本节以在 AWS Marketplace 上订阅 Databricks 作为部署示例。
在 AWS Marketplace 上订阅 Databricks。订阅后,系统将引导您创建 Databricks 账号和工作区。
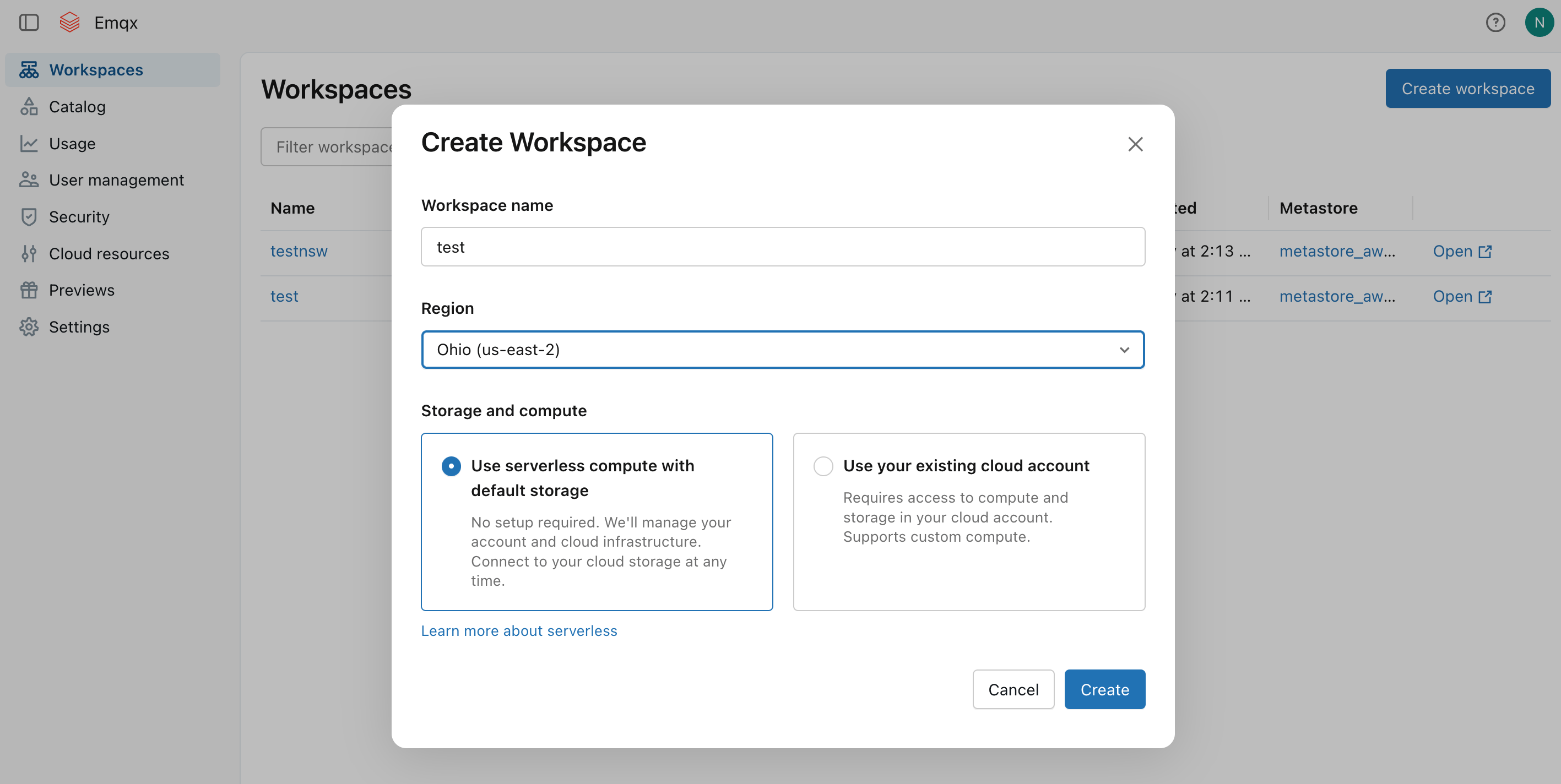
订阅完成后,创建一个工作区。选择区域和存储选项,点击 Create。
工作区创建完成后,将出现在 Workspaces 列表中。记录系统为工作区自动创建的 S3 存储桶名称(例如
databricks-workspace-stack-142ec-bucket),该存储桶将用于存储来自 EMQX 的 MQTT 数据。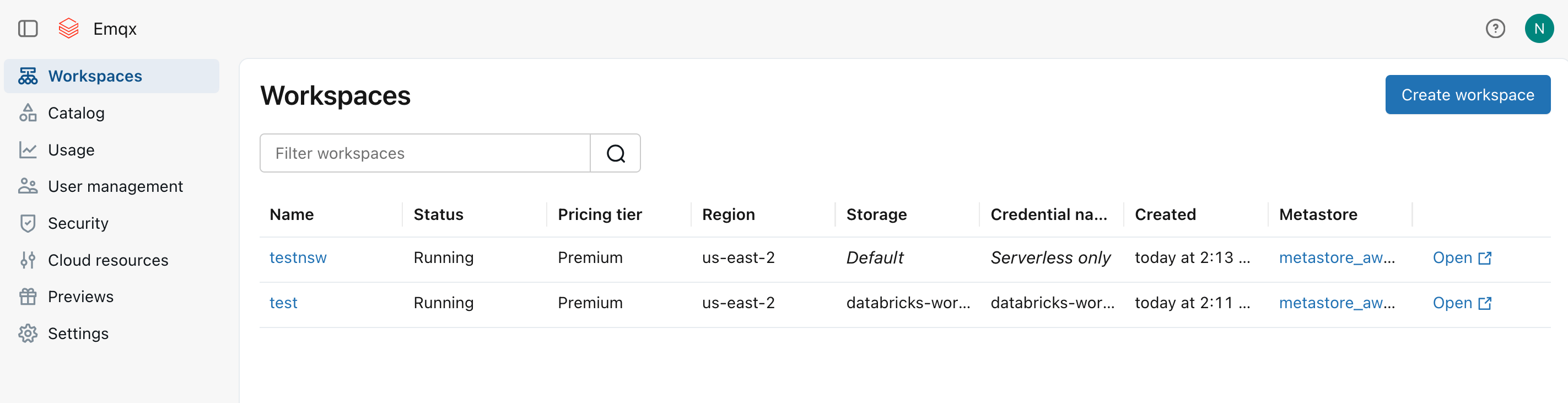
打开工作区,进入 Catalog -> External locations,创建一个指向 EMQX 写入数据的 S3 路径的外部位置。
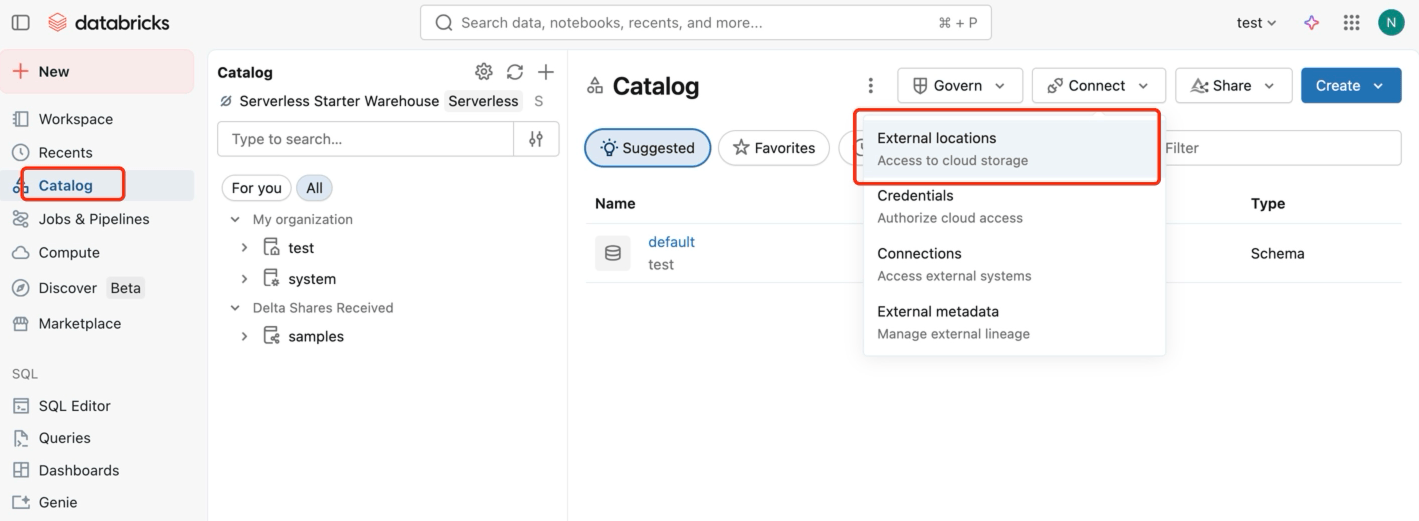
点击 Create location,将 Storage type 设为
S3,在 URL 中填写s3://databricks-workspace-stack-142ec-bucket/emqx-iot-data-new,并选择对应的 Storage credential。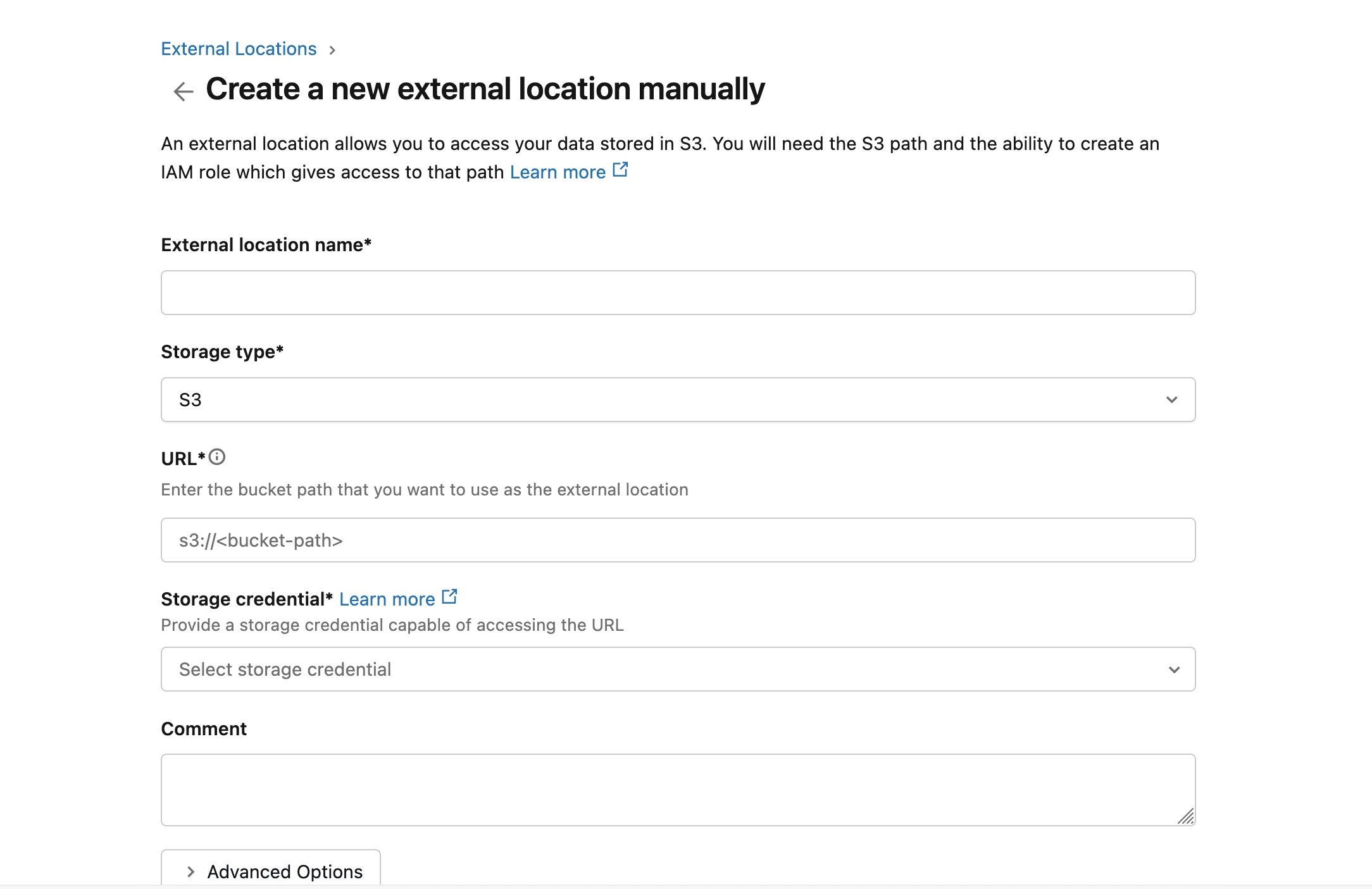
获取具有该 S3 存储桶读写权限的 IAM 用户或角色的 AWS 访问凭证(访问密钥 ID 和私有访问密钥),用于配置 EMQX 连接器。
至此,您已完成 Databricks 工作区和 S3 存储桶的配置,接下来将在 EMQX 中创建连接器和 Sink。
创建连接器
在添加 Amazon S3 Sink 前,您需要创建对应的连接器,创建步骤如下:
- 转到 Dashboard 集成 -> 连接器页面。
- 点击页面右上角的创建。
- 在连接器类型中选择 Amazon S3,点击下一步。
- 输入连接器名称。名称必须以字母或数字开头,可以包含字母、数字、连字符或下划线。例如:
my-databricks。 - 输入连接信息:
- 主机:填写 Databricks 工作区所在 AWS 区域对应的 S3 端点,格式为
s3.{region}.amazonaws.com。 - 端口:填写
443。 - 访问密钥 ID 和私有访问密钥:填写在 AWS Marketplace 上订阅 Databricks 中获取的 AWS 访问凭证。
- 主机:填写 Databricks 工作区所在 AWS 区域对应的 S3 端点,格式为
- 其余配置使用默认值即可。
- 点击创建之前,您可以先点击测试连接,验证 EMQX 是否可以连接到 S3 服务。
- 点击创建按钮完成连接器创建。页面将弹出创建成功对话框,询问是否立即创建规则。点击创建规则可直接进入规则创建页面并预选该连接器,或点击返回连接器列表稍后再创建规则。
创建 Amazon S3 Sink 规则
本节演示了如何在 EMQX 中创建一条规则,用于处理来自源 MQTT 主题 t/# 的消息,并通过配置的 Sink 将处理后的结果写入 Databricks 管理的 S3 存储桶中。
如果您在上一步中点击了创建规则,添加动作面板将自动打开,且动作类型已设置为
Amazon S3并预选了连接器,可直接跳至第 5 步。否则,请前往 Dashboard 集成 -> 规则页面,点击右上角创建。输入规则 ID,在 SQL 编辑器中输入规则 SQL 如下:
sqlSELECT * FROM "t/#"TIP
如果您初次使用 SQL,可以点击 SQL 示例和启用测试来学习和测试规则 SQL 的结果。
点击 + 添加动作,从动作类型下拉列表中选择
Amazon S3,保持动作下拉框为默认的创建动作选项。在连接器下拉框中选择刚刚创建的
my-databricks连接器。您也可以点击下拉框旁边的创建按钮,在弹出框中快捷创建新的连接器,所需的配置参数可以参考创建连接器。输入 Sink 的名称与描述(可选)。
设置存储桶,此处输入
databricks-workspace-stack-142ec-bucket。此处也支持${var}格式的占位符,但要注意需要在 S3 中预先创建好对应名称的存储桶。根据情况选择 ACL,指定上传对象的访问权限。
选择上传方式,两种方式区别如下:
- 直接上传:每次规则触发时,按照预设的对象键和内容直接上传到 S3,适合存储二进制或体积较大的文本数据。
- 聚合上传:将多次规则触发的结果打包为一个文件(如 CSV 文件)并上传到 S3,适合存储结构化数据,可以减少文件数量,提高写入效率。
两种方式配置的参数不同,请根据所选方式进行配置:
备选动作(可选):如果您希望在消息投递失败时提升系统的可靠性,可以为 Sink 配置一个或多个备选动作。更多信息请参见:备选动作。
展开高级设置,根据需要配置高级设置选项(可选),详细请参考高级设置。
其余参数使用默认值即可。点击创建之前,可以先点击测试连接验证 Sink 是否可以连接到 S3 服务。
点击创建按钮完成 Sink 的创建,创建成功后页面将回到规则创建,新的 Sink 将添加到规则动作中。
回到规则创建页面,点击保存按钮完成整个规则创建。
现在您已成功创建了规则,您可以在规则页面上看到新建的规则,同时在动作(Sink) 标签页看到新建的 Amazon S3 Sink。
测试规则
使用 MQTTX 向 t/1 主题发布消息:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "hello Databricks" }'发送几条消息后,在 Databricks 工作区中,右键点击 Workspace,选择 Create -> Notebook 创建一个新 Notebook。
在 Notebook 中运行以下 SQL 查询,验证数据已成功导入:
SELECT * FROM json.`s3://databricks-workspace-stack-142ec-bucket/emqx-iot-data-new/`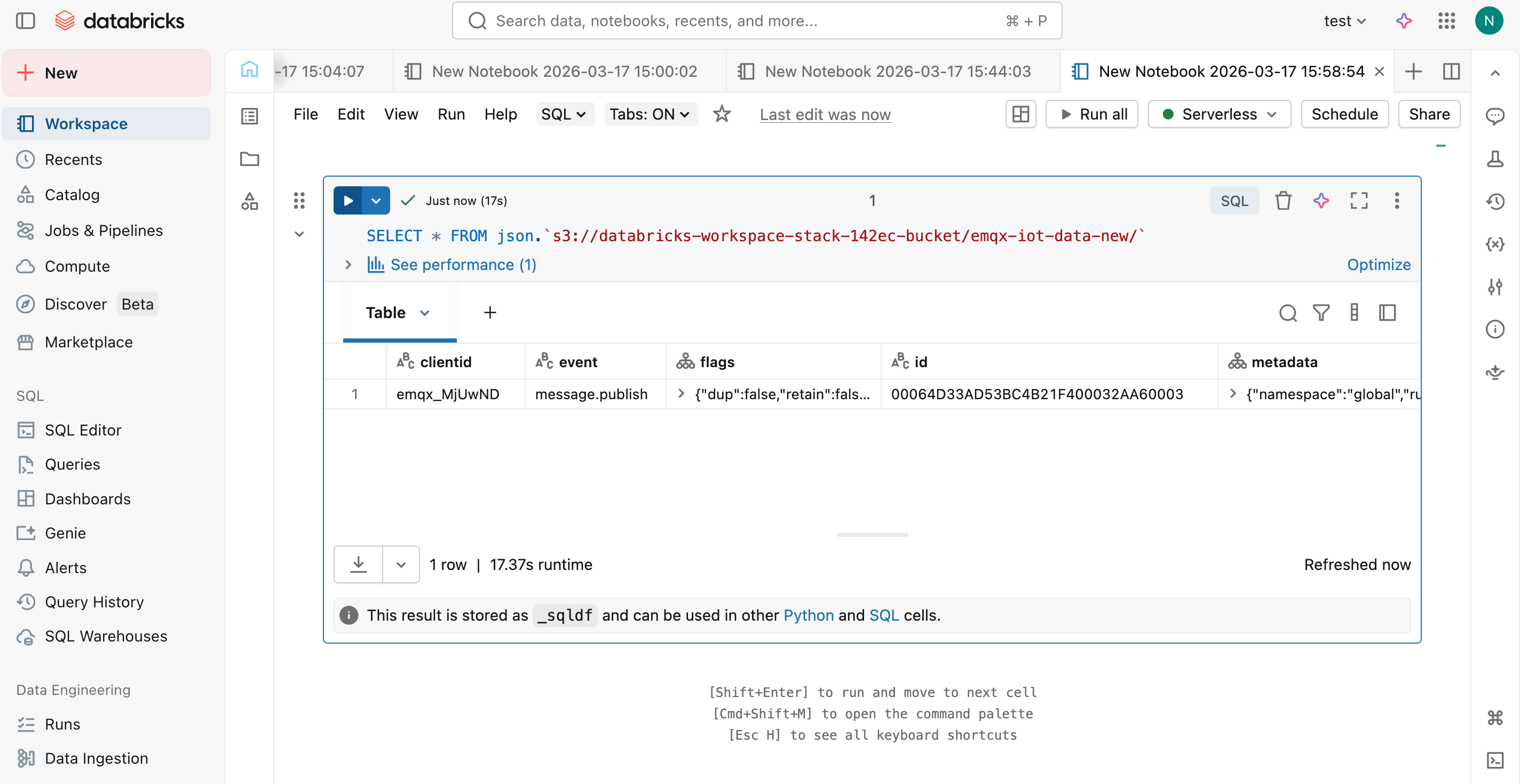
高级设置
本节将深入介绍可用于 Amazon S3 Sink 的高级配置选项。在 Dashboard 中配置 Sink 时,您可以根据您的特定需求展开高级设置,调整以下参数。
| 字段名称 | 描述 | 默认值 |
|---|---|---|
| 缓存池大小 | 指定缓冲区工作进程数量,用于管理 EMQX 与 S3 之间的数据流。 | 16 |
| 请求超期 | 指定请求进入缓冲区后被视为有效的最长持续时间(以秒为单位)。 | 45 秒 |
| 健康检查间隔 | 指定 Sink 对与 S3 的连接执行自动健康检查的时间间隔(以秒为单位)。 | 15 秒 |
| 健康检查间隔抖动 | 在健康检查间隔中添加随机延迟,用于避免多个节点同时触发健康检查请求。 | 0 毫秒 |
| 健康检查超时 | 指定对与 S3 服务的连接执行自动健康检查的超时时间。 | 60 秒 |
| 缓存队列最大长度 | 指定每个缓冲区工作进程可缓冲的最大字节数。 | 256 MB |
| 请求模式 | 允许您选择同步或异步请求模式,以根据不同要求优化消息传输。 | 异步 |
| 请求飞行队列窗口 | 控制 Sink 与 S3 通信时可以同时存在的最大飞行队列请求数。 | 100 |
| 最小分片大小 | 聚合完成后分片上传的最小块大小,上传数据将在内存中累积直到达到此大小。 | 5MB |
| 最大分片大小 | 分块上传的最大块大小,S3 Sink 不会尝试上传超过此大小的分片。 | 5GB |