DatabricksへのMQTTデータ取り込み
Databricksは、Apache Sparkを基盤とした統合データ分析プラットフォームであり、大規模なデータエンジニアリング、機械学習、共同分析に対応しています。EMQXは、Databricksが管理するAmazon S3バケットにMQTTデータを書き込み、Databricksが外部ロケーション経由で直接クエリできる形でDatabricksと連携します。
本ページでは、EMQXとDatabricks間のデータ統合について詳しく解説し、コネクターおよびSinkの作成方法を実践的に案内します。
動作の仕組み
EMQXにおけるDatabricksデータ統合は、Amazon S3統合を基盤としています。EMQXはMQTTデータをDatabricksが管理するS3バケットに書き込み、Databricksは外部ロケーションを介してこのバケットにアクセスし、保存されたデータに対して直接SQLクエリを実行します。
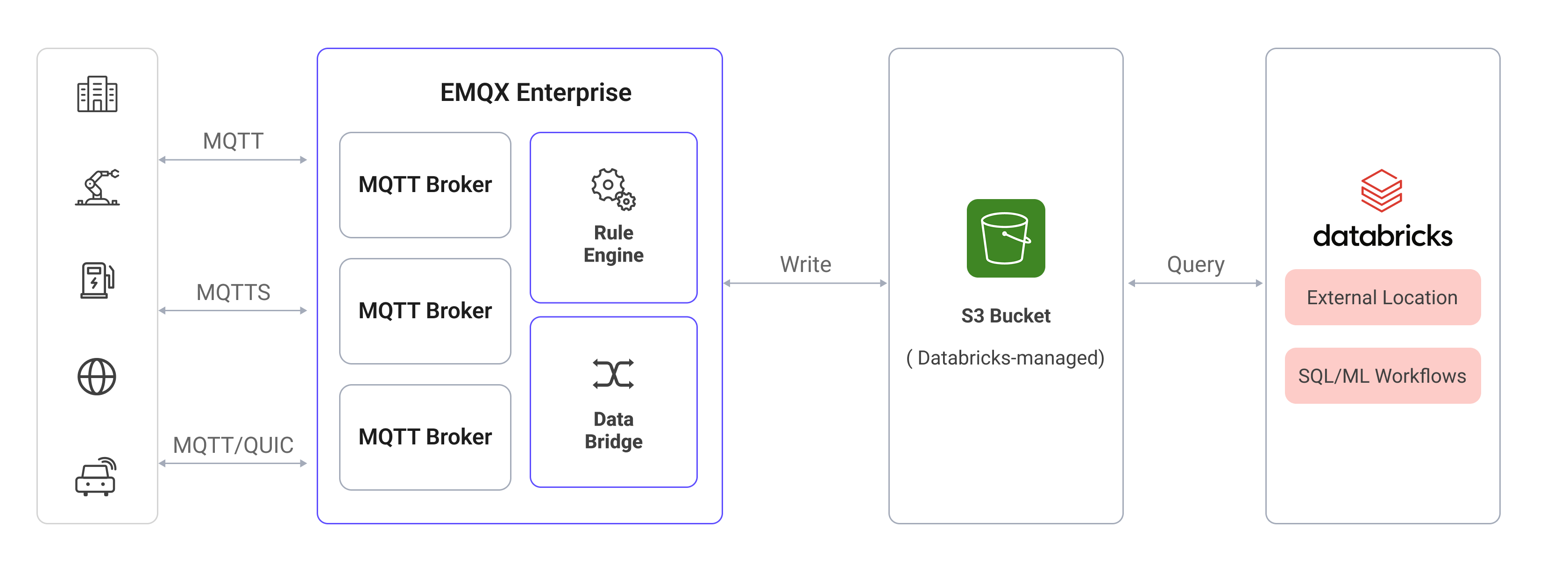
具体的なワークフローは以下の通りです:
- デバイスのEMQXへの接続:IoTデバイスはMQTTプロトコルで正常に接続するとオンラインイベントをトリガーします。このイベントにはデバイスID、送信元IPアドレスなどのプロパティ情報が含まれます。
- デバイスからのメッセージパブリッシュと受信:デバイスは特定のトピックを通じてテレメトリやステータスデータをパブリッシュします。EMQXはこれらのメッセージを受信し、ルールエンジン内で比較処理を行います。
- ルールエンジンによるメッセージ処理:組み込みのルールエンジンは、トピックマッチングに基づいて特定のソースからのメッセージやイベントを処理します。該当するルールにマッチしたメッセージやイベントに対し、データ形式変換、特定情報のフィルタリング、コンテキスト情報の付加などを実施します。
- Amazon S3への書き込み:ルールはAmazon S3 Sinkをトリガーし、処理済みデータをDatabricksワークスペースに紐づくS3バケットへ書き込みます。
- DatabricksによるS3からの読み込み:Databricksは外部ロケーション経由でS3バケット内のデータを直接クエリし、リアルタイム分析や機械学習ワークフローを実現します。
特長と利点
EMQXのDatabricksデータ統合を利用することで、以下のような特長とメリットが得られます:
- メッセージ変換:EMQXのルール内でメッセージを高度に処理・変換してからS3に書き込むため、その後の保存や分析が容易になります。
- 柔軟なデータ操作:Amazon S3 Sinkを使い、Databricks管理のS3バケットに特定のデータフィールドを柔軟に書き込めます。動的なオブジェクトキー設定にも対応しています。
- 統合分析プラットフォーム:EMQXとDatabricksを連携することで、IoTデータを即座にDatabricksワークスペース内のSQL分析、機械学習、データエンジニアリングパイプラインに活用可能です。
- 低コストな長期保存:S3を基盤ストレージに利用することで、高可用性かつ信頼性の高いコスト効率の良いデータ保存が可能であり、大規模IoTワークロードに適しています。
はじめる前に
このセクションでは、EMQXでDatabricks向けのAmazon S3コネクターおよびSinkを作成する前に必要な準備について説明します。
前提条件
以下の内容にあらかじめ習熟していることを推奨します:
EMQXの概念:
Databricksの概念:
- ワークスペース:Databricksのすべての資産にアクセスする環境。
- 外部ロケーション:外部のS3パスをマッピングし、そこに保存されたデータをSQLで直接クエリ可能にするDatabricksの機能。
- ストレージ認証情報:外部ストレージの読み書き権限を付与するDatabricksのアクセス認証情報。
AWS MarketplaceでのDatabricksセットアップ
ここでは、AWS MarketplaceでDatabricksをサブスクライブする例を用いてデプロイ手順を説明します。
AWS MarketplaceでDatabricksをサブスクライブします。Databricksアカウントとワークスペース作成の案内が表示されます。
サブスクライブ後、ワークスペースを作成します。リージョンとストレージオプションを選択し、Createをクリックします。
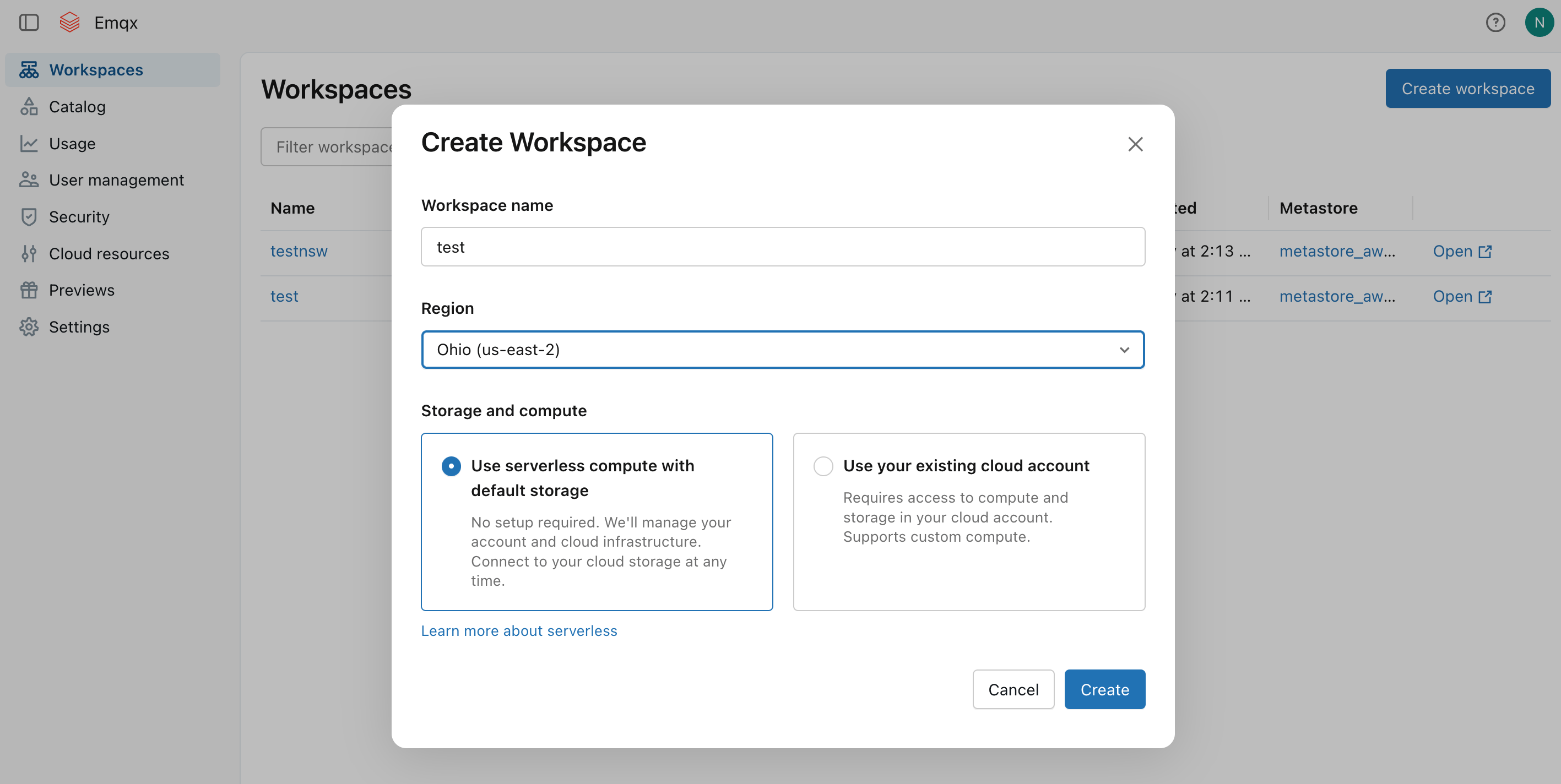
ワークスペース作成後、Workspacesリストに表示されます。ワークスペースに自動プロビジョニングされたS3バケット名(例:
databricks-workspace-stack-142ec-bucket)を控えてください。このバケットにEMQXからのMQTTデータを保存します。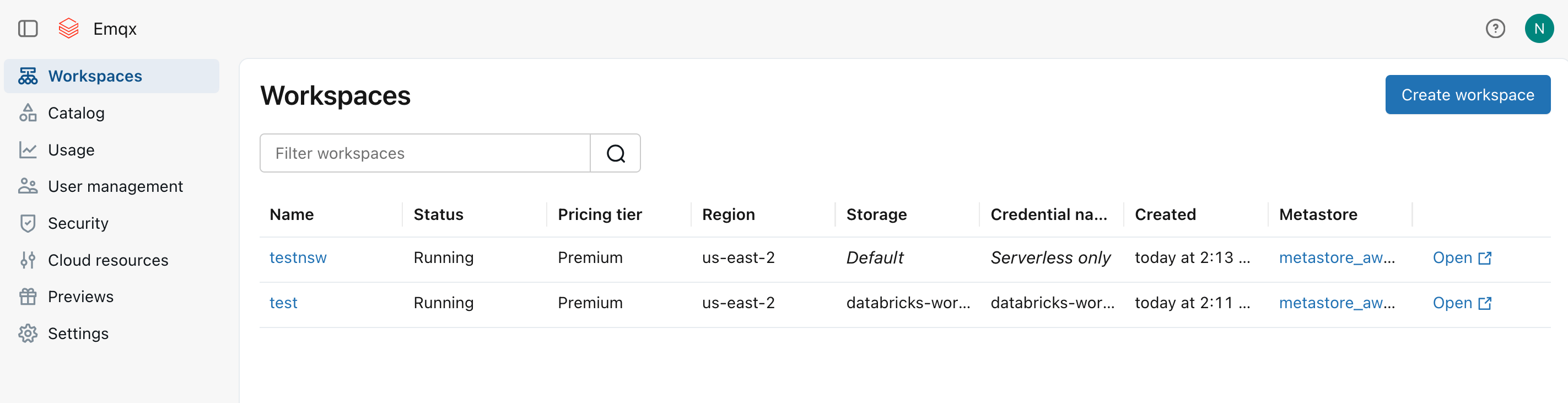
ワークスペースを開き、Catalog -> External locationsに移動し、EMQXがデータを書き込むS3パスを指す外部ロケーションを作成します。
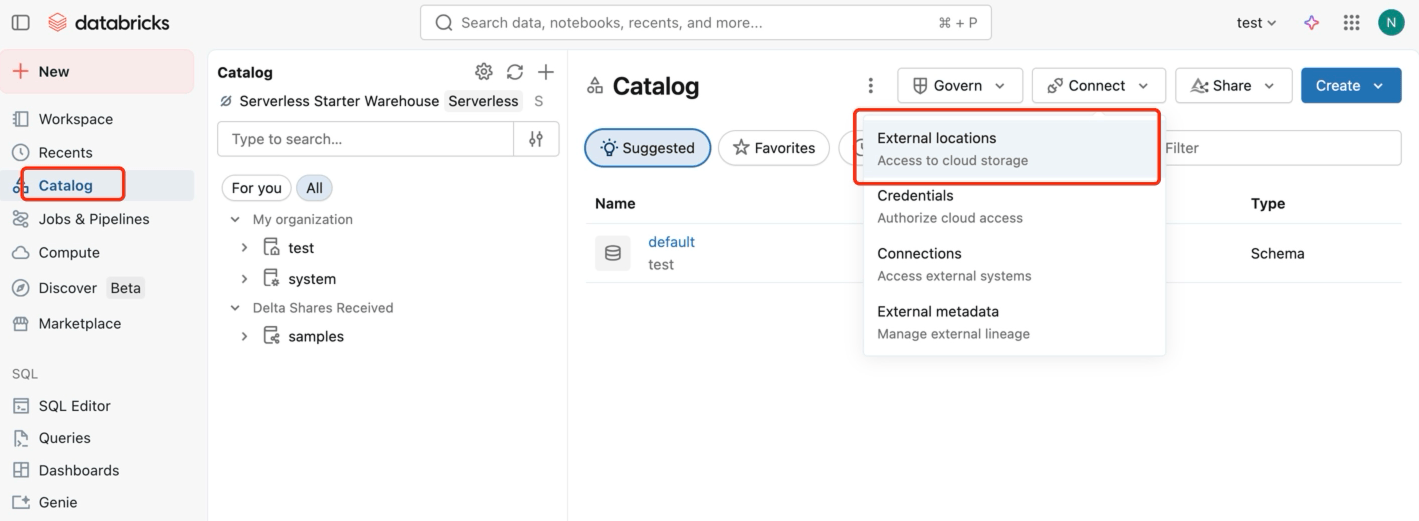
Create locationをクリックし、Storage typeを
S3に設定、URLにs3://databricks-workspace-stack-142ec-bucket/emqx-iot-data-newを入力し、Storage credentialを選択します。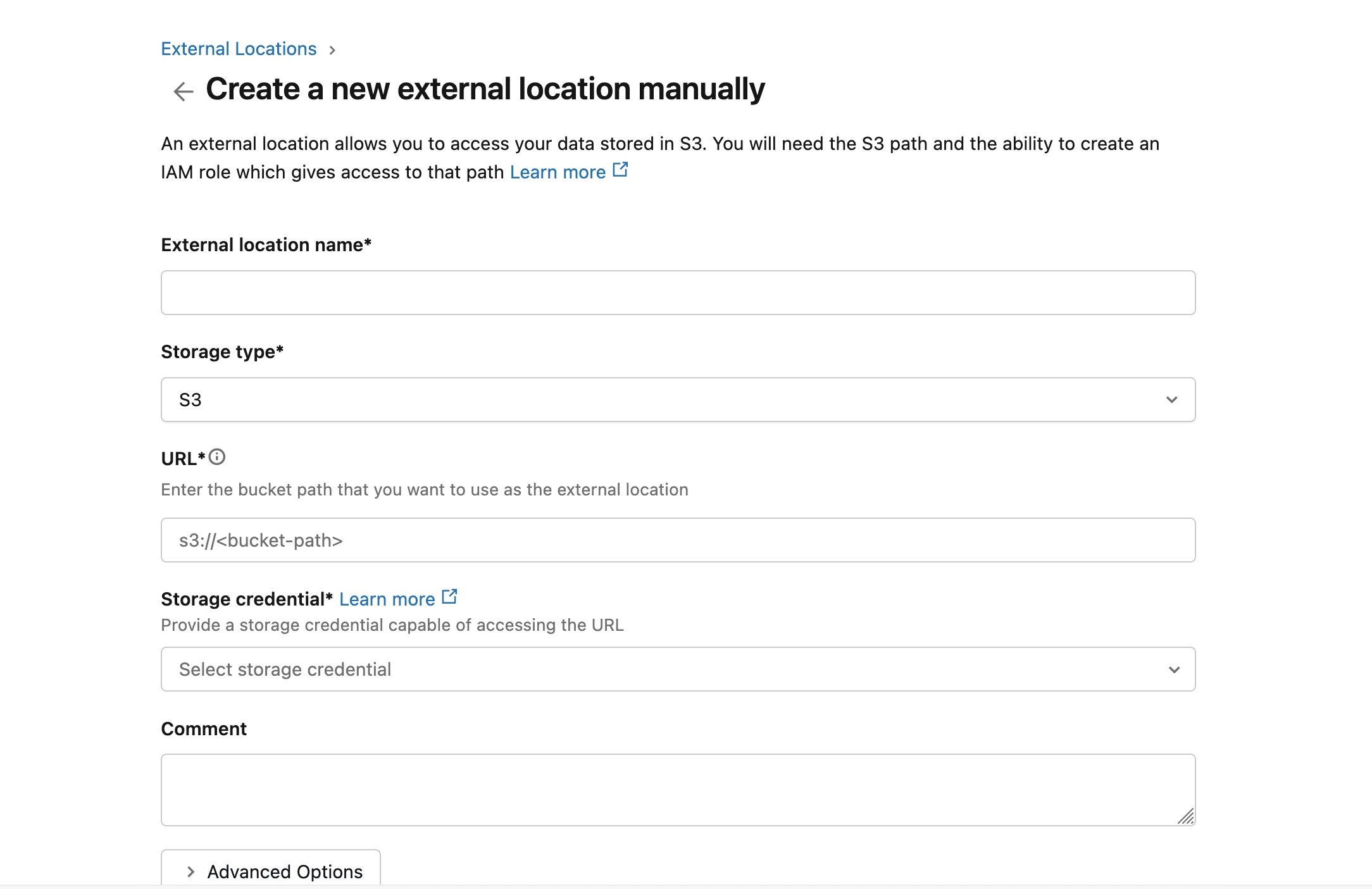
S3バケットへの読み書き権限を持つIAMユーザーまたはロールのAWSアクセス認証情報(Access Key IDとSecret Access Key)を取得します。これらはEMQXコネクターの設定に使用します。
DatabricksワークスペースとS3バケットの設定が完了したら、EMQXでコネクターおよびSinkの作成準備が整います。
コネクターの作成
Amazon S3 Sinkを追加する前に、対応するコネクターを作成します。
- ダッシュボードのIntegration -> Connectorsページに移動します。
- 右上のCreateボタンをクリックします。
- コネクタータイプとしてAmazon S3を選択し、Nextをクリックします。
- コネクター名を入力します。名前は英数字で始まり、英数字、ハイフン、アンダースコアを含めることができます。ここでは例として
my-databricksと入力します。 - 接続情報を入力します:
- Host:DatabricksワークスペースがデプロイされているAWSリージョンのS3エンドポイント(例:
s3.{region}.amazonaws.com)を入力。 - Port:
443を入力。 - Access Key IDおよびSecret Access Key:AWS MarketplaceでのDatabricksセットアップで取得した認証情報を入力。
- Host:DatabricksワークスペースがデプロイされているAWSリージョンのS3エンドポイント(例:
- その他の設定はデフォルト値のままにします。
- Createをクリックする前に、Test Connectivityを押してEMQXがS3サービスに接続できるか確認可能です。
- Createをクリックしてコネクター作成を完了します。作成成功のダイアログが表示され、ルールを今すぐ作成するか尋ねられます。Create Ruleをクリックすると、コネクターが事前選択された状態でルール作成画面に進みます。後で作成する場合はBack To Connector Listをクリックします。
Amazon S3 Sinkを使ったルールの作成
このセクションでは、EMQXでソースMQTTトピックt/#からのメッセージを処理し、処理結果をDatabricks管理のS3バケットに書き込むルールの作成方法を示します。
前のステップでCreate Ruleをクリックした場合、Add Actionパネルが自動で開き、Type of Actionが
Amazon S3、コネクターが事前選択されています。ステップ5に進んでください。そうでなければ、ダッシュボードのIntegration -> Rulesページに移動し、右上のCreateをクリックします。ルールIDを入力し、SQLエディターに以下のルールSQLを入力します:
sqlSELECT * FROM "t/#"TIP
初心者の方はSQL Examplesをクリックし、Enable Testを有効にしてSQLルールの学習とテストが可能です。
右側の**+ Add Actionをクリックし、Add ActionパネルでType of Action**ドロップダウンから
Amazon S3を選択し、ActionはデフォルトのCreate Actionのままにします。Connectorsドロップダウンから先ほど作成した
my-databricksコネクターを選択します。ドロップダウン横の作成ボタンを押すと、ポップアップで新規コネクターを素早く作成可能です。必要な設定項目はコネクターの作成を参照してください。Sinkの名前と任意で説明を入力します。
Bucketに
databricks-workspace-stack-142ec-bucketを入力します。このフィールドは${var}形式のプレースホルダーもサポートしますが、対応するバケットがS3に存在することを確認してください。必要に応じてACLを選択し、アップロードされるオブジェクトのアクセス権限を指定します。
Upload Methodを選択します:
- Direct Upload:ルールがトリガーされるたびに、設定済みのオブジェクトキーと内容に従いデータを直接S3にアップロードします。バイナリや大きなテキストデータの保存に適しています。
- Aggregated Upload:複数回のルールトリガー結果を1つのファイル(例:CSVファイル)にまとめてS3にアップロードします。構造化データの保存に適し、ファイル数を減らし書き込み効率を向上させます。
選択した方法により設定項目が異なります。以下のタブから該当する方法の設定を行ってください。
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義できます。詳細はフォールバックアクションを参照してください。
Advanced Settingsを展開し、必要に応じて詳細設定を行います(任意)。詳細は詳細設定を参照してください。
その他の設定はデフォルト値のままにします。Createをクリックする前に、Test Connectivityを押してSinkがS3サービスに接続できるか確認可能です。
CreateをクリックしてSink作成を完了します。作成成功後、ルール作成画面に戻り、新規Sinkがルールアクションに追加されます。
ルール作成画面でSaveをクリックし、ルール作成全体を完了します。
これでルールが正常に作成されました。Rulesページで新規ルールを確認でき、**Actions (Sink)**タブで新しいAmazon S3 Sinkが表示されます。
ルールのテスト
MQTTXを使ってトピックt/1にメッセージをパブリッシュします:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "hello Databricks" }'数回メッセージを送信した後、DatabricksワークスペースでWorkspaceを右クリックし、Create -> Notebookを選択して新しいノートブックを作成します。
ノートブック内で外部ロケーションに対してSQLクエリを実行し、データが正常に取り込まれていることを確認します:
SELECT * FROM json.`s3://databricks-workspace-stack-142ec-bucket/emqx-iot-data-new/`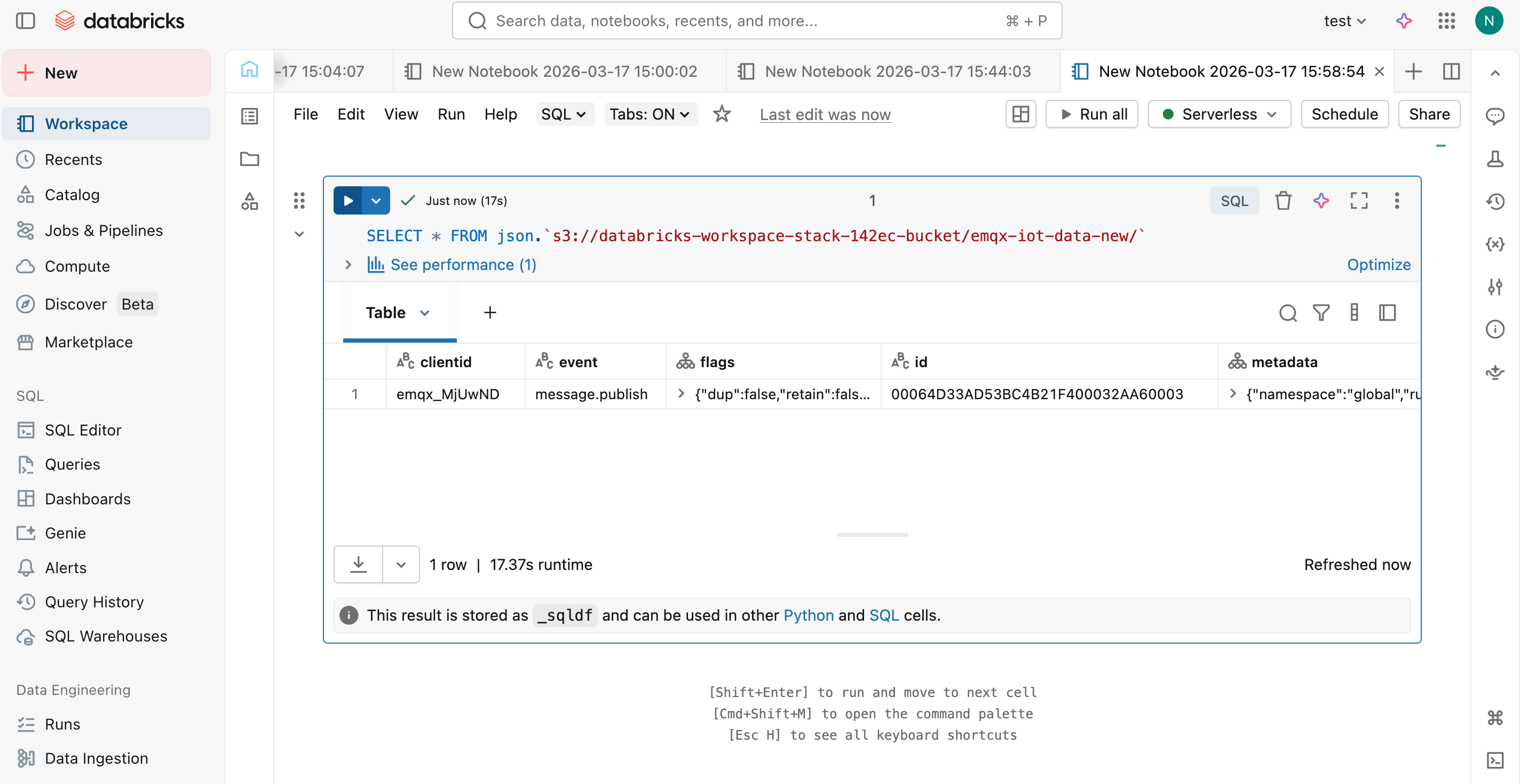
詳細設定
このセクションでは、Amazon S3 Sinkの詳細設定オプションについて説明します。ダッシュボードでSinkを設定する際にAdvanced Settingsを展開し、用途に応じて以下のパラメーターを調整できます。
| 項目名 | 説明 | デフォルト値 |
|---|---|---|
| Buffer Pool Size | EMQXとS3間のデータフローを管理するバッファワーカープロセスの数を指定します。 | 16 |
| Request TTL | リクエストがバッファに入ってから有効とみなされる最大時間(秒)を指定します。 | 45 |
| Health Check Interval | SinkがS3との接続状態を自動的にヘルスチェックする間隔(秒)を指定します。 | 15秒 |
| Health Check Interval Jitter | 複数ノードが同時にヘルスチェックを開始する確率を減らすために、基本間隔に加える一様ランダム遅延です。 | 0ミリ秒 |
| Health Check Timeout | コネクターがS3との接続状態をヘルスチェックする際のタイムアウト時間を指定します。 | 60秒 |
| Max Buffer Queue Size | S3 Sinkの各バッファワーカープロセスがバッファリング可能な最大バイト数を指定します。 | 256 MB |
| Query Mode | メッセージ送信の最適化のため、synchronous(同期)またはasynchronous(非同期)のリクエストモードを選択します。 | Asynchronous |
| In-flight Window | SinkがS3と通信中に同時に存在可能なインフライトキューリクエストの最大数を制御します。 | 100 |
| Min Part Size | 集約完了後のパートアップロードにおける最小チャンクサイズを指定します。 | 5MB |
| Max Part Size | パートアップロードの最大チャンクサイズを指定します。 | 5GB |