参照用テストシナリオと結果
本ページでは、さまざまなシナリオで実施した一連のベンチマークテストに基づくEMQXの詳細なパフォーマンス分析を示します。評価では、QoSレベルの違い、ペイロードサイズ、パブリッシュ・サブスクライブモデル、MQTTメッセージのブリッジングの影響など、さまざまな条件下でのEMQXの挙動と性能を検証しています。
厳密なテストと計測を通じて、これらの結果は実際の環境におけるEMQXの性能に関する実践的な知見を提供し、IoTアプリケーション向けのEMQXデプロイメント最適化に役立つ指針を示します。
テスト環境
本節のすべてのテストは、単一ノードにデプロイされたオープンソース版のEMQX v5.1.6を対象としています。EMQXとテストサーバー間にはピアリング接続を構築し、外部ネットワークのレイテンシの影響を排除しています。EMQXを稼働させているサーバーの仕様は以下の通りです。
- CPU: 4vCPU(Intel Xeon Platinum 8378A CPU @ 3.00GHz)
- メモリ: 8 GiB
- システムディスク: General Purpose SSD | 40 GiB
- 最大帯域幅: 8 Gbit/s
- 最大パケット毎秒数: 800,000 PPS
- OS: CentOS 7.9
ファンインシナリオを除き、メッセージ送受信に使用したテストクライアント数は10台です。ファンインシナリオでは20台のテストクライアントを使用しています。
テストシナリオと結果
シナリオ1:異なるQoSレベルにおけるEMQXのパフォーマンス
MQTTパケットのやり取りはQoSレベルが上がるほど複雑になり、メッセージ配信時のシステムリソース消費が増加します。したがって、各QoSレベルのパフォーマンスへの影響を理解することが重要です。
本シナリオでは、1,000台のパブリッシャーと1,000台のサブスクライバーによる1対1通信を行い、128バイトのペイロードメッセージを使用しました。つまり、合計1,000のトピックがあり、各トピックに1つのパブリッシャーと1つのサブスクライバーが存在する構成です。
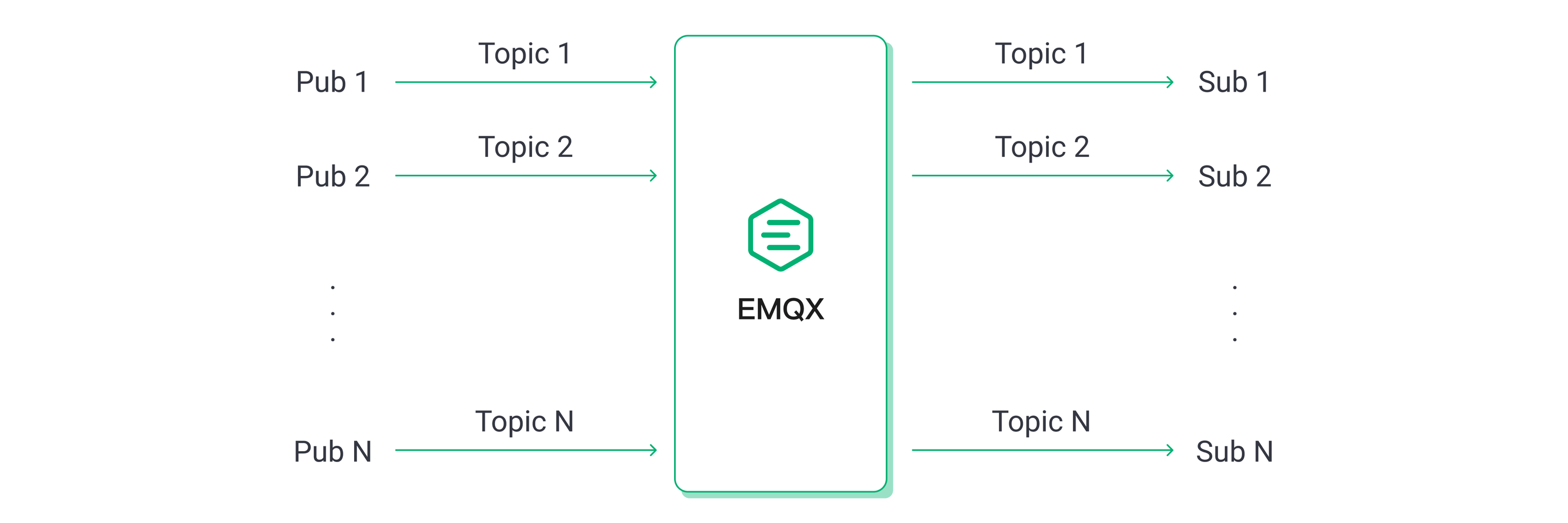
メッセージのパブリッシュレートを段階的に増加させて負荷を上げ、各負荷で5分間EMQXを稼働させて安定動作を確認しました。異なるQoSレベルおよび負荷条件下でのEMQXのパフォーマンスとリソース消費を記録し、平均メッセージレイテンシ、P99メッセージレイテンシ、平均CPU使用率などを測定しました。
最終的なテスト結果は以下の通りです。
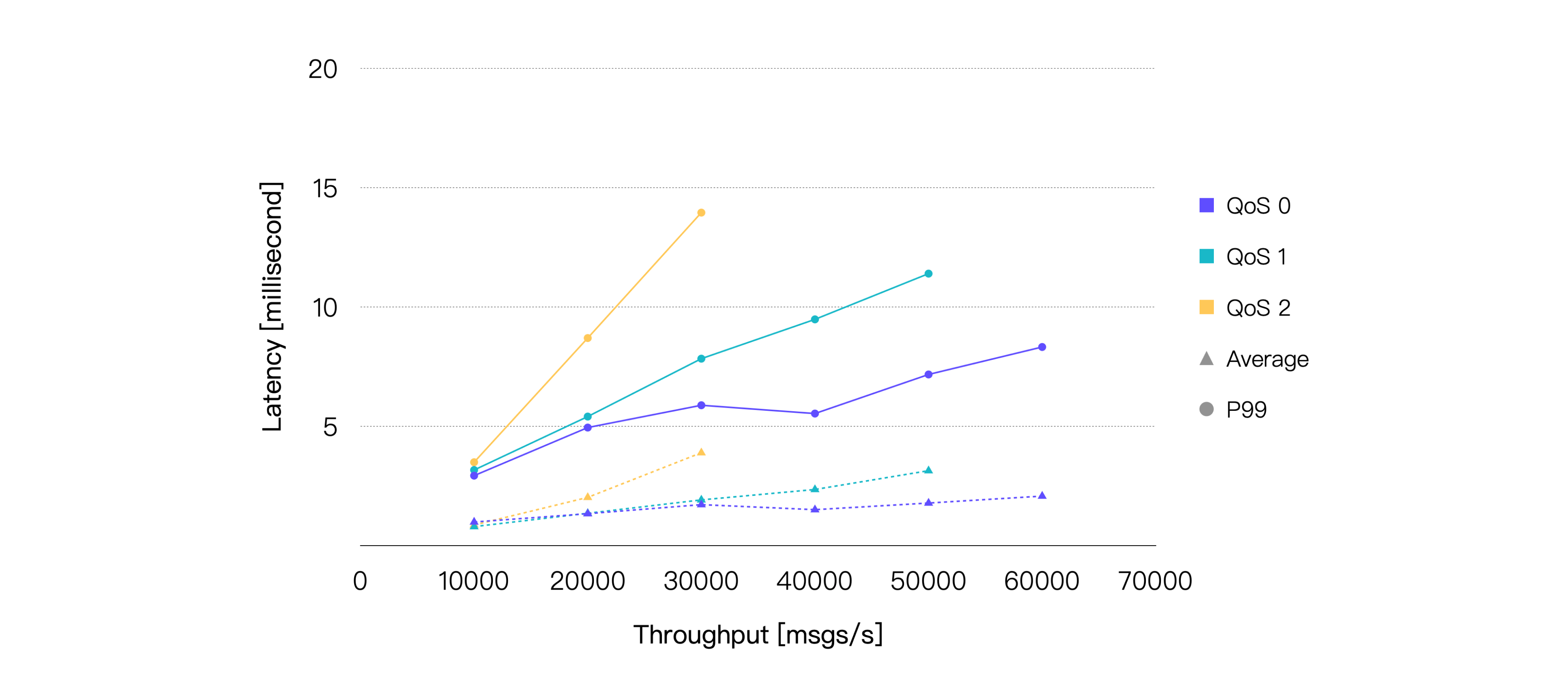
レイテンシとは、メッセージがパブリッシュされてから受信されるまでにかかる時間です。スループットはメッセージのインバウンドスループットとアウトバウンドスループットの合計を指します。
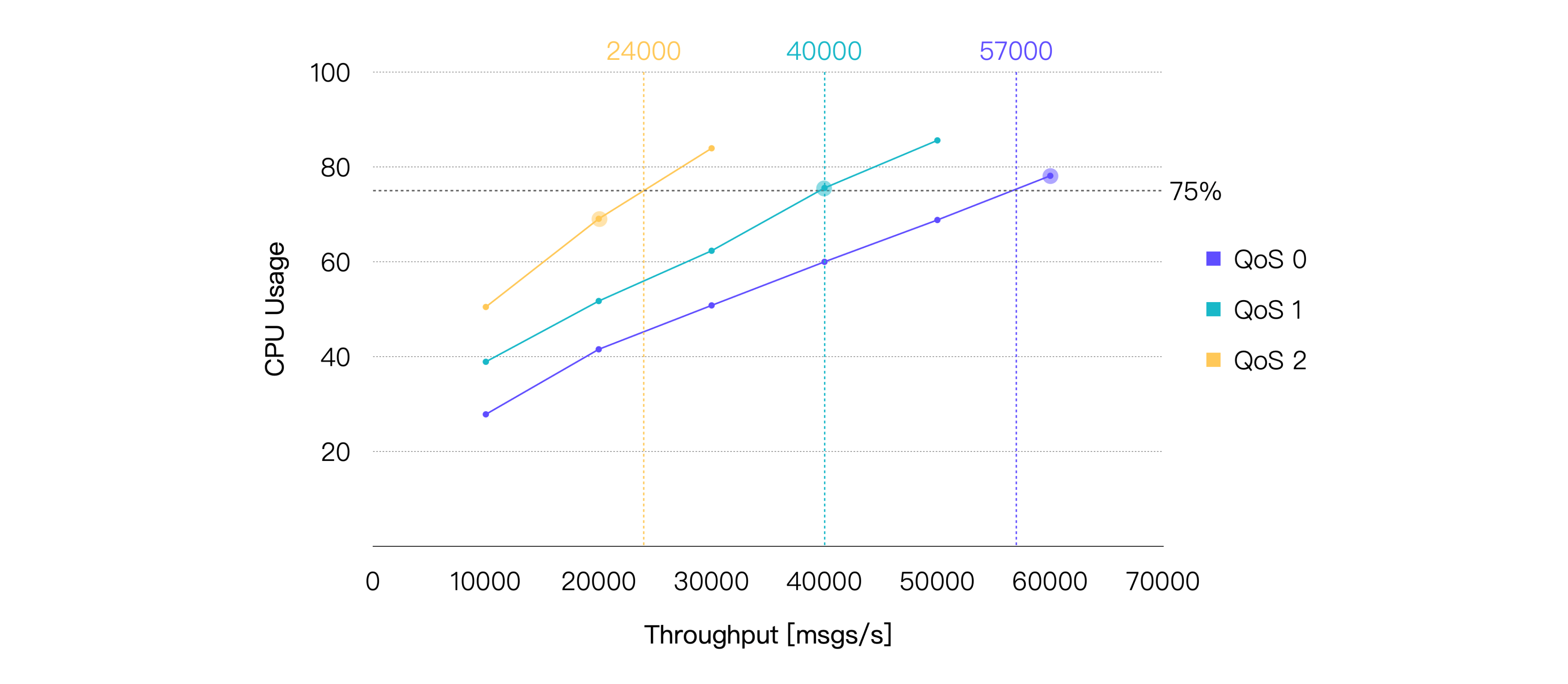
これらの結果から、同等の負荷条件下でQoSレベルが高くなるほど平均CPU使用率が増加し、同じシステムリソースではスループットが相対的に低下する傾向があることが分かります。
平均CPU使用率約75%を推奨される日常負荷と仮定すると、今回のハードウェアおよびテストシナリオにおける推奨負荷は、QoS 0で約57K TPS、QoS 1で約40K TPS、QoS 2で約24K TPSとなります。CPU使用率が75%に最も近いテストポイントのパフォーマンスデータは以下の通りです。
| QoSレベル | 推奨負荷 TPS(イン+アウト) | 平均CPU使用率 %(1 - アイドル) | 平均メモリ使用率 % | 平均レイテンシ ms | P99レイテンシ ms |
|---|---|---|---|---|---|
| QoS 0 | 60K | 78.13 | 6.27 | 2.079 | 8.327 |
| QoS 1 | 40K | 75.56 | 6.82 | 2.356 | 9.485 |
| QoS 2 | 20K | 69.06 | 6.39 | 2.025 | 8.702 |
シナリオ2: 異なるペイロードサイズにおけるEMQXのパフォーマンス
大きなメッセージペイロードは、OSがネットワークパケットを受信・送信する際のソフト割り込みが増加し、パケットのシリアライズ・デシリアライズに必要な計算リソースも増加します。MQTTメッセージの多くは通常1KB未満ですが、より大きなメッセージを送信するケースもあります。そこで、ペイロードサイズの違いによるパフォーマンスへの影響を検証しました。
引き続き1,000台のパブリッシャーと1,000台のサブスクライバーによる1対1通信を行い、メッセージのQoSは1に固定し、パブリッシュレートは20K msg/sに設定しました。ペイロードサイズを増加させて負荷を高め、各負荷で5分間EMQXを稼働させて安定性を確認しました。各負荷条件下でのパフォーマンスとリソース使用率を記録しました。
結果は以下の通りです。
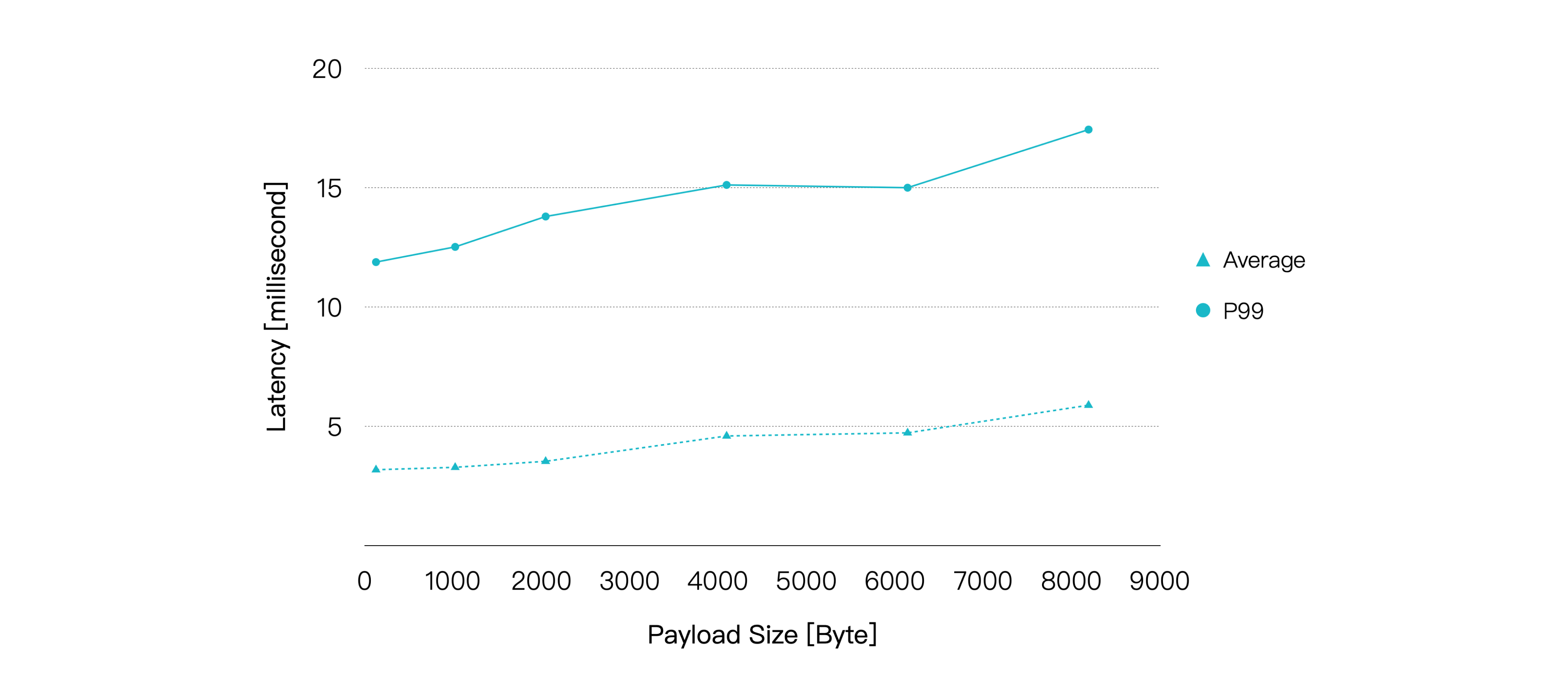
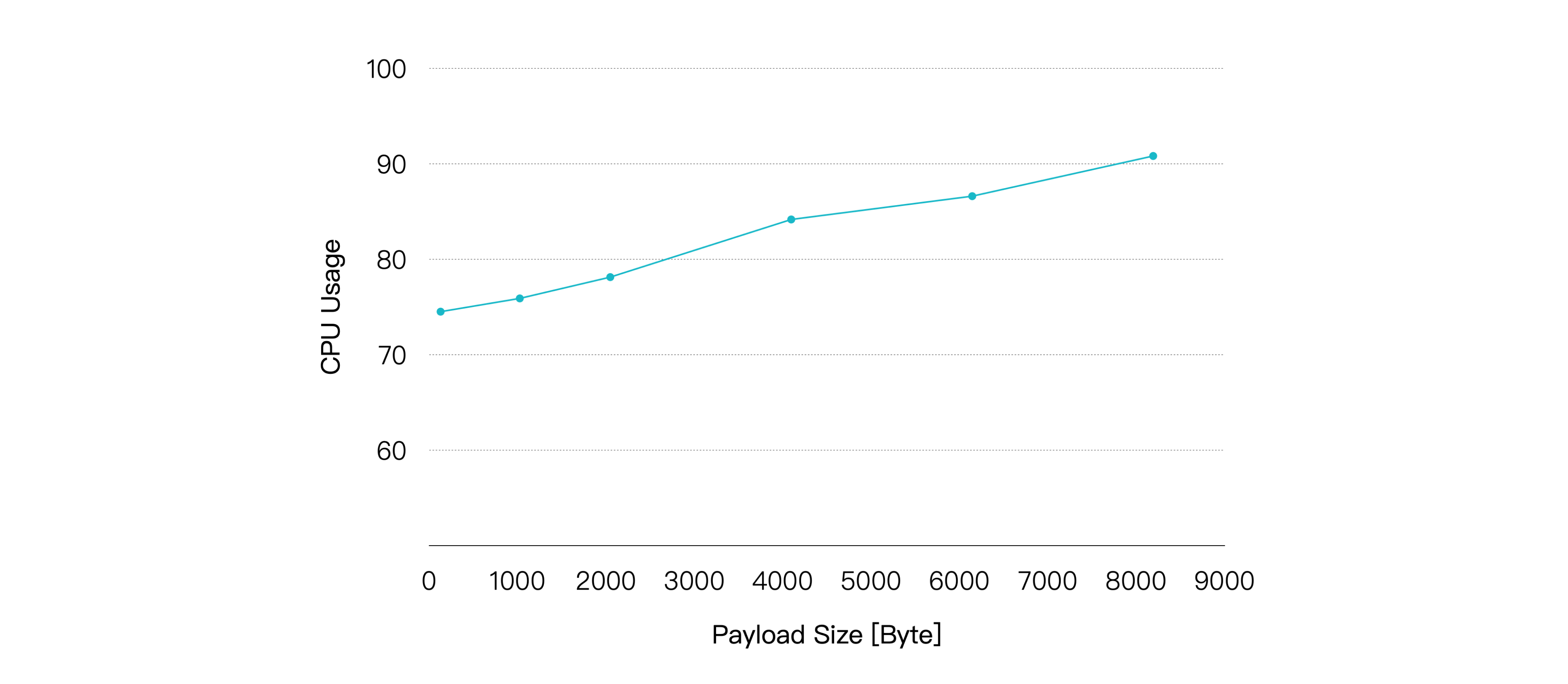
ペイロードが増加するにつれてCPU使用率は徐々に上昇し、メッセージのエンドツーエンドレイテンシも比較的緩やかに増加しています。しかし、ペイロードサイズが8KBに達しても、平均レイテンシは10ミリ秒未満、P99レイテンシは20ミリ秒未満を維持しています。
| ペイロードサイズ KB | 推奨負荷 TPS(イン+アウト) | 平均CPU使用率 %(1 - アイドル) | 平均メモリ使用率 % | 平均レイテンシ ms | P99レイテンシ ms |
|---|---|---|---|---|---|
| 1 | 40K | 75.9 | 6.23 | 3.282 | 12.519 |
| 8 | 40K | 90.82 | 9.38 | 5.884 | 17.435 |
したがって、QoSレベルに加えてペイロードサイズも重要な考慮事項です。もし今回のテストよりもはるかに大きなペイロードサイズを扱う場合は、より高いハードウェア構成が必要になる可能性があります。
シナリオ3: 異なるパブリッシュ・サブスクライブモデルにおけるEMQXのパフォーマンス
MQTTのパブリッシュ・サブスクライブ機構は、特定のビジネス要件に応じてモデルを柔軟に調整できます。シナリオとしては、ファンイン、ファンアウト、シンメトリックモデルがあります。
- ファンインモデルでは、多数のセンサー機器がパブリッシャーとして動作し、少数または単一のバックエンドアプリケーションがサブスクライバーとしてセンサーデータを蓄積・解析します。
- ファンアウトモデルでは、少数のパブリッシャーが多数のサブスクライバーにメッセージを配信します。
- シンメトリックモデルでは、パブリッシャーとサブスクライバーが1対1で通信します。
異なるパブリッシュ・サブスクライブシナリオにおけるMQTTブローカーのパフォーマンスはわずかに異なる場合が多く、以下のテストで確認します。
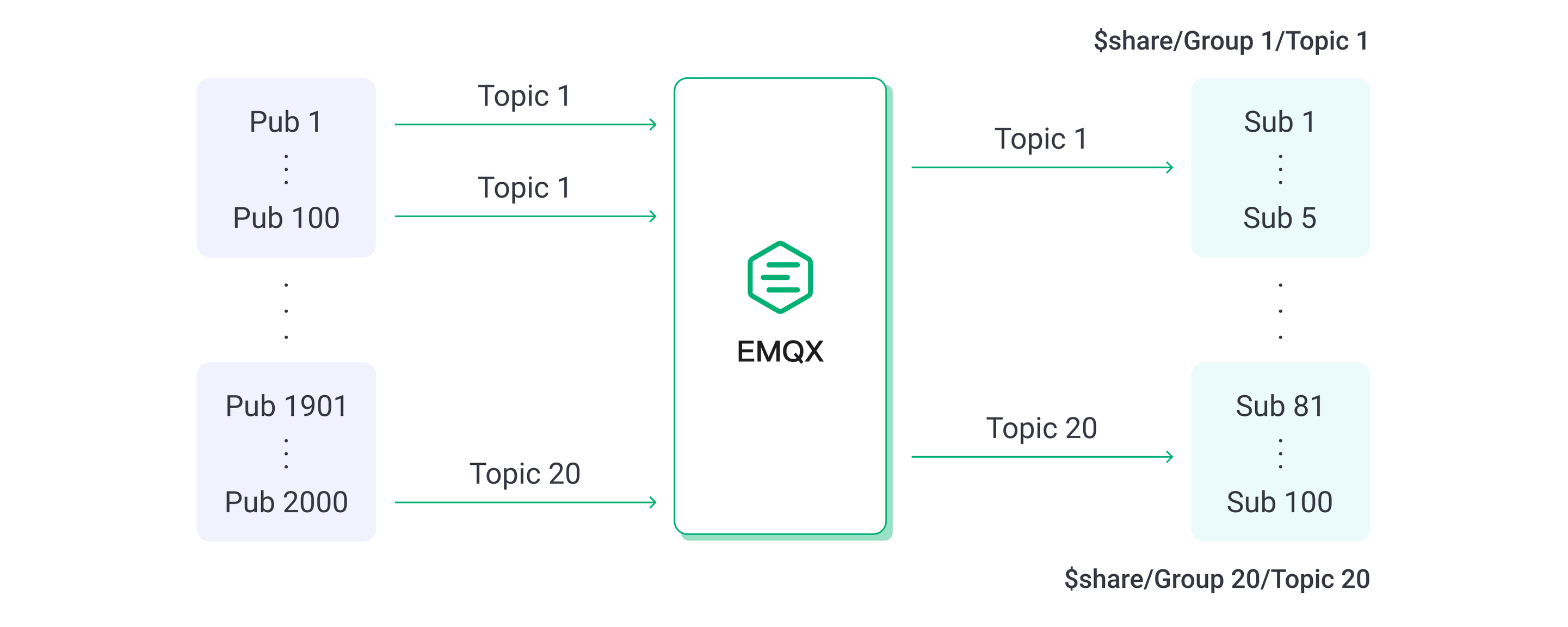
ファンインシナリオでは、2,000台のパブリッシャーと100台のサブスクライバーを設定し、100台のパブリッシャーのメッセージを5台のサブスクライバーが共有サブスクリプションで受信します。
ファンアウトシナリオでは、10台のパブリッシャーと2,000台のサブスクライバーを設定し、各パブリッシャーのメッセージを200台のサブスクライバーが通常のサブスクリプションで受信します。シンメトリックシナリオは前述のままです。
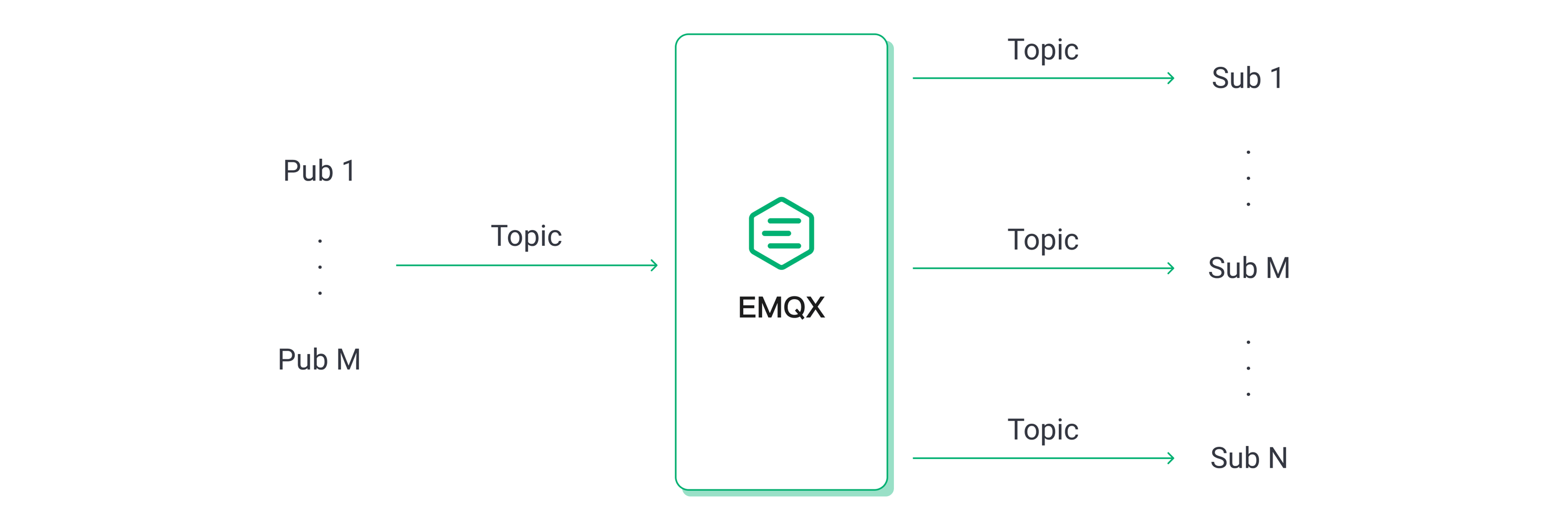
ファンアウトシナリオは他の2つのシナリオよりインバウンドメッセージ数が少ないため、負荷を同等またはほぼ同等に調整して比較しています。例えば、ファンアウトシナリオのインバウンド100 msg/s、アウトバウンド20K msg/sは、シンメトリックシナリオのインバウンド10K msg/s、アウトバウンド10K msg/sに相当します。
メッセージのQoSレベルを1、ペイロードサイズを128バイトに固定し、最終的なテスト結果は以下の通りです。
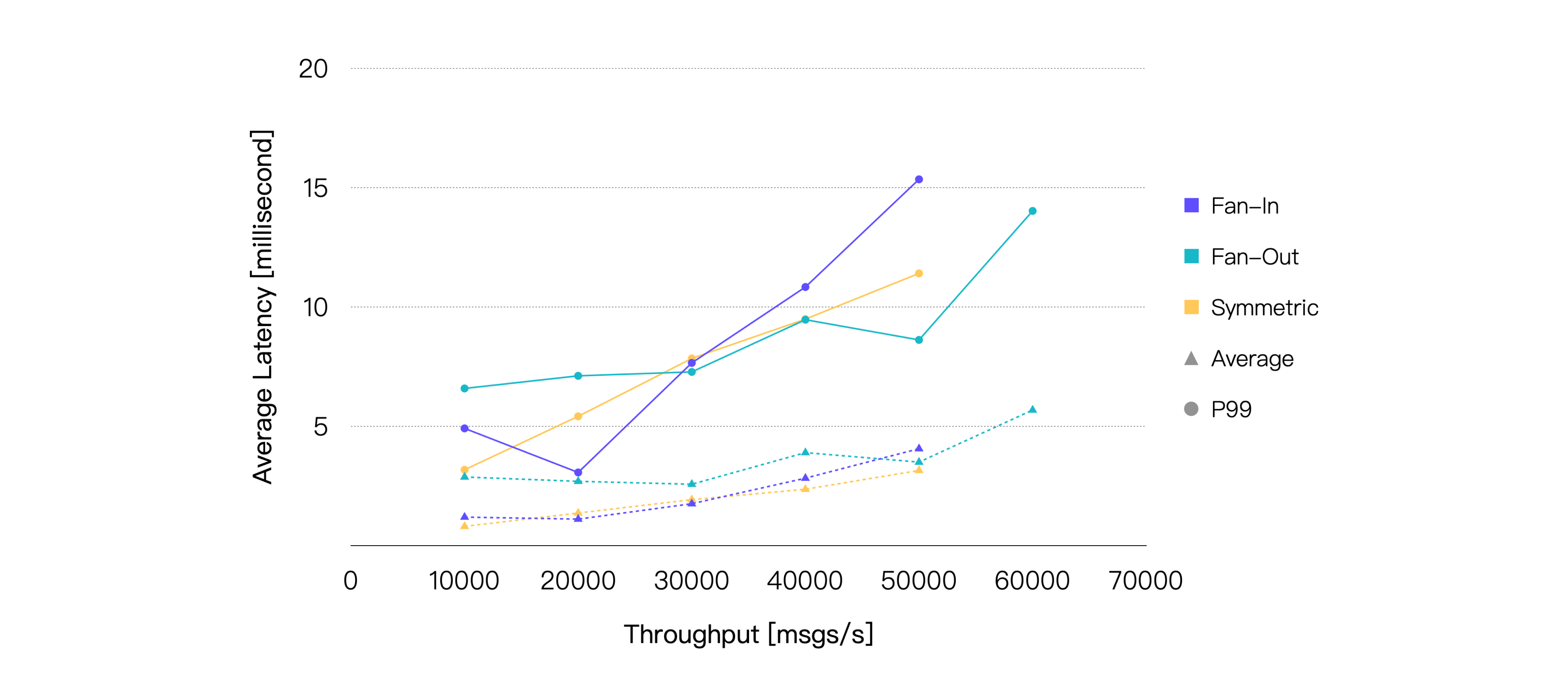
メッセージレイテンシのみを考慮すると、3つのシナリオのパフォーマンスは実際には非常に近いことが分かります。さらに、同じ負荷条件下ではファンアウトシナリオが一貫してCPU消費が低くなっています。したがって、CPU使用率75%を閾値とすると、ファンアウトシナリオは他の2つのシナリオより高いスループットを達成できることが明らかです。
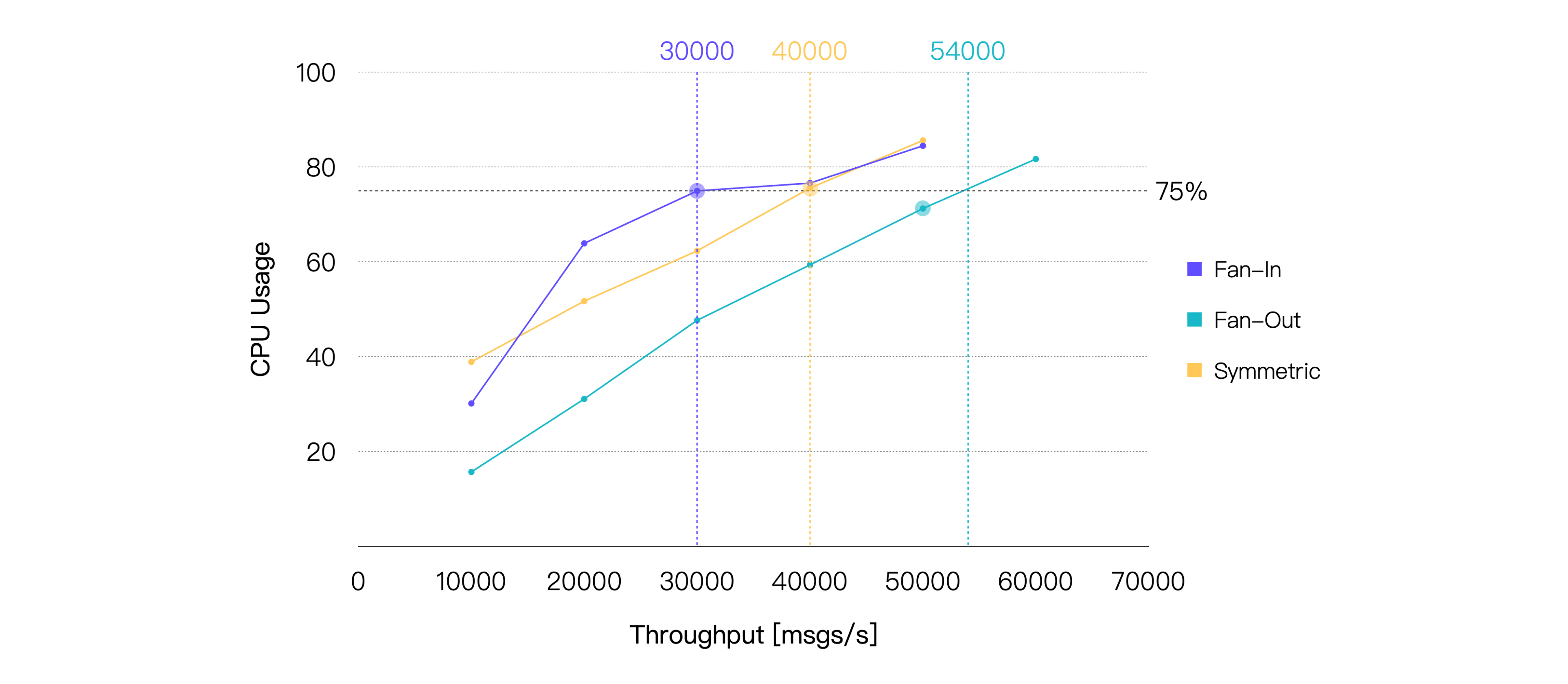
| シナリオ | 推奨負荷 TPS(イン+アウト) | 平均CPU使用率 %(1 - アイドル) | 平均メモリ使用率 % | 平均レイテンシ ms | P99レイテンシ ms |
|---|---|---|---|---|---|
| ファンイン | 30K | 74.96 | 6.71 | 1.75 | 7.651 |
| ファンアウト | 50K | 71.25 | 6.41 | 3.493 | 8.614 |
| シンメトリック | 40K | 75.56 | 6.82 | 2.356 | 9.485 |
シナリオ4:ブリッジング時のEMQXパフォーマンス
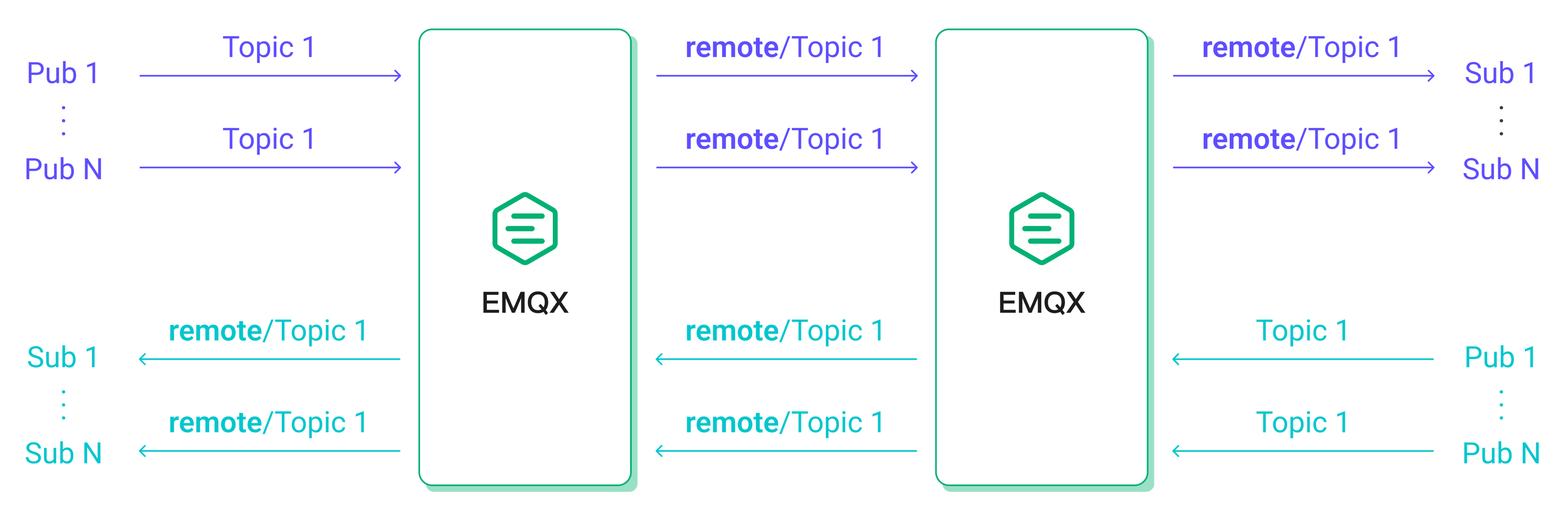
MQTTブリッジングは、あるMQTTサーバーから別のMQTTサーバーへメッセージを転送する機能であり、エッジゲートウェイからクラウドサーバーへのメッセージ集約や、2つのMQTTクラスター間のメッセージ連携など、さまざまなユースケースに対応します。
本テストシナリオでは、MQTTサーバー1に接続された500台のパブリッシャーがパブリッシュしたメッセージをMQTTサーバー2にブリッジし、MQTTサーバー2に接続された500台のサブスクライバーが受信します。同時に、MQTTサーバー2に接続された追加の500台のパブリッシャーがパブリッシュしたメッセージをMQTTサーバー1に接続された500台のサブスクライバーが受信します。
この構成により、クライアントのメッセージパブリッシュレートが同一の場合、EMQX内のインバウンドおよびアウトバウンドメッセージレートはブリッジなしのシンメトリックシナリオに近くなり、両者のパフォーマンス比較が可能となります。
メッセージのQoSレベルを1、ペイロードサイズを128バイトに固定し、最終的なテスト結果は以下の通りです。
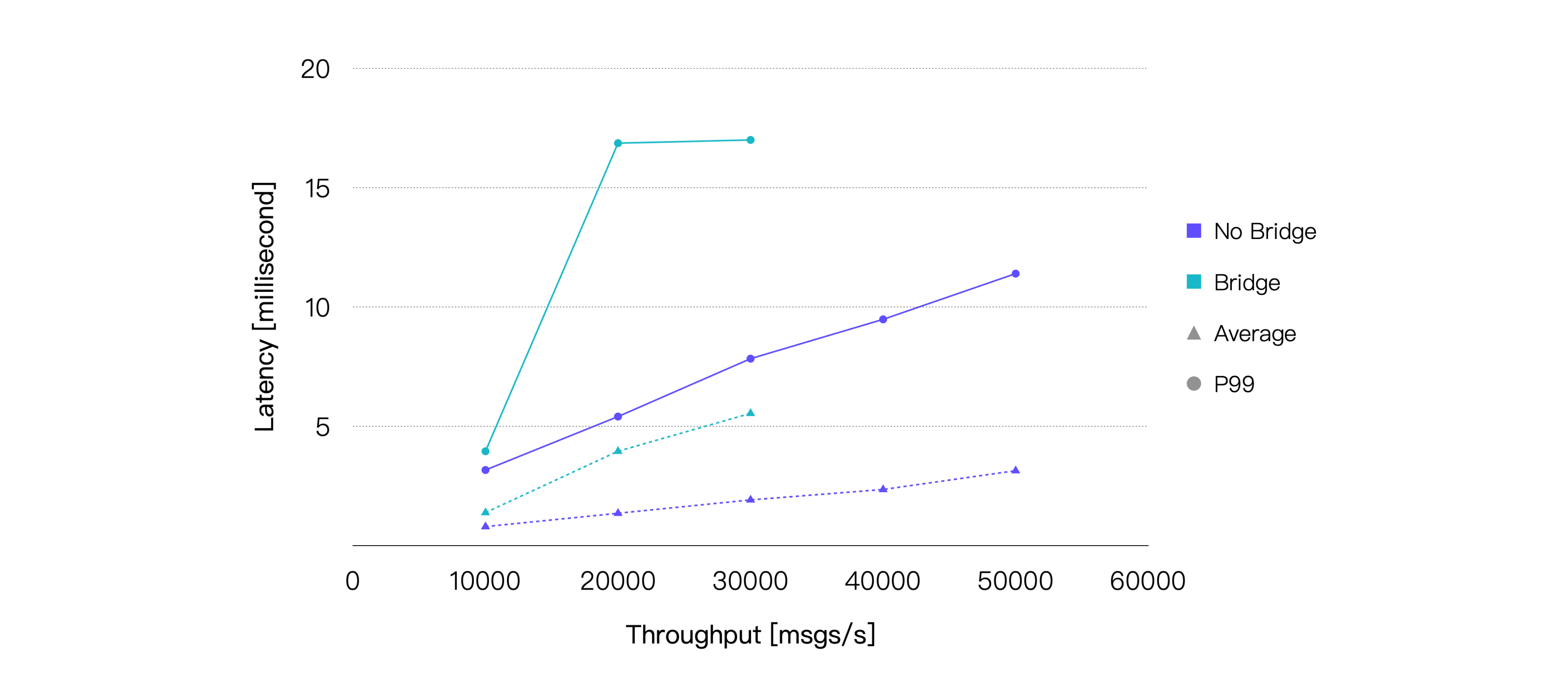
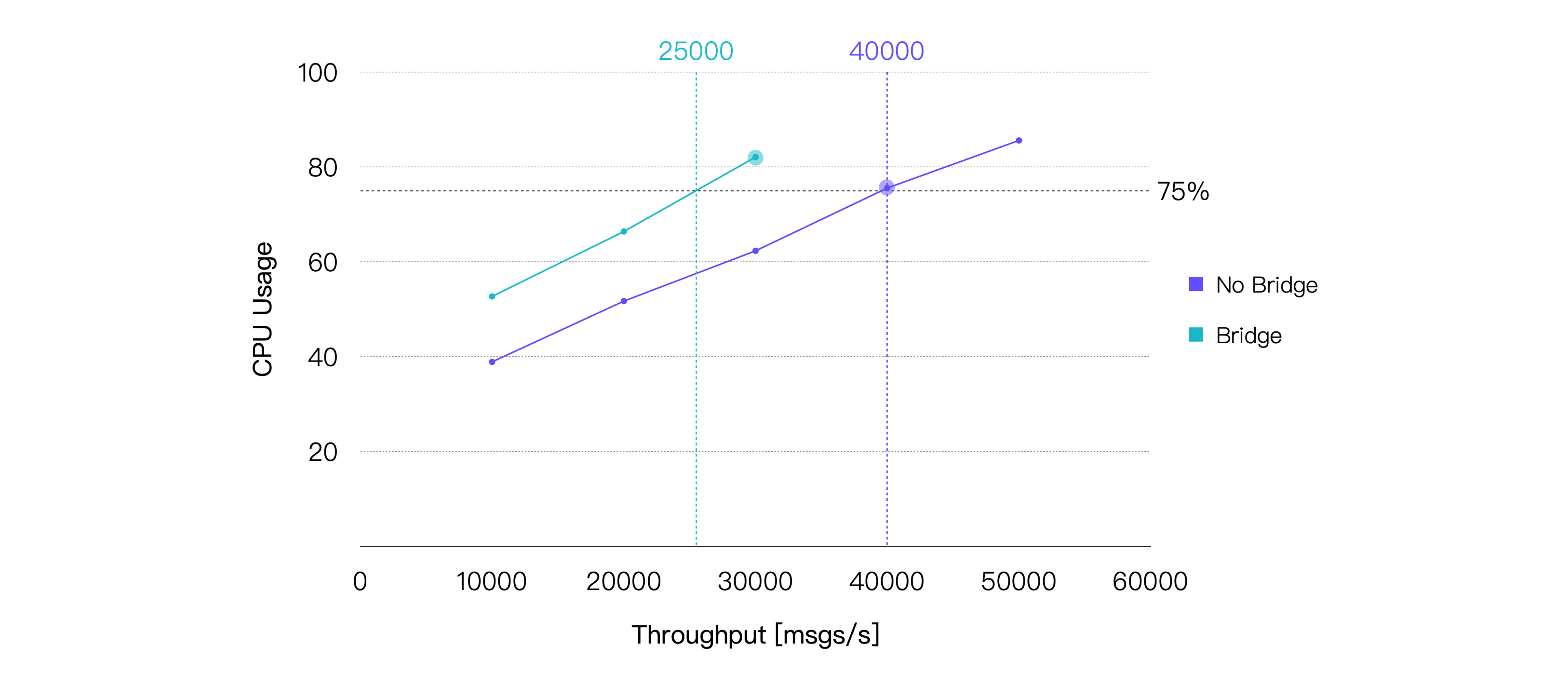
ブリッジングはメッセージ配信過程に追加の中継を挟むため、エンドツーエンドのメッセージレイテンシが増加します。また、CPU消費も増加します。テスト結果はこれらの傾向を裏付けています。本テストで使用したハードウェア仕様に基づき、平均CPU使用率が約75%となるブリッジングシナリオの推奨負荷は約25K TPSです。CPU使用率の差が最も小さいデータポイントのテスト結果は以下の通りです。
| 推奨負荷 TPS(イン+アウト) | 平均CPU使用率 %(1 - アイドル) | 平均メモリ使用率 % | 平均レイテンシ ms | P99レイテンシ ms |
|---|---|---|---|---|
| 30K | 82.09 | 5.6 | 5.547 | 17.004 |