MQTTデータをInfluxDBに取り込む
InfluxDBは時系列データの保存と解析に特化したデータベースです。高いデータスループット性能と安定した動作により、IoT(モノのインターネット)分野での利用に非常に適しています。EMQXは現在、InfluxDB Cloud、InfluxDB OSS、InfluxDB Enterpriseの主要なバージョンとの接続をサポートしています。
本ページでは、EMQXとInfluxDB間のデータ統合について、実践的な手順を交えながら包括的に解説します。
動作の仕組み
InfluxDBデータ統合は、EMQXに標準搭載された機能であり、EMQXのリアルタイムデータキャプチャおよび転送機能とInfluxDBのデータ保存・解析機能を組み合わせています。組み込みのルールエンジンコンポーネントにより、EMQXからInfluxDBへのデータ取り込みを簡素化し、複雑なコーディングを不要にします。EMQXはルールエンジンとSinkを介してデバイスデータをInfluxDBに転送し保存・解析を行います。InfluxDBは解析結果としてレポートやチャートなどを生成し、InfluxDBの可視化ツールを通じてユーザーに提供します。
以下の図は、エネルギー貯蔵シナリオにおけるEMQXとInfluxDBの典型的なデータ統合アーキテクチャを示しています。
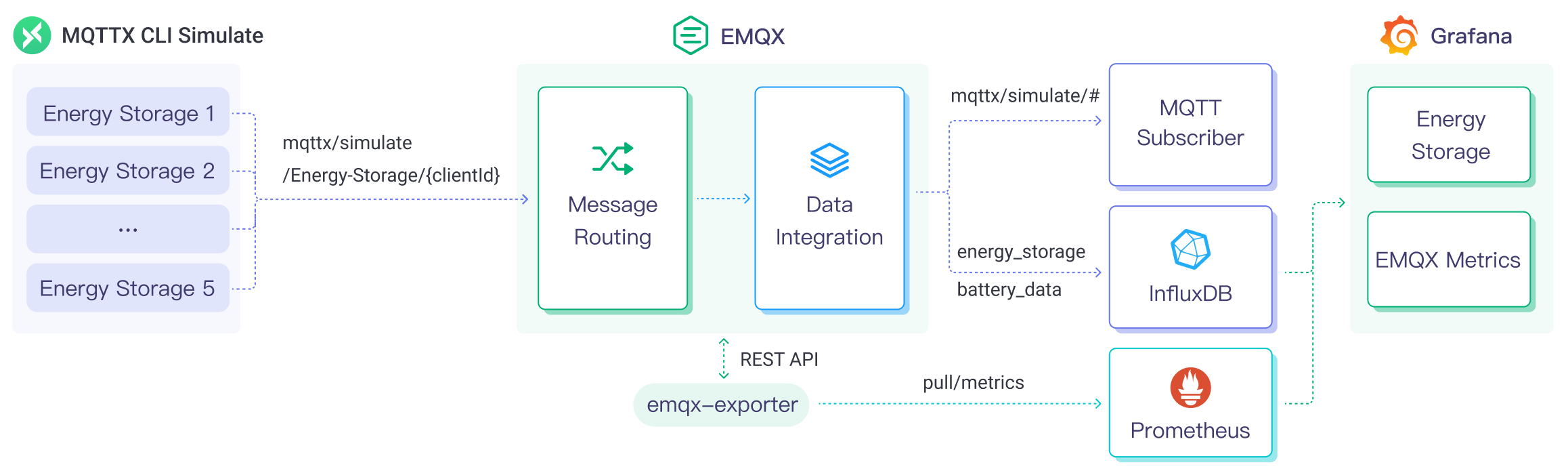
EMQXとInfluxDBは、エネルギー消費データをリアルタイムに効率よく収集・解析するための拡張可能なIoTプラットフォームを提供します。このアーキテクチャでは、EMQXがIoTプラットフォームとしてデバイスの接続、メッセージ伝送、データルーティングを担当し、InfluxDBがデータ保存および解析プラットフォームとして機能します。ワークフローは以下の通りです:
- メッセージのパブリッシュと受信:エネルギー貯蔵機器や産業用IoT機器はMQTTプロトコルを通じてEMQXに接続し、電力消費量、入出力電力などのデータを定期的にパブリッシュします。EMQXはこれらのメッセージを受信すると、ルールエンジン内でマッチング処理を開始します。
- メッセージデータの処理:組み込みのルールエンジンを用いて、特定のトピックに基づくメッセージを処理します。メッセージが到着するとルールエンジンを通過し、対応するルールにマッチングされ、データ形式の変換、特定情報のフィルタリング、メッセージへのコンテキスト情報付加などの処理が行われます。
- InfluxDBへのデータ取り込み:ルールエンジンで定義されたルールがトリガーとなり、InfluxDBへの書き込み操作が実行されます。InfluxDB SinkはLine Protocolのテンプレートを提供し、メッセージ内の特定フィールドをInfluxDBの対応するメジャメントやフィールドに柔軟にマッピングできます。
エネルギー消費データがInfluxDBに書き込まれた後は、Line Protocolを活用してデータ解析が可能です。例えば:
- Grafanaなどの可視化ツールに接続し、エネルギー貯蔵データのチャートを生成する。
- 業務システムに接続し、エネルギー貯蔵機器の状態監視やアラートを行う。
特長と利点
InfluxDBデータ統合は以下の特長と利点を提供します:
- 効率的なデータ処理:EMQXは大量のIoTデバイス接続とメッセージスループットを処理でき、InfluxDBはデータの書き込み、保存、クエリに優れた性能を発揮し、IoTシナリオのデータ処理要件をシステムに過度な負荷をかけずに満たします。
- メッセージ変換:メッセージはEMQXのルールを通じて多様な処理・変換が可能で、InfluxDBに書き込む前に柔軟に加工できます。
- スケーラビリティ:EMQXおよびInfluxDBはクラスター拡張に対応し、ビジネスの成長に応じて水平拡張が可能です。
- 豊富なクエリ機能:InfluxDBは最適化された関数、演算子、インデックス技術を備え、タイムスタンプ付きデータの効率的なクエリと解析を実現し、IoT時系列データから価値ある洞察を正確に抽出します。
- 効率的なストレージ:InfluxDBは高圧縮率のエンコード方式を採用し、ストレージコストを大幅に削減します。また、データ種別ごとに保存期間をカスタマイズでき、不必要なデータのストレージ占有を防ぎます。
はじめる前に
このセクションでは、InfluxDBデータ統合の作成を始める前に必要な準備、特にInfluxDBのインストールと設定について説明します。
前提条件
- EMQXがInfluxDBにデータを書き込む際に従うInfluxDB Line Protocolの知識
- EMQXデータ統合のルールに関する知識
- データ統合に関する知識
InfluxDBのインストールとセットアップ
- Docker経由でInfluxDBをインストールし、Dockerイメージを起動します。
# InfluxDB Dockerイメージの起動
docker run --name influxdb -p 8086:8086 influxdb:2.5.1- InfluxDBが起動したら、ブラウザで http://localhost:8086 にアクセスし、Username、Password、Organization Name、Bucket Nameを設定します。
- InfluxDB UIで Load Data -> API Token をクリックし、全権限トークンの作成手順に従います。
コネクターの作成
本節では、SinkをInfluxDBサーバーに接続するためのコネクター作成手順を示します。
以下の手順は、EMQXとInfluxDBをローカルマシンで実行していることを前提としています。リモート環境の場合は設定を適宜調整してください。
EMQXダッシュボードにログインし、Integration -> Connectors をクリックします。
画面右上の Create をクリックします。
Create Connector ページで InfluxDB を選択し、Next をクリックします。
Configuration ステップで以下の情報を設定します:
以下の設定はすべてのInfluxDBバージョン共通です:
- Connector Name:コネクターの一意な名前。英数字のみで構成し、例:
my_influxdb - Description(任意):コネクターの簡単な説明
- Server Host:InfluxDBサーバーのアドレス。例:
127.0.0.1:8086。InfluxDB Cloudの場合はポート443(例:{url}:443)を指定し、TLSを有効にします。 - Version of InfluxDB:使用するInfluxDBのバージョンを選択。
v1、v2(デフォルト)、v3がサポートされています。 - Enable TLS:InfluxDBサーバーがTLS接続を要求する場合に有効化します。詳細は外部リソースアクセスのTLS有効化を参照してください。
選択したInfluxDBバージョンにより必要な設定項目が異なります。以下の表をご参照ください。値はInfluxDBのインストールとセットアップの設定と一致させてください。
設定項目 InfluxDB v1 InfluxDB v2 InfluxDB v3 認証方式 ユーザー名 / パスワード トークン トークン Token - 必須 必須 Username 任意 - - Password 任意 - - Organization - 必須 - Bucket - 必須 - Database Name 必須 - 必須 補足:
- InfluxDB v1では、EMQXは指定したデータベースに直接書き込み、ユーザー名/パスワード認証は任意です。
- InfluxDB v2では、組織とバケットモデルを使用し、トークンは指定バケットへの書き込み権限を持つ必要があります。
- InfluxDB v3では、v1に似たデータベースベースのモデルを採用しつつ、トークン認証を利用します。
- Connector Name:コネクターの一意な名前。英数字のみで構成し、例:
Createをクリックする前に、Test ConnectivityをクリックしてEMQXがInfluxDBサーバーに正常に接続できるか確認できます。
Createをクリックしてコネクター作成を完了します。
作成後は、Back to Connector Listを選択するか、続けてCreate RuleをクリックしてMQTTデータをInfluxDBに転送するルールとSinkを定義できます。詳細はInfluxDB Sinkを使ったルールの作成を参照してください。
InfluxDB Sinkを使ったルールの作成
このセクションでは、EMQXでソースMQTTトピック t/# からのメッセージを処理し、設定済みのSinkを通じてInfluxDBに送信するルールの作成方法を説明します。
EMQXダッシュボードにアクセスし、左側ナビゲーションメニューから Integration -> Rules をクリックします。
画面右上の Create をクリックします。
ルール作成ページで、ルールIDに
my_ruleを入力します。SQL Editorでルールを設定します。例えば、トピック
t/#のMQTTメッセージをInfluxDBに保存したい場合、以下のSQL文を使用します。TIP
独自のSQL文を指定する場合は、後で設定するSinkのデータ形式に含まれるすべての変数が
SELECT部分に含まれていることを確認してください。sqlSELECT * FROM "t/#"注:初心者の方は、SQL Examplesをクリックし、Enable Testを有効にしてSQLルールの学習とテストを行うことを推奨します。
- Add Action ボタンをクリックし、ルールがトリガーするアクションを定義します。このアクションにより、EMQXはルールで処理したデータをInfluxDBに送信します。
Type of Action ドロップダウンリストから
InfluxDBを選択します。Action はデフォルトのCreate Actionのままにします。既に作成済みのSinkがあれば選択可能ですが、この例では新規Sinkを作成します。Sinkの名前を入力します。名前は英数字の大文字・小文字を組み合わせてください。
Connector ドロップダウンから先に作成した
my_influxdbを選択します。新しいコネクターを作成する場合は、ドロップダウン横のボタンをクリックしてください。設定パラメータの詳細はコネクターの作成を参照してください。Time Precision を指定します。デフォルトは
millisecondです。Data Format を
JSONまたはLine Protocolのいずれかから選択し、InfluxDBに書き込むデータの解析方法を指定します。- JSON形式の場合、Measurement、Timestamp、Fields、Tagsのデータ解析方法を定義します。すべてのキー値は変数またはプレースホルダーにでき、InfluxDB Line Protocolに従って設定可能です。FieldsはCSVファイルによる一括設定もサポートしています。詳細は一括設定を参照してください。
- Line Protocol形式の場合、InfluxDB Line Protocolの構文に従い、メジャメント、タグセット、フィールドセット、タイムスタンプをテキスト形式で指定します。プレースホルダーも利用可能です。
TIP
- InfluxDB 1.xまたは2.xに符号付き整数型の値を書き込む場合、プレースホルダーの後に
iを付けます。例:${payload.int}i。詳細はInfluxDB 1.8で整数値を記述する方法を参照してください。 - 符号なし整数型の値を書き込む場合は、プレースホルダーの後に
uを付けます。例:${payload.int}u。詳細は同上リンクを参照してください。
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義できます。プライマリSinkがメッセージ処理に失敗した場合にこれらがトリガーされます。詳細はフォールバックアクションを参照してください。
詳細設定(任意):詳細は高度な設定を参照してください。
Createをクリックする前に、Test ConnectivityをクリックしてSinkがInfluxDBサーバーに接続可能かテストできます。
CreateをクリックしてSink作成を完了します。ルール作成ページのAction Outputsタブに新しいSinkが表示されます。
ルール作成ページで設定内容を確認し、Createボタンをクリックしてルールを生成します。
これでルールが正常に作成され、Ruleページに新しいルールが表示されます。**Actions(Sink)**タブをクリックすると、新しいInfluxDB Sinkを確認できます。
また、Integration -> Flow Designerをクリックするとトポロジーが表示され、トピック t/# のメッセージがルール my_rule によって解析され、InfluxDBに送信・保存されていることが確認できます。
一括設定
InfluxDBのデータエントリは通常数百のフィールドを含むため、データ形式の設定は複雑になりがちです。これに対応するため、EMQXはフィールドの一括設定機能を提供しています。
JSON形式でデータ形式を設定する際、CSVファイルからフィールドのキー・バリューのペアを一括インポートできます。
FieldsテーブルのBatch Settingボタンをクリックし、Import Batch Settingポップアップを開きます。
指示に従い、一括設定テンプレートファイルをダウンロードし、テンプレートにフィールドのキー・バリューを記入します。テンプレートのデフォルト内容は以下の通りです:
Field Value 備考(任意) temp ${payload.temp} hum ${payload.hum} precip ${payload.precip}i フィールド値に iを付けてInfluxDBに整数として保存する。- Field:フィールドキー。定数または
${var}形式のプレースホルダーをサポート。 - Value:フィールド値。定数またはプレースホルダーをサポートし、Line Protocolに従い型識別子を付加可能。
- 備考:CSVファイル内の注釈用で、EMQXにはインポートされません。
CSVファイルの一括設定データは2048行を超えないようにしてください。
- Field:フィールドキー。定数または
記入済みテンプレートファイルを保存し、Import Batch SettingポップアップにアップロードしてImportをクリックし、一括設定を完了します。
インポート後、Fields設定テーブルでキー・バリューをさらに調整できます。
ルールのテスト
MQTTXを使ってトピック t/1 にメッセージを送信し、オンライン/オフラインイベントをトリガーします。
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "hello InfluxDB" }'Sinkの稼働状況を確認すると、新規の受信メッセージと送信メッセージがそれぞれ1件ずつあるはずです。
InfluxDB UIのData Explorerウィンドウで、メッセージがInfluxDBに書き込まれていることを確認できます。
高度な設定
このセクションでは、InfluxDBコネクターおよびSinkの高度な設定オプションについて詳述します。ダッシュボードでコネクターやSinkを設定する際、Advanced Settingsに移動して以下のパラメータをニーズに合わせて調整できます。
| 項目 | 説明 | 推奨値 |
|---|---|---|
| Start Timeout | コネクターが自動起動したリソースが正常状態になるまで待機する最大時間(秒)。リソース作成要求に応答する前に、InfluxDBのデータベースインスタンスなどの接続先リソースが完全に稼働していることを確認するための設定です。 | 5 |
| Buffer Pool Size | EMQXとInfluxDB間の出口型ブリッジでデータフローを管理するバッファワーカープロセス数。これらのプロセスはデータを一時的に保存・処理します。Ingress(入力)専用のSinkでは無効で、0に設定可能です。 | 4 |
| Request TTL | リクエストがバッファに入ってから有効とみなされる最大時間(秒)。TTLを超えるか、InfluxDBからの応答・アックが遅延した場合、リクエストは期限切れと判断されます。 | 45 |
| Health Check Interval | SinkがInfluxDB接続のヘルスチェックを自動実行する間隔(秒)です。 | 15 |
| Max Buffer Queue Size | InfluxDB Sinkの各バッファワーカーがバッファリング可能な最大バイト数。データ転送の効率化のために設定します。 | 1 |
| Max Batch Size | EMQXからInfluxDBへ一度に転送可能なデータバッチの最大サイズ。1に設定すると、データはバッチ化せず個別に送信されます。 | 100 |
| Query Mode | メッセージ送信の最適化のため、asynchronous(非同期)またはsynchronous(同期)モードを選択可能。非同期モードではInfluxDBへの書き込みがMQTTメッセージのパブリッシュ処理をブロックしませんが、InfluxDBへの到達前にクライアントがメッセージを受信する可能性があります。 | Async |
| Inflight Window | SinkがInfluxDBと通信中に同時に存在可能な未応答のクエリ数を制御します。Query Modeがasyncの場合、同一MQTTクライアントからのメッセージを厳密な順序で処理したい場合は1に設定してください。 | 100 |
さらに詳しく
以下のリンクもご参照ください:
ブログ:
1時間で構築するEMQX + InfluxDB + Grafana IoTデータ可視化ソリューション