ConfluentへのMQTTデータストリーミング
Confluent Cloudは、Apache Kafkaをベースにしたレジリエントでスケーラブル、かつフルマネージドのストリーミングデータサービスです。EMQXはルールエンジンとSinkを通じてConfluentとのデータ統合をサポートしており、MQTTデータをConfluentに簡単にストリーミングしてリアルタイム処理、保存、分析を行えます。
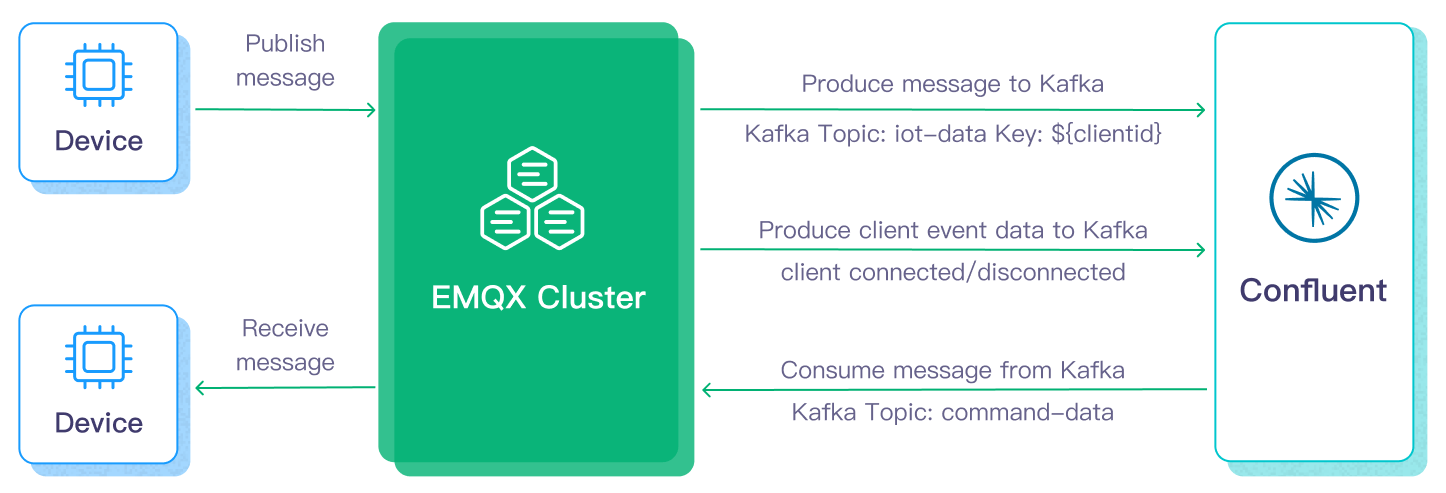
本ページでは主にConfluent統合の機能と利点を紹介し、Confluent Cloudの設定およびEMQXでのConfluent Producer Sinkの作成方法を案内します。
動作概要
Confluentデータ統合はEMQXのすぐに使える機能であり、MQTTベースのIoTデータとConfluentの強力なデータ処理能力を橋渡しします。組み込みのルールエンジンコンポーネントを利用することで、両プラットフォーム間のデータフローと処理を簡素化し、複雑なコーディングを不要にします。
以下の図は自動車IoTにおけるEMQXとConfluentのデータ統合の典型的なアーキテクチャを示しています。
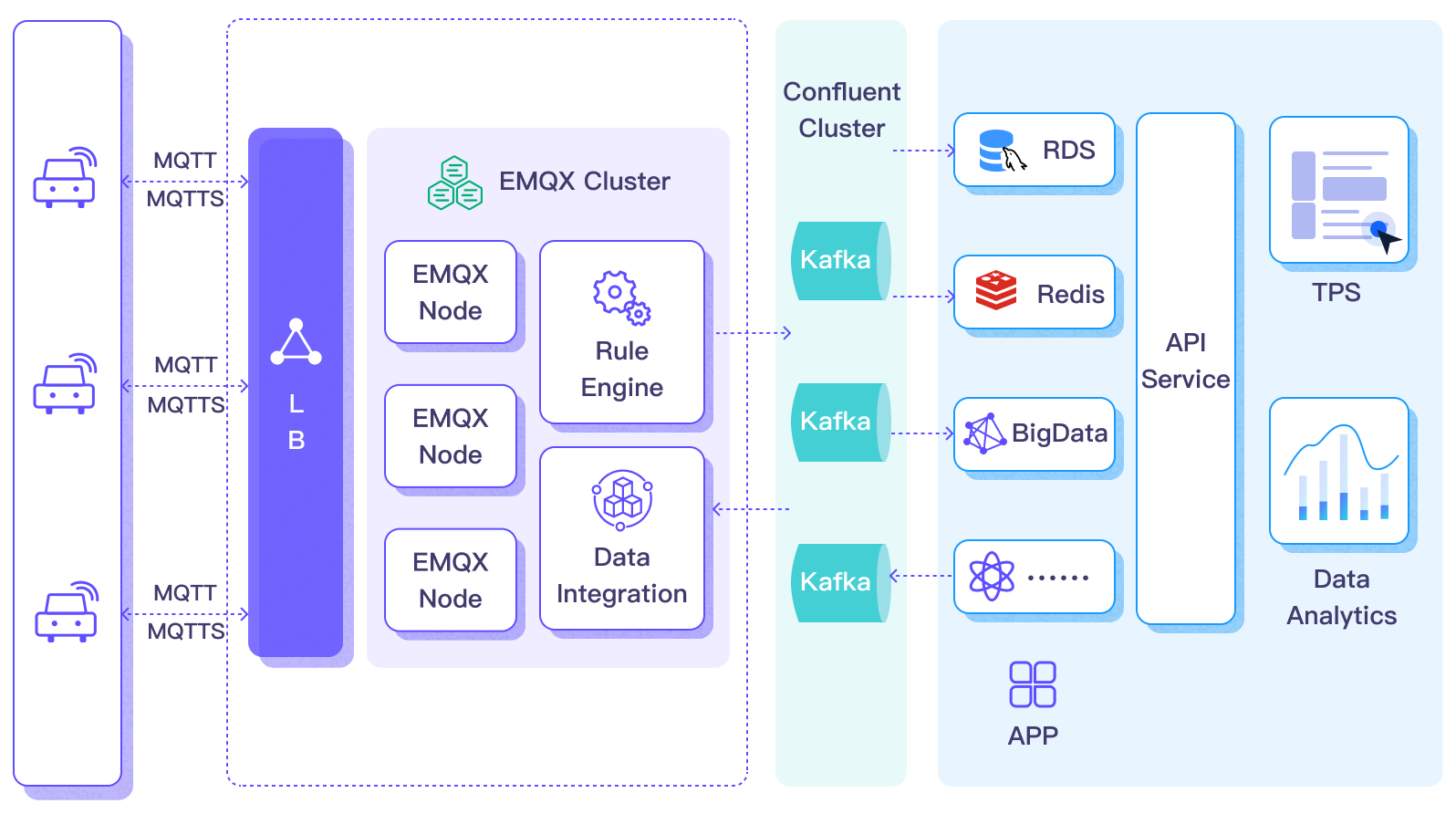
Confluentへのデータの入出力は、Confluent Sink(Confluentへメッセージを送信)とConfluent Source(Confluentからメッセージを受信)を介して行われます。Confluent Sinkを作成した場合、そのワークフローは以下の通りです。
- メッセージのパブリッシュと受信: 車両に接続されたIoTデバイスはMQTTプロトコルを介してEMQXに正常に接続し、定期的に状態データを含むメッセージをパブリッシュします。EMQXがこれらのメッセージを受信すると、ルールエンジン内でマッチング処理を開始します。
- メッセージデータの処理: これらのMQTTメッセージは、組み込みのルールエンジンとメッセージサーバーの協調動作により、トピックマッチングルールに従って処理されます。メッセージが到着しルールエンジンを通過すると、事前定義された処理ルールが評価されます。ペイロード変換を指定するルールがあれば、データフォーマット変換、特定情報のフィルタリング、追加コンテキストによるペイロードの拡充などが適用されます。
- Confluentへのブリッジング: ルールエンジンで定義されたルールはメッセージをConfluentに転送するアクションをトリガーします。Confluent Sink機能を使い、MQTTトピックをConfluentのKafkaトピックにマッピングし、処理済みのメッセージとデータをこれらのトピックに書き込みます。
車両データがConfluentに入力されると、以下のように柔軟にデータにアクセスし活用できます。
- サービスはConfluentと直接連携し、特定トピックのリアルタイムデータストリームを消費してカスタマイズされたビジネス処理を行えます。
- Kafka Streamsを利用してストリーム処理を行い、車両状態の集約や相関をメモリ上でリアルタイム監視できます。
- ConfluentのStream Designerコンポーネントを使い、MySQLやElasticSearchなど外部システムへのデータ出力用コネクターを選択して保存できます。
機能と利点
Confluentとのデータ統合は、以下の機能と利点をビジネスにもたらします。
- 大規模メッセージ伝送の信頼性: EMQXとConfluent Cloudは共に高信頼のクラスター機構を採用し、安定かつ信頼性の高いメッセージ伝送チャネルを構築し、大規模IoTデバイスからのメッセージのロスゼロを保証します。両者ともノード追加による水平スケーリングが可能で、突発的な大規模メッセージにも動的にリソースを調整し、メッセージ伝送の可用性を確保します。
- 強力なデータ処理能力: EMQXのローカルルールエンジンとConfluent Cloudは、デバイスからアプリケーションまでの異なる段階で信頼性の高いストリーミングデータ処理機能を提供します。リアルタイムのデータフィルタリング、フォーマット変換、集約分析などシナリオに応じて対応し、より複雑なIoTメッセージ処理ワークフローを実現し、データ分析アプリケーションのニーズに応えます。
- 強力な統合機能: Confluent Cloudが提供する多様なコネクターを通じて、EMQXは他のデータベース、データウェアハウス、データストリーム処理システムなどと容易に統合でき、アジャイルなデータ分析アプリケーションのための完全なIoTデータワークフローを構築します。
- 高スループット処理能力: 同期・非同期の両書き込みモードをサポートし、リアルタイム優先と性能優先のデータ書き込み戦略を使い分け、シナリオに応じてレイテンシとスループットを柔軟にバランスできます。
- 効果的なトピックマッピング: ブリッジ設定を通じて多数のIoTビジネストピックをKafkaトピックにマッピング可能です。EMQXはMQTTユーザープロパティをKafkaヘッダーにマッピングでき、1対1、1対多、多対多の柔軟なトピックマッピング方式を採用し、MQTTトピックフィルター(ワイルドカード)もサポートします。
これらの機能は統合能力と柔軟性を高め、効果的かつ堅牢なIoTプラットフォームアーキテクチャの構築を支援します。増大するIoTデータは安定したネットワーク接続で伝送され、さらに効果的に保存・管理されます。
はじめる前に
このセクションでは、EMQXダッシュボードでConfluentデータ統合を設定するための準備作業について説明します。
前提条件
Confluent Cloudの設定
Confluentデータ統合を作成する前に、Confluent CloudコンソールでConfluentクラスターを作成し、Confluent Cloud CLIを使ってトピックとAPIキーを作成する必要があります。
クラスターの作成
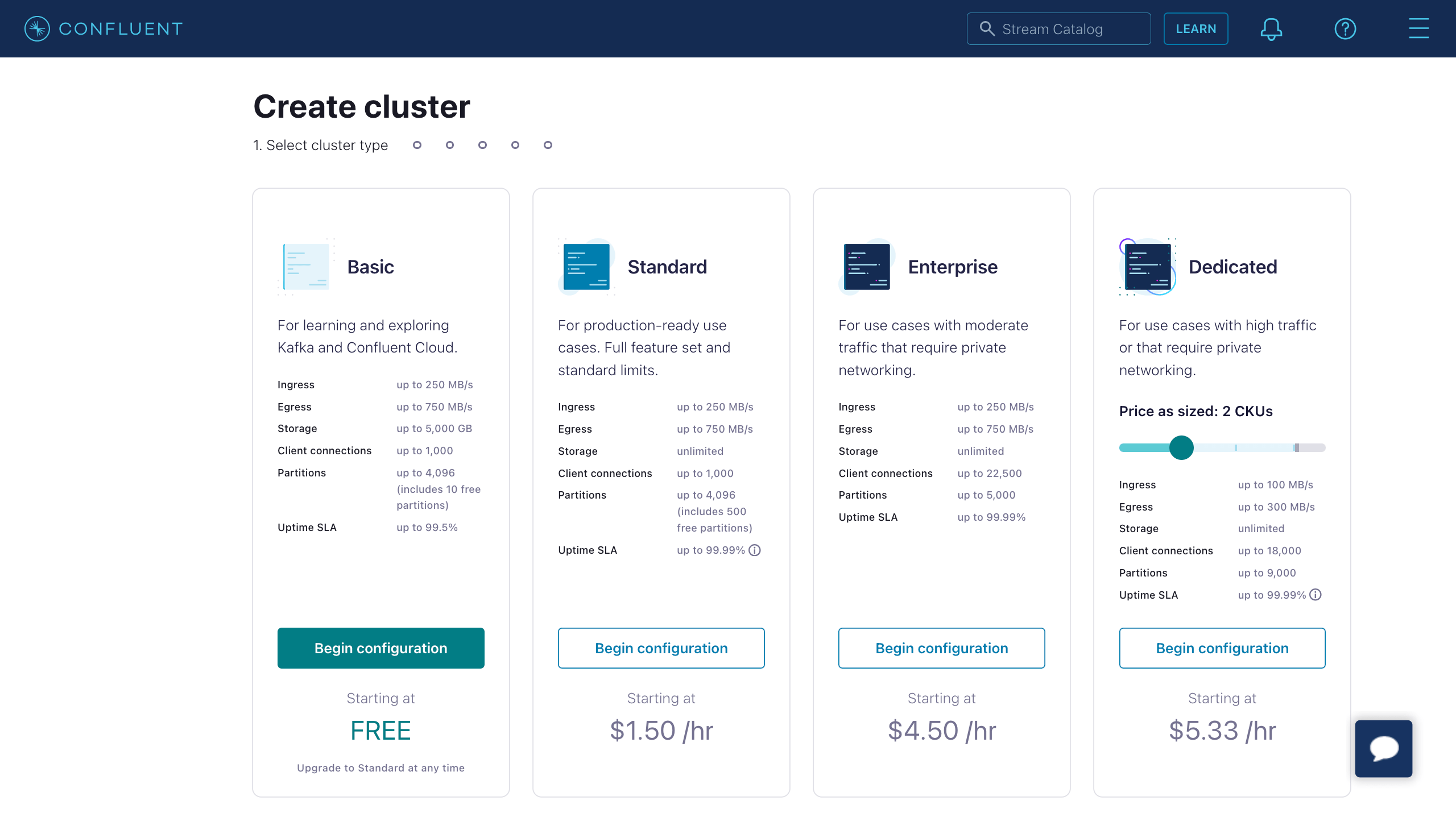
- Confluent Cloudコンソールにログインし、クラスターを作成します。例としてStandardクラスターを選択し、Begin configurationをクリックします。
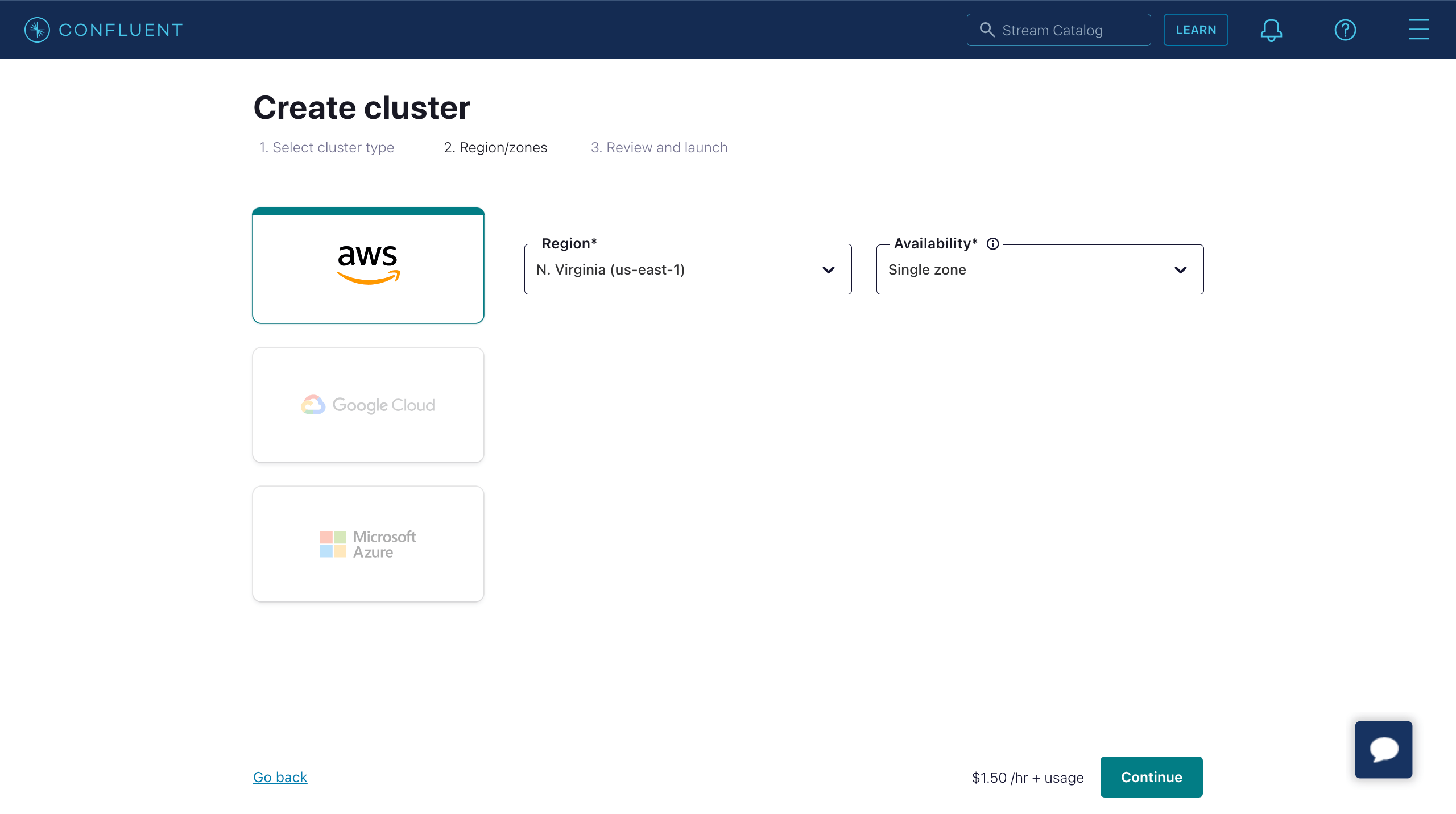
- リージョン/ゾーンを選択します。デプロイメントリージョンがConfluent Cloudのリージョンと一致していることを確認し、Continueをクリックします。
- クラスター名を入力し、Launch clusterをクリックします。
Confluent Cloud CLIでトピックとAPIキーを作成
クラスターがConfluent Cloudで稼働したら、Cluster Overview -> Cluster SettingsページからBootstrap serverのURLを取得できます。
Confluent Cloud CLIを使ってクラスターを管理できます。以下は基本的なCLIコマンドです。
Confluent Cloud CLIのインストール
curl -sL --http1.1 https://cnfl.io/cli | sh -s -- -b /usr/local/bin既にインストール済みの場合は、以下のコマンドでアップデートできます。
confluent updateアカウントにログイン
confluent login --save環境を選択
# 環境一覧表示
confluent environment list
# 環境選択
confluent environment use <environment_id>クラスターを選択
# Kafkaクラスター一覧表示
confluent kafka cluster list
# Kafkaクラスター選択
confluent kafka cluster use <kafka_cluster_id>APIキーとシークレットの利用
既存のAPIキーを使う場合は、以下のコマンドでCLIに追加します。
confluent api-key store --resource <kafka_cluster_id>
Key: <API_KEY>
Secret: <API_SECRET>APIキーとシークレットがない場合は以下で作成可能です。
$ confluent api-key create --resource <kafka_cluster_id>
APIキーの準備に数分かかる場合があります。
APIキーとシークレットは保存してください。シークレットは後で取得できません。
+------------+------------------------------------------------------------------+
| API Key | YZ6R7YO6Q2WK35X7 |
| API Secret | **************************************** |
+------------+------------------------------------------------------------------+CLIに追加後、以下でAPIキーとシークレットを使用します。
confluent api-key use <API_Key> --resource <kafka_cluster_id>トピックの作成
testtopic-inという名前のトピックを作成するには、以下のコマンドを実行します。
confluent kafka topic create testtopic-inトピック一覧は以下で確認できます。
confluent kafka topic listトピックへのメッセージパブリッシュ
以下のコマンドでプロデューサーを作成できます。起動後、メッセージを入力してEnterを押すと、該当トピックにメッセージがパブリッシュされます。
confluent kafka topic produce testtopic-inトピックからのメッセージコンシューム
以下のコマンドでコンシューマーを作成できます。該当トピックの全メッセージが出力されます。
confluent kafka topic consume -b testtopic-inコネクターの作成
Confluent Sinkアクションを追加する前に、EMQXとConfluent Cloud間の接続を確立するためにConfluent Producerコネクターを作成する必要があります。
- EMQXダッシュボードにアクセスし、Integration -> Connectorsをクリックします。
- ページ右上のCreateをクリックし、コネクター選択画面でConfluent Producerを選択してNextをクリックします。
my-confluentなどの名前と説明を入力します。名前はConfluent Sinkとコネクターを紐づけるために使用され、クラスター内で一意である必要があります。- Confluent Cloudへの接続に必要なパラメーターを設定します。
- Bootstrap Hosts: Confluentクラスター設定ページのEndpoints情報に対応します。
- Username と Password: 先にConfluent Cloud CLIで作成したAPIキーとシークレットを入力します。
- その他のオプションはデフォルトのままか、ビジネスニーズに応じて設定してください。
- Createボタンをクリックしてコネクターの作成を完了します。
作成後、コネクターは自動的にConfluent Cloudに接続します。次に、このコネクターを基にしたルールを作成し、コネクターで設定したConfluentクラスターへデータを転送します。
Confluent Sinkを用いたルールの作成
このセクションでは、MQTTトピックt/#のメッセージを処理し、処理結果をConfluentのtesttopic-inトピックに送信するルールをEMQXで作成する方法を示します。
EMQXダッシュボードに入り、Integration -> Rulesをクリックします。
右上のCreateをクリックします。
ルールID(例:
my_rule)を入力します。MQTTメッセージをトピック
t/#からConfluentに転送したい場合、SQL Editorに以下の文を入力します。注意:独自のSQL構文を指定する場合、
SELECT部分にSinkが必要とするすべてのフィールドを含めるようにしてください。sqlSELECT * FROM "t/#"注意:初心者の場合は、SQL ExampleやEnable TestをクリックしてSQLルールの学習やテストが可能です。
- Add Actionボタンをクリックし、ルールでトリガーされるアクションを定義します。Type of Actionのドロップダウンリストから
Confluent Producerを選択し、ActionのドロップダウンはデフォルトのCreate Actionのままか、既存のConfluent Producerアクションを選択します。この例では新規ルールを作成し、ルールに追加します。
- Add Actionボタンをクリックし、ルールでトリガーされるアクションを定義します。Type of Actionのドロップダウンリストから
Sinkの名前と説明を対応するテキストボックスに入力します。
Connectorのドロップダウンから先ほど作成した
my-confluentコネクターを選択します。ドロップダウン横のボタンをクリックするとポップアップで新規コネクターを素早く作成でき、設定パラメーターはコネクターの作成を参照してください。Sinkのデータ送信方法を設定します:
- Kafka Topic:
testtopic-inを入力します。EMQX v5.7.2以降、このフィールドは動的トピック設定もサポートします。詳細はKafka動的トピックの設定を参照してください。 - Kafka Headers: Kafkaメッセージに関連するメタデータやコンテキスト情報を入力します(任意)。プレースホルダーの値はオブジェクトである必要があります。ヘッダー値のエンコードタイプはKafka Header Value Encod Typeのドロップダウンから選択可能です。Addをクリックしてキー・バリューのペアを追加できます。
- Message Key: Kafkaメッセージのキーです。プレーンな文字列か、プレースホルダー(${var})を含む文字列を入力できます。
- Message Value: Kafkaメッセージの値です。プレーンな文字列か、プレースホルダー(${var})を含む文字列を入力できます。
- Partition Strategy: プロデューサーがKafkaのパーティションにメッセージを分配する方法を選択します。
- Compression: Kafkaメッセージ内のレコードを圧縮/解凍するための圧縮アルゴリズムを指定します。
- Kafka Topic:
フォールバックアクション(任意): メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義できます。プライマリSinkがメッセージ処理に失敗した場合にトリガーされます。詳細はフォールバックアクションを参照してください。
詳細設定(任意):詳細設定を参照してください。
CreateボタンをクリックしてSinkの作成を完了します。作成後、ページはCreate Ruleに戻り、新しいSinkがルールアクションに追加されます。
Createボタンをクリックしてルール作成全体を完了します。
これでルールが正常に作成され、Integration -> Rulesページで新規ルールを確認でき、**Actions(Sink)**タブで新規Confluent Producer Sinkも確認できます。
また、Integration -> Flow Designerをクリックするとトポロジーを確認できます。トポロジーを通じて、トピックt/#のメッセージがルールmy_ruleで解析され、Confluentに送信・保存されていることが直感的に把握できます。
Confluent Producerルールのテスト
Confluent Producerルールが期待通りに動作するかテストするため、MQTTXを使ってクライアントがEMQXにMQTTメッセージをパブリッシュするシミュレーションが可能です。
MQTTXでトピック
t/1にメッセージを送信します。bashmqttx pub -i emqx_c -t t/1 -m '{ "msg": "Hello Confluent" }'**Actions(Sink)**ページでSink名をクリックし統計情報を表示します。Sinkの稼働状況を確認し、新規の受信メッセージ数と送信メッセージ数が1件ずつあることを確認します。
以下のConfluentコマンドで
testtopic-inトピックにメッセージが書き込まれているか確認します。bashconfluent kafka topic consume -b testtopic-in
詳細設定
このセクションでは、コネクターやSink/Sourceのパフォーマンスを最適化し、特定シナリオに応じたカスタマイズ操作が可能な詳細設定オプションを説明します。対応するオブジェクト作成時にAdvanced Settingsを展開し、ビジネスニーズに応じて以下の設定を行えます。
コネクター設定
| 項目 | 説明 | 推奨値 |
|---|---|---|
| Allow Auto Topic Creation | (プロデューサーのみ)有効にすると、クライアントがメタデータ取得リクエストを送信した際にKafkaトピックが存在しなければ自動作成を許可します。 | Disabled |
| Connect Timeout | TCP接続確立の最大待機時間(認証有効時は認証時間も含む) | 5 秒 |
| Start Timeout | コネクターが自動起動したリソースの正常状態到達を待つ最大秒数。これにより、Sinkが接続先リソース(例:Confluentクラスター)が完全に稼働しデータ処理可能になるまで操作を進めないようにします。 | 5 秒 |
| Health Check Interval | コネクターの稼働状態をチェックする間隔 | 15 秒 |
| Min Metadata Refresh Interval | Kafkaブローカーやトピックのメタデータ更新の最短間隔。短すぎるとKafkaサーバーへの負荷が増加します。 | 3 秒 |
| Metadata Request Timeout | Kafkaからメタデータを取得する際の最大待機時間 | 5 秒 |
| Socket Send / Receive Buffer Size | ネットワーク伝送性能最適化のためのソケットバッファサイズ管理 | 1 MB |
| No Delay | システムカーネルがTCPソケットを即時送信するか遅延送信するかを選択。オンの場合は即時送信。オフの場合、送信内容が少ないと最大40ミリ秒の遅延が発生。 | Enabled |
| TCP Keepalive | Kafkaブリッジ接続のTCPキープアライブ設定。接続の長時間非アクティブによる切断防止。Idle, Interval, Probesの3つの数値をカンマ区切りで指定。例:240,30,5は240秒のアイドル後に30秒間隔で5回プローブ送信し応答がなければ切断と判断。 | none |
Confluent Producer Sink設定
| 項目 | 説明 | 推奨値 |
|---|---|---|
| Health Check Interval | Sinkの稼働状態をチェックする間隔 | 15 秒 |
| Max Batch Bytes | Kafkaバッチ内でメッセージを収集する最大バイト数。Kafkaブローカーのデフォルトは1MBだが、EMQXはKafkaメッセージのエンコードオーバーヘッドを考慮し1MBよりやや小さく設定。単一メッセージがこのサイズを超える場合は別バッチで送信。 | 896 KB |
| Required Acks | Kafkaパーティションリーダーがフォロワーから待つ確認応答の種類:all_isr: 全てのインシンクレプリカからの応答を要求leader_only: パーティションリーダーのみからの応答を要求none: Kafkaからの応答は不要 | all_isr |
| Partition Count Refresh Interval | Kafkaプロデューサーがパーティション数増加を検知する間隔。増加検知後、EMQXはpartition_strategyに基づき新パーティションをメッセージ送信に組み込みます。 | 60 秒 |
| Max Inflight | KafkaプロデューサーがKafkaからのアックを受け取る前に送信可能な最大バッチ数(パーティション毎)。値が大きいほどスループットは向上するが、1より大きいとメッセージの順序入れ替わりリスクあり。未確認メッセージ数を制御しシステム負荷を調整。 | 10 秒 |
| Query Mode (Producer) | 非同期または同期のクエリモードを選択し、要件に応じてメッセージ送信を最適化。非同期モードではKafka書き込みがMQTTメッセージパブリッシュをブロックしないが、クライアントがKafka到着前にメッセージを受信する可能性あり。 | Async |
| Synchronous Query Timeout | 同期モード時の最大待機時間。メッセージ送信完了を適時保証し長時間待機を防止。ブリッジクエリモードがSyncの時のみ適用。 | 5 秒 |
| Buffer Mode | メッセージ送信前のバッファリング方式。メモリバッファリングは送信速度向上に寄与。memory: メモリにバッファ。EMQXノード再起動時にメッセージは失われる。disk: ディスクにバッファ。EMQXノード再起動後もメッセージ保持。hybrid: 初めはメモリにバッファし、一定サイズ(segment_bytes設定参照)を超えると徐々にディスクに移行。メモリモード同様、ノード再起動時はメッセージ失われる。 | memory |
| Per-partition Buffer Limit | 各Kafkaパーティションごとの最大バッファサイズ(バイト)。上限に達すると古いメッセージを破棄しバッファ領域を確保。メモリ使用量と性能のバランス調整に有効。 | 2 GB |
| Segment File Bytes | バッファモードがdiskまたはhybridの場合に適用。メッセージ保存用のセグメントファイルサイズを制御し、ディスクストレージの最適化に影響。 | 100 MB |
| Memory Overload Protection | バッファモードがmemoryの場合に適用。メモリ使用過多時に古いバッファメッセージを自動破棄し、システム安定性を確保。注: Linuxシステムのみ有効。 | Disabled |
参考情報
EMQXはConfluent/Kafkaとのデータ統合に関する豊富な学習リソースを提供しています。以下のリンクもご参照ください。
ブログ:
- MQTTとKafkaによるコネクテッドビークルのストリーミングデータパイプライン構築
- MQTTとKafka | IoTメッセージングとストリームデータ統合の実践
- MQTTパフォーマンスベンチマークテスト:EMQX-Kafka統合
ベンチマークレポート: