Redshift に MQTT データを取り込む
Amazon Redshift は、ペタバイト規模のクラウドデータウェアハウスであり、高性能な分析処理向けに設計されたフルマネージドサービスです。PostgreSQL をベースにし、オンライン分析処理(OLAP)に最適化されているため、複雑なクエリや大規模なデータ分析を高速に実行できます。EMQX は Amazon Redshift と直接連携し、IoT デバイスからの MQTT テレメトリをほぼリアルタイムで取り込み、保存します。
本ページでは、EMQX と Redshift 間のデータ統合について包括的に解説し、データ統合の作成および検証手順を実践的に説明します。
動作概要
EMQX における Redshift データ統合は組み込み機能であり、MQTT ベースの IoT データストリームを Amazon Redshift の分散型 PostgreSQL 互換データウェアハウスに直接取り込みます。EMQX の組み込みルールエンジンを活用することで、複雑なカスタムコードを書かずに IoT データを Redshift にストリーミングし、大規模な分析処理が可能です。
以下の図は、EMQX と Redshift 間の典型的なデータ統合アーキテクチャを示しています。
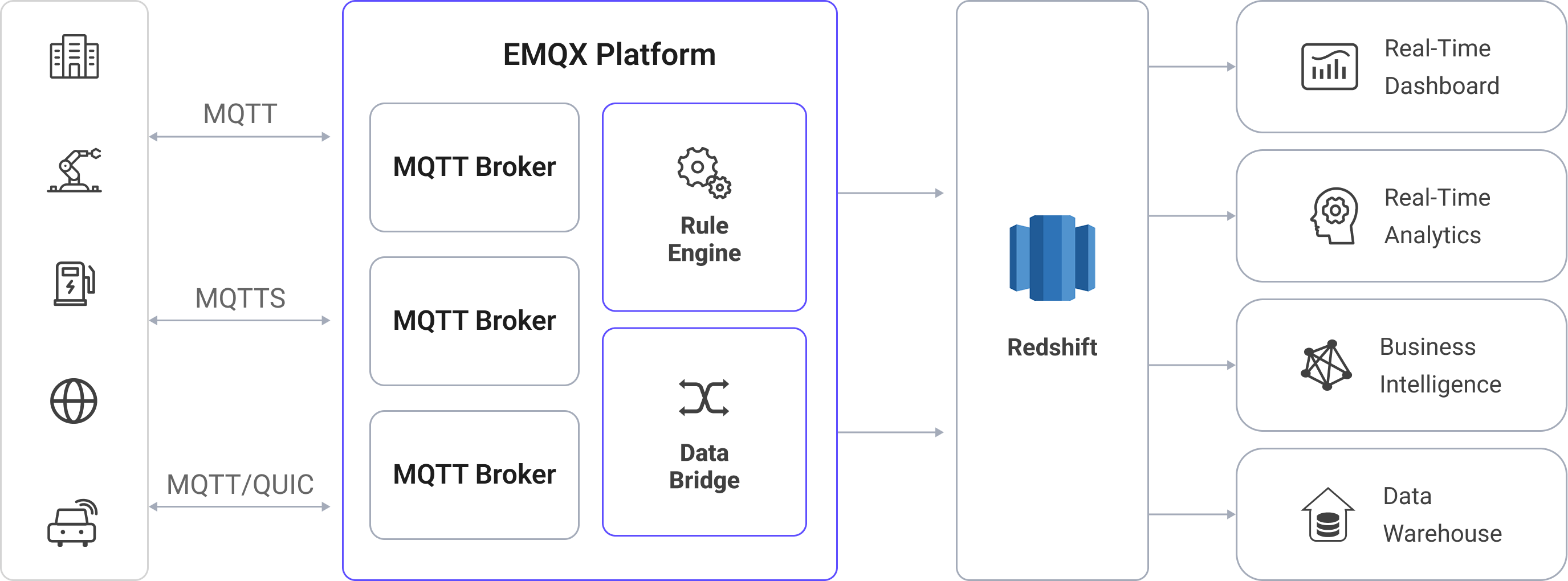
MQTT データを Redshift に取り込む流れは以下の通りです:
- IoT デバイスが EMQX に接続:IoT デバイスが MQTT プロトコルを介して正常に接続されると、オンラインイベントがトリガーされます。イベントにはデバイス ID、送信元 IP アドレスなどの情報が含まれます。
- メッセージのパブリッシュと受信:デバイスは特定のトピックにテレメトリやステータスデータをパブリッシュします。EMQX はこれらのメッセージを受信すると、ルールエンジン内でマッチング処理を開始します。
- ルールエンジンによるメッセージ処理:EMQX のルールエンジンは、トピックやメッセージ内容に基づいて定義されたルールにマッチングし、イベントやメッセージを処理します。処理内容には、データ変換(例:JSON から SQL 用フォーマットへの変換)、フィルタリング、コンテキスト情報によるデータ強化などが含まれ、データベース挿入前に行われます。
- Redshift への書き込み:マッチしたルールは SQL ベースの取り込みをトリガーします。SQL テンプレートを用いて、EMQX は処理済みデータのフィールドを Redshift のテーブルやカラムにマッピングします。高スループットの取り込みには、Amazon S3 からの COPY コマンドや Redshift ストリーミング取り込みを利用し、カラムナーストアに効率的にロードします。Redshift のクエリオプティマイザーと MPP(Massively Parallel Processing)実行エンジンにより、データは即座に分析クエリに利用可能となります。
イベントおよびメッセージデータが Redshift に書き込まれた後は、以下のことが可能です:
- Redshift を Amazon QuickSight、Grafana、Tableau などのツールに接続し、IoT メトリクスやトレンドを追跡するダッシュボードを作成。
- Redshift のデータを AWS の分析・AI/ML サービス(例:Amazon SageMaker)と連携し、異常検知やデバイス挙動の予測を実施。
- Redshift の並列クエリ実行機能を活用し、大規模 IoT データセットに対する集計、結合、時系列分析を実行。過去データとほぼリアルタイムのインサイトを両立。
特長とメリット
Redshift とのデータ統合により、以下の特長と利点が得られます:
- 柔軟なイベント処理:EMQX のルールエンジンを利用し、Redshift はデバイスのライフサイクルイベント(接続、切断、ステータス変更)を低レイテンシで保存・処理可能。Redshift の MPP クエリエンジンと組み合わせることで、障害検知や異常検知、長期利用傾向の分析を迅速に行えます。
- メッセージ変換:メッセージは EMQX ルールで高度に処理・変換されてから Redshift に書き込まれるため、保存データは即分析可能な状態となります。これによりクエリの複雑さが軽減され、下流処理が最適化されます。
- SQL テンプレートによる柔軟なデータ操作:EMQX の SQL テンプレートマッピングを通じて、構造化された IoT データを Redshift のテーブル・カラムに挿入可能。Redshift は PostgreSQL 互換 SQL、JSON 用の SUPER 型などの半構造化データ型、クエリ最適化のための高度なインデックスをサポート。カラムナーストレージ、データ圧縮、ゾーンマップにより、大規模データのスキャン時間を短縮しクエリを高速化します。
- ビジネスプロセスの統合:Redshift は AWS エコシステムとシームレスに統合されており、IoT データを Amazon QuickSight の BI ツール、AWS Glue や AWS Data Pipeline の分析サービス、Amazon SageMaker の AI/ML サービスに接続可能です。
- 高度な地理空間機能:Redshift は GEOMETRY、GEOGRAPHY 型を通じて地理空間データ型と関数をサポートし、ジオフェンシング、位置情報分析、ルート最適化を実現。EMQX のリアルタイム取り込みと組み合わせることで、資産追跡、車両監視、位置ベースのイベントトリガーをほぼリアルタイムで行えます。
- 組み込みのメトリクスと監視:EMQX は各 Redshift シンクのランタイムメトリクスを提供し、Redshift は Amazon CloudWatch と連携してクラスターのパフォーマンス、クエリ実行メトリクス、ストレージ使用量を監視。取り込みから分析までのエンドツーエンドの可観測性を確保します。
はじめる前に
このセクションでは、Redshift 統合を作成する前に必要な準備について説明します。Redshift クラスターの作成やデータベース・テーブルの準備方法を含みます。
前提条件
Amazon Redshift でのデータベースとテーブルの作成
EMQX で Redshift コネクターを設定する前に、Amazon Redshift クラスター(または Serverless ワークグループ)が稼働していること、および IoT データを保存するためのスキーマが準備されていることを確認してください。
Redshift クラスターまたはワークグループをデプロイします。環境の起動にはAmazon Redshift クラスター作成ガイドを参照してください。
データベースユーザーの認証情報を設定します。初期クラスター作成時に、プライマリユーザー(通常は
adminuser)の管理者資格情報を指定します。あるいは、Redshift SQL を使って EMQX 用の専用データベースユーザーを作成します。このユーザーは接続、テーブル作成、読み書き権限を持つ必要があります。例:
sqlCREATE USER emqx_user PASSWORD 'YourStrongPassword1';詳細はRedshift 入門ガイドおよびユーザーガイドを参照してください。
後で EMQX のコネクター設定に使用するため、ユーザー名(
emqx_user)とパスワードを控えておいてください。psql、SQL Workbench/J、DBeaver などの PostgreSQL 互換クライアントを使用し、ホスト名、ポート、既存のデータベース名(例:デフォルトのdev)、ユーザー名、パスワードでRedshift エンドポイントに接続します。接続後、EMQX からの IoT データの格納先となるターゲットデータベース
emqx_dataを作成します。sqlCREATE DATABASE emqx_data;emqx_dataデータベースに接続し、MQTT メッセージとクライアントイベントデータを格納するためのテーブルを2つ作成します。クライアント ID、トピック、ペイロード、作成時刻を保存するデータテーブル
t_mqtt_msgの作成例:sqlCREATE TABLE t_mqtt_msg ( id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, msgid VARCHAR(64), sender VARCHAR(64), topic VARCHAR(255), qos INTEGER, retain INTEGER, -- ペイロードが JSON の場合は SUPER 型を検討、そうでなければ大きめの VARCHAR を使用 payload SUPER, arrived TIMESTAMPTZ );クライアントのオンライン/オフラインイベントをタイムスタンプ付きで保存する
emqx_client_eventsテーブルの作成例:sqlCREATE TABLE emqx_client_events ( id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, clientid VARCHAR(255), event VARCHAR(255), created_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP );
Redshift コネクターの作成
Redshift シンクを追加する前に、EMQX で Redshift コネクターを作成する必要があります。このコネクターは、EMQX が Amazon Redshift クラスターまたは Serverless ワークグループに接続する方法を定義します。
注意
Amazon Redshift Serverless を使用している場合、コネクターが作成され接続が確立されると、データが書き込まれていなくても課金が発生する可能性があります。未使用のコネクターは削除するか、リソースを一時停止して予期しないコストを回避してください。
EMQX ダッシュボードで、Integration -> Connector に移動します。
画面右上の Create をクリックします。
Create Connector ページで Redshift を選択し、Next をクリックします。
コネクター名を入力します。名前は英数字で始まり、英数字、ハイフン、アンダースコアを含めることができます。例:
my_redshiftRedshift 接続情報を入力します:
- Server Host:Redshift エンドポイントのホスト名(例:
redshift-cluster-1.abc123xyz.us-east-1.redshift.amazonaws.com)。AWS Redshift コンソールの Clusters または Workgroups ページで確認可能。 - Database Name:EMQX データを格納するターゲットデータベース名。例:
emqx_data - Username:データ挿入権限を持つデータベースユーザー名。例:
emqx_user - Password:
emqx_userのパスワード - Enable TLS:Redshift 接続に SSL/TLS 暗号化が必要な場合はオンにします(クラウドサービス接続では推奨)。詳細は外部リソースアクセスの TLSを参照。
- Server Host:Redshift エンドポイントのホスト名(例:
詳細設定(任意):接続プールサイズ、アイドルタイムアウト、リクエストタイムアウトなどの追加設定が可能です。詳細はシンクの機能を参照してください。
Test Connectivity をクリックし、EMQX が指定した設定で Redshift クラスターに正常に接続できるか確認します。
Create をクリックしてコネクターを保存します。
作成後は以下のいずれかを選択できます:
- Back to Connector List をクリックしてコネクター一覧に戻る
- Create Rule をクリックして、このコネクターを利用するルールをすぐに作成する
詳細な例は以下を参照してください:
メッセージ保存用の Redshift シンクを使ったルール作成
このセクションでは、ダッシュボード上で MQTT トピック t/# からのメッセージを処理し、処理済みデータを設定済みの Redshift シンク経由で t_mqtt_msg テーブルに保存するルールの作成方法を説明します。
ダッシュボードの Integration -> Rules ページに移動します。
画面右上の Create をクリックします。
ルール ID に
my_ruleを入力し、SQL エディターにルールを記述します。ここでは、トピックt/#の MQTT メッセージを Redshift に保存する例です。ルールの SELECT 部分で選択するフィールドは、SQL テンプレートで使用するすべての変数を含む必要があります。ルール SQL は以下の通りです:sqlSELECT * FROM "t/#"TIP
初心者の方は SQL Examples をクリックし、Enable Test を有効にして SQL ルールの学習とテストを行うことを推奨します。
- Add Action ボタンをクリックし、ルールでトリガーされるアクションを定義します。このアクションにより、EMQX はルールで処理したデータを Redshift に送信します。
Type of Action のドロップダウンから Redshift を選択し、Action のドロップダウンはデフォルトの
Create Actionのままにするか、既存の Redshift アクションを選択します。この例では新規シンクを作成し、ルールに追加します。シンクの名前と説明をフォームに入力します。
Connector ドロップダウンから、先ほど作成した
my_redshiftを選択します。新しいコネクターを作成する場合は、ドロップダウン横のボタンをクリックしてください。設定パラメーターの詳細はRedshift コネクターの作成を参照。SQL Template を設定します。以下の SQL 文を使ってデータを挿入します。
注意:これはプリペアドステートメント形式の SQLのため、フィールドは引用符で囲まず、文末にセミコロンを付けないでください。
sqlINSERT INTO t_mqtt_msg ( msgid, topic, qos, payload, arrived ) VALUES ( ${id}, ${topic}, ${qos}, ${payload}, timestamp 'epoch' + (${timestamp} :: bigint / 1000) * interval '1 second' )フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義できます。詳細はフォールバックアクションを参照してください。
詳細設定(任意):詳細はシンクの機能を参照してください。
Create をクリックする前に、Test Connectivity をクリックしてシンクが Redshift サーバーに接続できるかテストできます。
Create ボタンをクリックしてシンクの設定を完了します。新しいシンクが Action Outputs に追加されます。
Create Rule ページで設定内容を確認し、Save ボタンをクリックしてルールを生成します。
ルールが正常に作成されると、Integration -> Rules ページで新規ルールを確認でき、Action (Sink) タブで新規 Redshift シンクも確認できます。
また、Integration -> Flow Designer でトポロジーを確認でき、トピック t/# のメッセージがルール my_rule によって解析され、Redshift に書き込まれている様子を可視化できます。
イベント記録用の Redshift シンクを使ったルール作成
このセクションでは、クライアントのオンライン/オフライン状態を記録し、イベントデータを設定済みのシンク経由で Redshift の emqx_client_events テーブルに保存するルールの作成方法を説明します。
手順はメッセージ保存用の Redshift シンクを使ったルール作成とほぼ同様ですが、SQL テンプレートとルール SQL が異なります。
オンライン/オフライン状態記録用の SQL ルール文は以下の通りです:
SELECT
*
FROM
"$events/client_connected", "$events/client_disconnected"イベント記録用の SQL テンプレートは以下の通りです:
注意:これはプリペアドステートメント形式の SQLのため、フィールドは引用符で囲まず、文末にセミコロンを付けないでください。
INSERT INTO emqx_client_events(clientid, event, created_at) VALUES (
${clientid},
${event},
TO_TIMESTAMP((${timestamp} :: bigint)/1000)
)ルールのテスト
MQTTX を使用してトピック t/1 にメッセージを送信し、オンライン/オフラインイベントをトリガーします。
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "hello Redshift" }'2つのシンクの稼働状況を確認します。メッセージ保存用シンクでは新規の受信メッセージと送信メッセージがそれぞれ1件ずつあるはずです。イベント記録用シンクでは2件のイベントレコードが存在します。
t_mqtt_msg データテーブルにデータが書き込まれているか確認します。
emqx_data=# select * from t_mqtt_msg;
id | msgid | sender | topic | qos | retain | payload
| arrived
----+----------------------------------+--------+-------+-----+--------+-------------------------------+---------------------
1 | 0005F298A0F0AEE2F443000012DC0002 | emqx_c | t/1 | 0 | | { "msg": "hello Redshift" } | 2023-01-19 07:10:32
(1 row)emqx_client_events テーブルにデータが書き込まれているか確認します。
emqx_data=# select * from emqx_client_events;
id | clientid | event | created_at
----+----------+---------------------+---------------------
3 | emqx_c | client.connected | 2023-01-19 07:10:32
4 | emqx_c | client.disconnected | 2023-01-19 07:10:32
(2 rows)