Apache Kafka に MQTT データをストリームする
Apache Kafkaは、アプリケーションやシステム間でのデータストリームのリアルタイム転送を処理できる、広く利用されているオープンソースの分散イベントストリーミングプラットフォームです。しかし、KafkaはエッジIoT通信向けに設計されておらず、Kafkaクライアントは安定したネットワーク接続とより多くのハードウェアリソースを必要とします。IoTの領域では、デバイスやアプリケーションから生成されるデータは軽量なMQTTプロトコルを用いて送信されます。EMQXのKafkaとの統合により、ユーザーはMQTTデータをKafkaへシームレスにストリーミングできます。MQTTのデータストリームはKafkaのトピックに取り込まれ、リアルタイムの処理、保存、分析が可能になります。逆に、KafkaのトピックデータはMQTTデバイスに配信され、タイムリーなアクションを実現します。
本ページでは、EMQXとKafkaのデータ統合について紹介し、統合の作成および検証手順を段階的に解説します。
Apache Kafkaとのデータ統合は、MQTTベースのIoTデータとKafkaの強力なデータ処理機能のギャップを埋めるためにEMQXに標準搭載された機能です。組み込みのルールエンジンコンポーネントにより、両プラットフォーム間のデータストリーミングと処理が簡素化され、複雑なコーディングを不要にします。
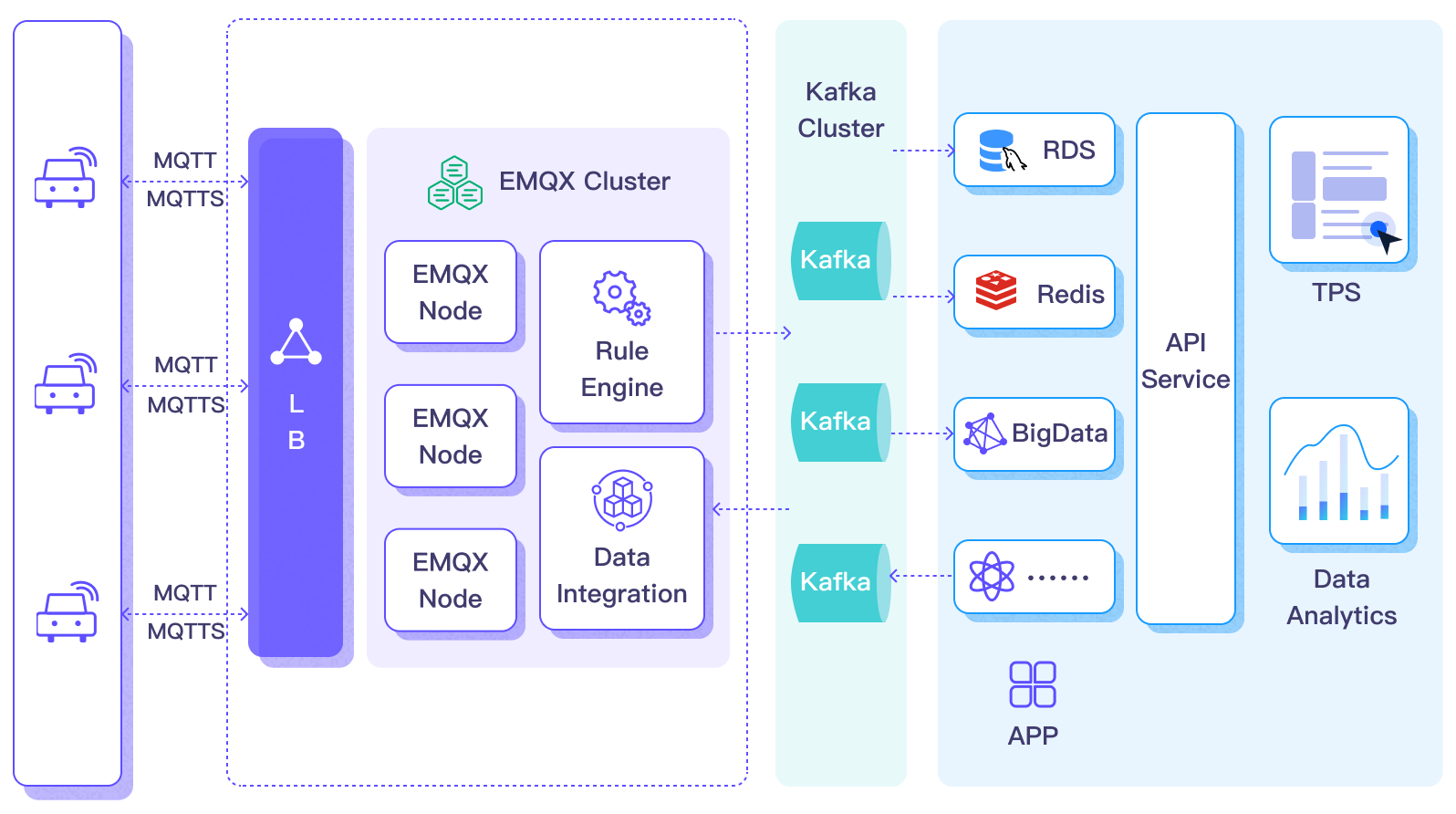
以下の図は、自動車IoTで使われるEMQXとKafka間の典型的なデータ統合アーキテクチャを示しています。
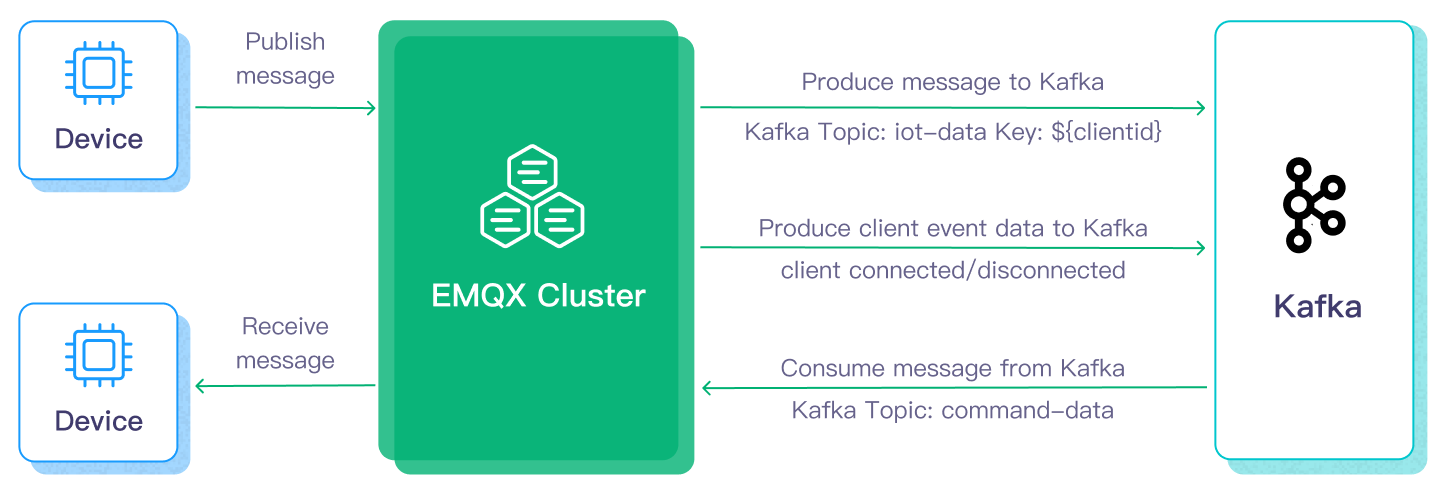
Apache Kafkaへのデータの流入および流出には、それぞれKafka Sink(Kafkaへメッセージを送信)とKafka Source(Kafkaからメッセージを受信)を作成する必要があります。ここではSinkを例に、処理の流れを説明します。
- メッセージのパブリッシュと受信:接続された車両のIoTデバイスはMQTTプロトコルを通じてEMQXに正常に接続し、定期的に状態データを含むメッセージをMQTTでパブリッシュします。EMQXがこれらのメッセージを受信すると、ルールエンジン内でマッチング処理を開始します。
- メッセージデータの処理:組み込みのルールエンジンはブローカーと一体となって動作し、トピックマッチングルールに基づいてMQTTメッセージを処理します。メッセージが到着するとルールエンジンを通過し、定義されたルールを評価します。ペイロード変換が指定されている場合は、データフォーマットの変換、特定情報のフィルタリング、追加コンテキストによるペイロードの拡充などの変換が適用されます。
- Kafkaへのブリッジ:ルールエンジンで定義されたルールがメッセージをKafkaに転送するアクションをトリガーします。Kafkaブリッジ機能を使い、MQTTトピックを事前定義されたKafkaトピックにマッピングし、処理済みのすべてのメッセージとデータをKafkaトピックに書き込みます。
車両データがKafkaに取り込まれた後は、柔軟にデータへアクセスし活用できます。
- サービスはKafkaクライアントと直接統合し、特定トピックからリアルタイムのデータストリームを消費してカスタマイズされた業務処理を実行可能です。
- Kafka Streamsを利用してストリーム処理を行い、車両状態をメモリ内で集約・相関させてリアルタイム監視ができます。
- Kafka Connectコンポーネントを用い、MySQLやElasticSearchなど外部システムへのデータ出力コネクターを選択し、保存が可能です。
特長とメリット
Apache Kafkaとのデータ統合は以下の特長とメリットを提供します。
- 信頼性の高い双方向IoTデータメッセージング:Kafkaと不安定なモバイルネットワーク上で動作するリソース制約のあるIoTデバイス間のデータ通信は、不確実なネットワークでのメッセージングに優れたMQTTプロトコルで処理されます。EMQXはMQTTメッセージをバッチでKafkaに転送するだけでなく、バックエンドシステムからのKafkaメッセージをサブスクライブし、接続されたIoTクライアントに配信します。
- ペイロード変換:メッセージペイロードは送信中に定義されたSQLルールで処理可能です。例えば、総メッセージ数、成功/失敗配信数、メッセージレートなどのリアルタイム指標を含むペイロードは、Kafkaに取り込まれる前にデータ抽出、フィルタリング、拡充、変換を経ることができます。
- 効果的なトピックマッピング:多数のIoTビジネストピックをKafkaトピックにマッピング可能です。EMQXはMQTTユーザープロパティをKafkaヘッダーにマッピングし、1対1、1対多、多対多の柔軟なトピックマッピング方式をサポートし、MQTTトピックフィルター(ワイルドカード)にも対応しています。
- 柔軟なパーティション選択戦略:MQTTトピックやクライアントに基づき、同じKafkaパーティションへメッセージを転送することが可能です。
- 高スループット環境での処理能力:EMQX Kafkaプロデューサーは同期・非同期の両書き込みモードをサポートし、リアルタイム優先やパフォーマンス優先のデータ書き込み戦略を区別可能です。シナリオに応じてレイテンシとスループットのバランスを柔軟に調整できます。
- ランタイムメトリクス:各SinkおよびSourceの総メッセージ数、成功/失敗数、現在のレートなどのランタイムメトリクスを閲覧可能です。
- 動的設定:Dashboardや設定ファイルからSinkおよびSourceを動的に設定できます。
これらの特長により、効果的で堅牢なIoTプラットフォームアーキテクチャの構築が可能となり、増大するIoTデータを安定したネットワーク接続下で送信し、さらに効率的に保存・管理できます。
はじめる前に
このセクションでは、EMQX DashboardでKafka SinkおよびSourceを作成する前に必要な準備事項を説明します。
前提条件
Kafka サーバーのセットアップ
ここでは macOS を例にインストールと起動手順を示します。以下のコマンドで Kafka をインストールし起動できます。
wget https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz
tar -xzf kafka_2.13-3.3.1.tgz
cd kafka_2.13-3.3.1
# KRaft モードで Kafka を起動
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
bin/kafka-server-start.sh config/kraft/server.properties詳細な操作手順は、Kafkaドキュメントのクイックスタートを参照してください。
Kafka トピックの作成
EMQXでデータ統合を作成する前に、関連するKafkaトピックを作成しておく必要があります。以下のコマンドでKafkaに2つのトピックを作成します:testtopic-in(Sink用)とtesttopic-out(Source用)。
bin/kafka-topics.sh --create --topic testtopic-in --bootstrap-server localhost:9092
bin/kafka-topics.sh --create --topic testtopic-out --bootstrap-server localhost:9092Kafka プロデューサーコネクターの作成
Kafka Sinkアクションを追加する前に、EMQXとKafka間の接続を確立するためKafkaプロデューサーコネクターを作成する必要があります。
EMQX Dashboardで Integration -> Connector を開きます。
ページ右上の Create をクリックし、コネクター選択画面で Kafka Producer を選択して Next をクリックします。
EMQX Dashboardで Integration -> Connector を開きます。
ページ右上の Create をクリックし、コネクター選択画面で Kafka Producer を選択して Next をクリックします。
名前と説明を入力します。例:
my-kafka。名前はKafka Sinkとコネクターを関連付けるために使用され、クラスター内で一意である必要があります。Kafka接続に必要なパラメータを設定します:
Bootstrap Hosts:
127.0.0.1:9092と入力します。なお、ここではEMQXとKafkaをローカルで起動している前提です。リモート環境の場合は適宜調整してください。Authentication:Kafkaクラスターで必要な認証方式を選択します。以下の方式をサポートしています:
None:認証なしAWS IAM for MSK:EMQXがEC2インスタンス上にデプロイされている場合のAWS MSKクラスター用Basic Auth:mechanism(plain、scram_sha_256、scram_sha_512のいずれか)とusername、passwordを指定Kerberos:Kerberos PrincipalとKerberos Keytabファイルを指定
詳細は認証方式を参照してください。
暗号化接続を確立する場合は、Enable TLSのトグルをオンにします。TLS接続の詳細は外部リソースアクセスのTLSを参照してください。
Advanced Settings(任意):高度な設定を参照してください。
Createをクリックする前に、Test ConnectionをクリックしてKafkaサーバーへの接続が成功するかテストできます。
Createをクリックする前に、Test ConnectionをクリックしてKafkaサーバーへの接続が成功するかテストできます。
作成後、コネクターは自動的にKafkaに接続します。次に、このコネクターを使ってKafkaクラスターにデータを転送するルールを作成します。
認証方式
EMQXでKafkaコネクターを作成する際、Kafkaクラスターのセキュリティ設定に応じて以下の認証方式から選択可能です。
None:認証なし。
MSK IAM:EMQXがAmazon EC2インスタンス上にデプロイされている場合のAmazon MSKクラスター接続用。
この方式はEC2インスタンスのメタデータサービスを利用し、IAMポリシーに基づく認証トークンを生成します。
重要
MSK IAM認証は、EMQXがEC2インスタンス上で動作しMSKクラスターに接続する場合のみサポートされます。これはEC2インスタンスのメタデータサービスに依存しているためです。
iptablesやnftablesでホストレベルのイグレスフィルタリングを行う場合、169.254.169.254への通信をブロックしないでください。EMQXはMSK IAM認証のためにインスタンスメタデータサービスにアクセスする必要があります。同様の例外は、S3、S3 Tables、DynamoDB、KinesisなどEC2インスタンスメタデータから認証情報を取得するAWSベースの他のコネクターにも適用されます。ルールエンジンポリシーとファイアウォールルールによるSSRF緩和を参照してください。OAuth:OAuth 2.0ベースの認証で、OAuthまたはOIDC対応のKafkaクラスター(例:Confluent CloudやOAuth有効化済みのセルフマネージドKafka)に接続します。
選択時は以下を指定する必要があります:
- Mechanism:
plain、scram_sha_256、scram_sha_512から選択 - UsernameとPassword:Kafkaクラスター認証用の資格情報
- Mechanism:
Kerberos:Kerberos GSSAPI認証。
以下を指定します:
- Kerberos Principal:認証に使用するKerberosのプリンシパル
- Kerberos Keytabファイル:非対話認証に用いるkeytabファイルのパス
重要
Kerberos keytabファイルはすべてのEMQXノードで同一パスに配置し、EMQXサービスユーザーに読み取り権限が必要です。
Kafka Sinkを使ったルールの作成
このセクションでは、MQTTトピックt/#からのメッセージを処理し、Kafkaのtesttopic-inトピックへ処理結果を送信するルールの作成方法を示します。
EMQX Dashboardで Integration -> Rules を開きます。
ページ右上の Create をクリックします。
ルールIDを入力します。例:
my_ruleSQL Editorに以下の文を入力します。これはMQTTトピック
t/#のメッセージをKafkaに転送する例です。注意:独自のSQL文を指定する場合は、Sinkで必要なすべてのフィールドを
SELECT句に含めてください。sqlSELECT * FROM "t/#"TIP
初心者の方は、SQL Examplesをクリックし、Enable Testを使ってSQLルールを学習・テストできます。
TIP
EMQX v5.7.2からはルールSQL内で環境変数を読み取る機能が追加されました。詳細はルールSQLで環境変数を使うを参照してください。
- Add Actionボタンをクリックし、トリガーされるアクションを定義します。Type of Actionドロップダウンから
Kafka Producerを選択し、ActionはデフォルトのCreate Actionのままか、既存のKafka Producerアクションを選択します。本例では新規作成します。
- Add Actionボタンをクリックし、トリガーされるアクションを定義します。Type of Actionドロップダウンから
Sinkの名前と説明を入力します。
Connectorドロップダウンから先ほど作成した
my-kafkaコネクターを選択します。隣のボタンをクリックするとポップアップで新規コネクターを素早く作成可能です。設定パラメータはKafkaプロデューサーコネクターの作成を参照してください。Sinkのデータ送信方法を設定します:
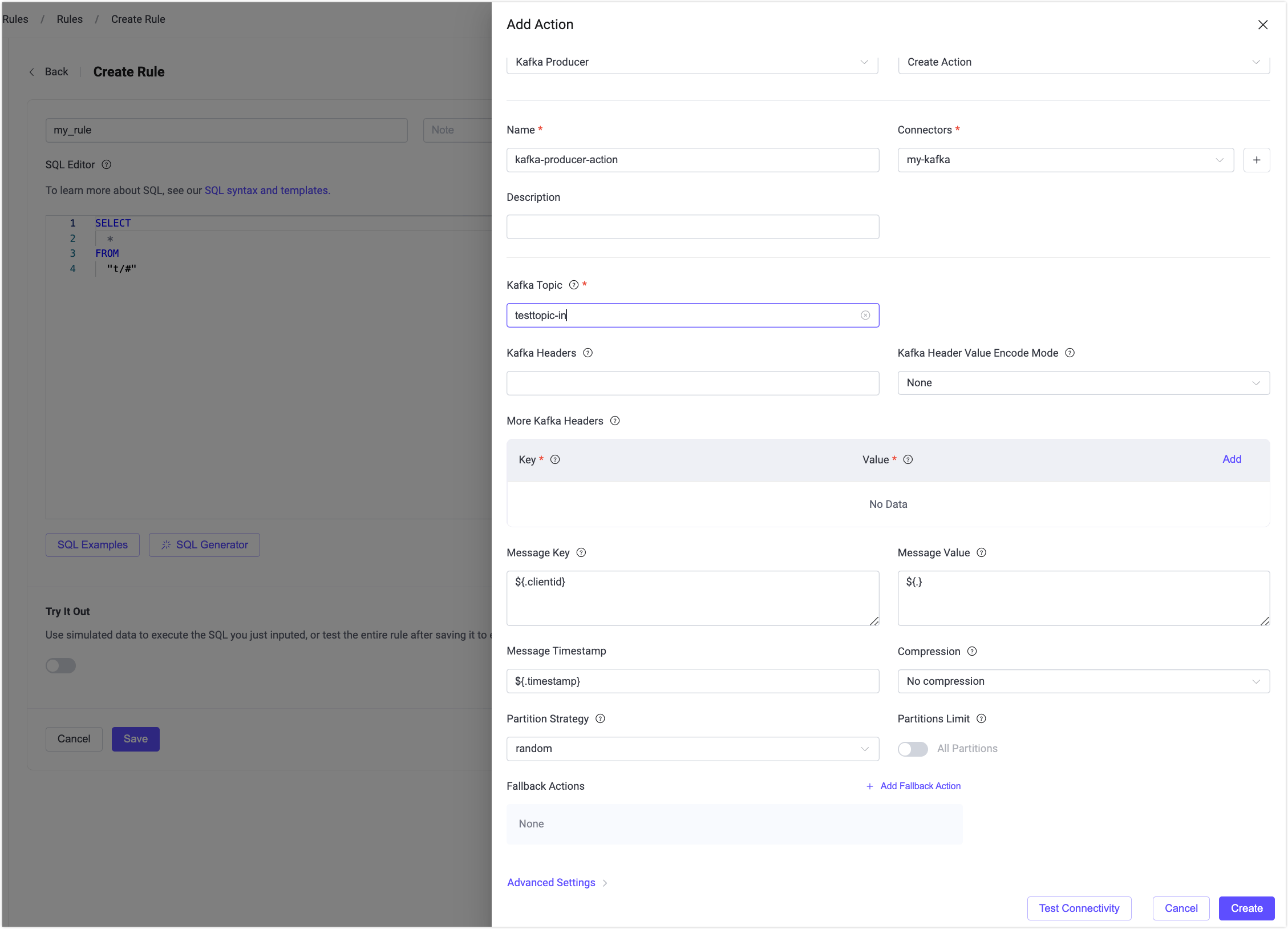
Kafka Topic:
testtopic-inと入力します。EMQX v5.7.2以降、このフィールドは動的トピック設定もサポートします。変数テンプレートの使用を参照してください。Kafka Headers:Kafkaメッセージに関連するメタデータやコンテキスト情報を入力します(任意)。プレースホルダーの値はオブジェクトである必要があります。ヘッダー値のエンコードタイプはKafka Header Value Encod Typeから選択可能です。Addをクリックしてキー・バリューを追加できます。
Message Key:Kafkaメッセージのキー。プレーン文字列または
${var}形式のプレースホルダーが使用可能です。Message Value:Kafkaメッセージの値。プレーン文字列または
${var}形式のプレースホルダーが使用可能です。
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義可能です。詳細はフォールバックアクションを参照してください。
- Compression:Kafkaメッセージのレコード圧縮/解凍に使用する圧縮アルゴリズムを指定します。
Fallback Actions(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義可能です。詳細はフォールバックアクションを参照してください。
Advanced Settings(任意):高度な設定を参照してください。
CreateをクリックしてSinkの作成を完了します。作成後、Create Rule画面に戻り、新規Sinkがルールアクションに追加されます。
Createをクリックしてルール作成を完了します。
これでルールが正常に作成され、Integration -> Rulesページで新規ルールを確認でき、**Actions(Sink)**タブでKafka Producer Sinkも確認できます。
また、Integration -> Flow Designerでトポロジーを表示可能です。トポロジーでは、トピックt/#のメッセージがルールmy_ruleで解析されKafkaに送信・保存される様子を直感的に把握できます。
Kafka動的トピックの設定
EMQX v5.7.2以降、Kafka Producer Sink設定で環境変数や変数テンプレートを用いてKafkaトピックを動的に設定できます。本節ではこれら2つのユースケースを紹介します。
環境変数の使用
EMQX v5.7.2では、ルールSQL処理段階で環境変数から取得した値をメッセージ内のフィールドに動的に割り当てる機能が追加されました。この機能はルールエンジンの組み込みSQL関数getenvを用いてEMQXの環境変数を取得し、その値をSQL処理結果に設定します。この機能の応用例として、Kafka SinkルールアクションのKafkaトピック設定にルール出力結果のフィールドを参照してトピックを設定できます。以下はその例です。
注意
他のシステム環境変数の漏洩を防ぐため、ルールエンジンで使用する環境変数名は固定プレフィックスEMQXVAR_を付ける必要があります。例えば、getenv関数で読み取る変数名がKAFKA_TOPICの場合、環境変数名はEMQXVAR_KAFKA_TOPICと設定してください。
Kafkaを起動し、
testtopic-inトピックを事前作成します。はじめる前にの手順を参照してください。EMQXを起動し環境変数を設定します。zipインストールの場合、起動時に環境変数を直接指定可能です。例としてKafkaトピック
testtopic-inを環境変数EMQXVAR_KAFKA_TOPICに設定:bashEMQXVAR_KAFKA_TOPIC=testtopic-in bin/emqx startコネクターを作成します。Kafka プロデューサーコネクターの作成を参照してください。
Kafka Sinkルールを設定します。SQL Editorに以下を入力:
sqlSELECT getenv('KAFKA_TOPIC') as kafka_topic, payload FROM "t/#"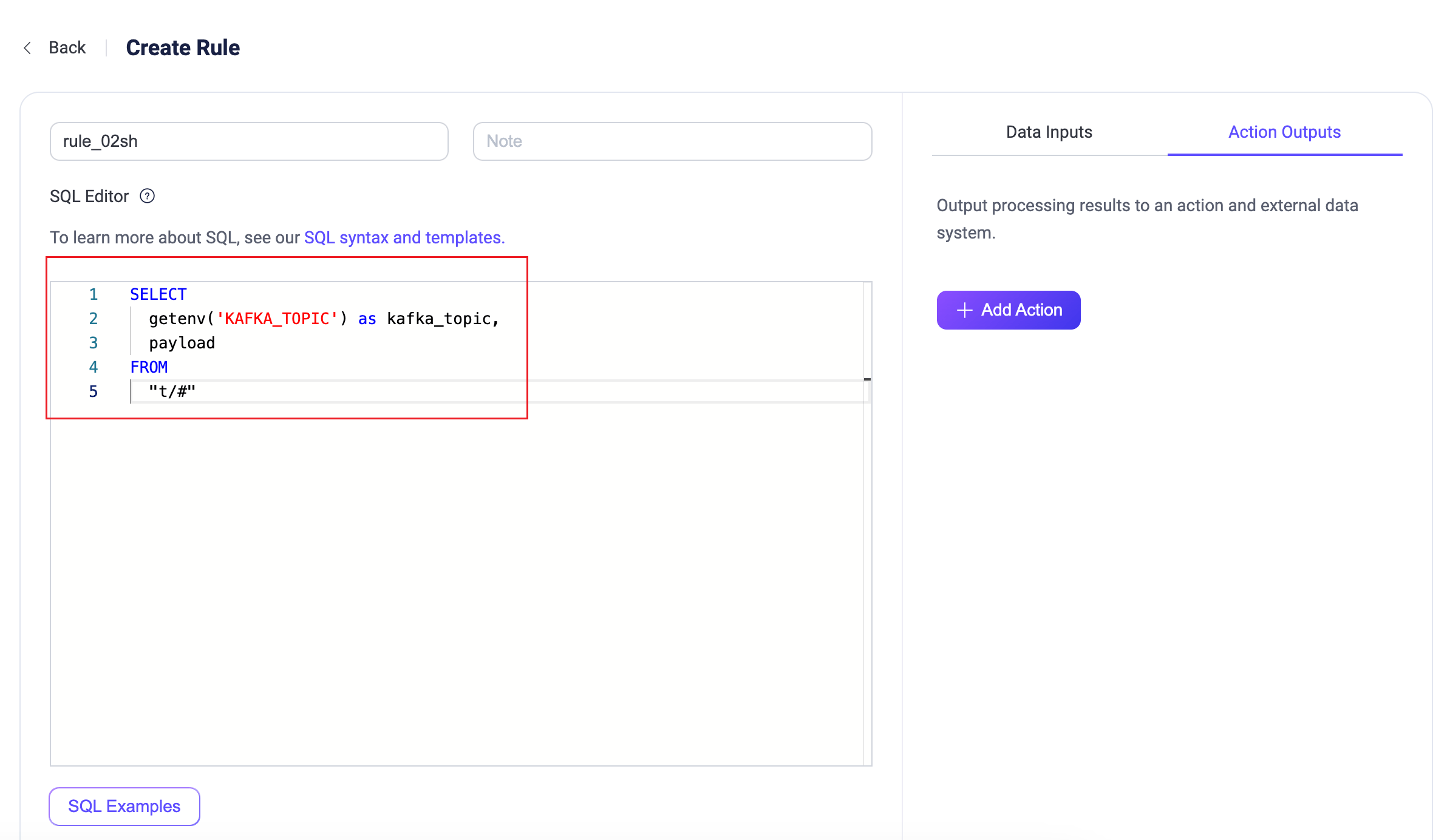
SQLテストを有効にし、環境変数値
testtopic-inが正常に取得されていることを確認します。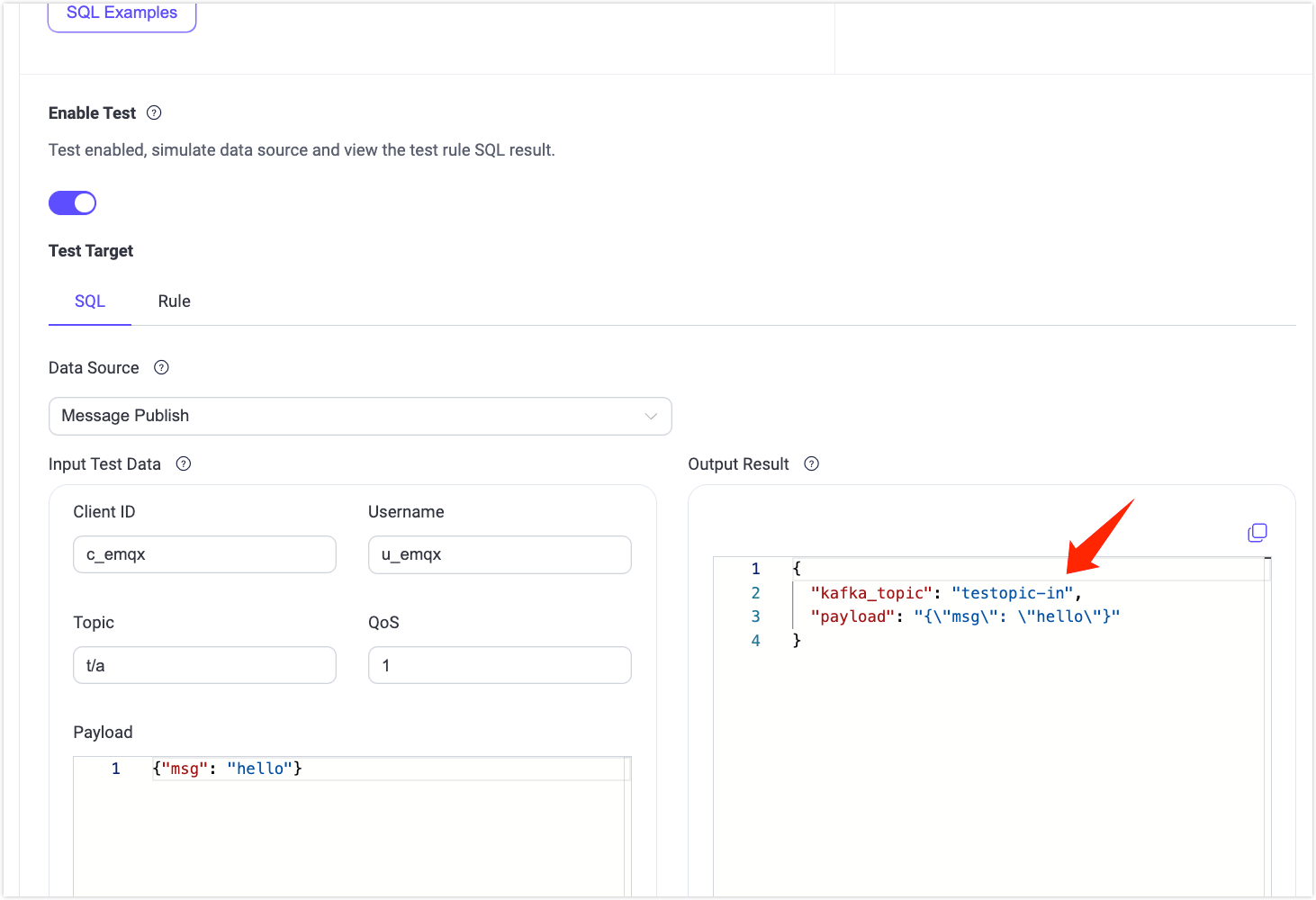
Kafka Producer Sinkにアクションを追加します。ルール右側のAction OutputsでAdd Actionをクリック。
- Connector:先に作成した
test-kafkaを選択。 - Kafka Topic:SQLルール出力に基づき変数テンプレート形式
${kafka_topic}で設定。
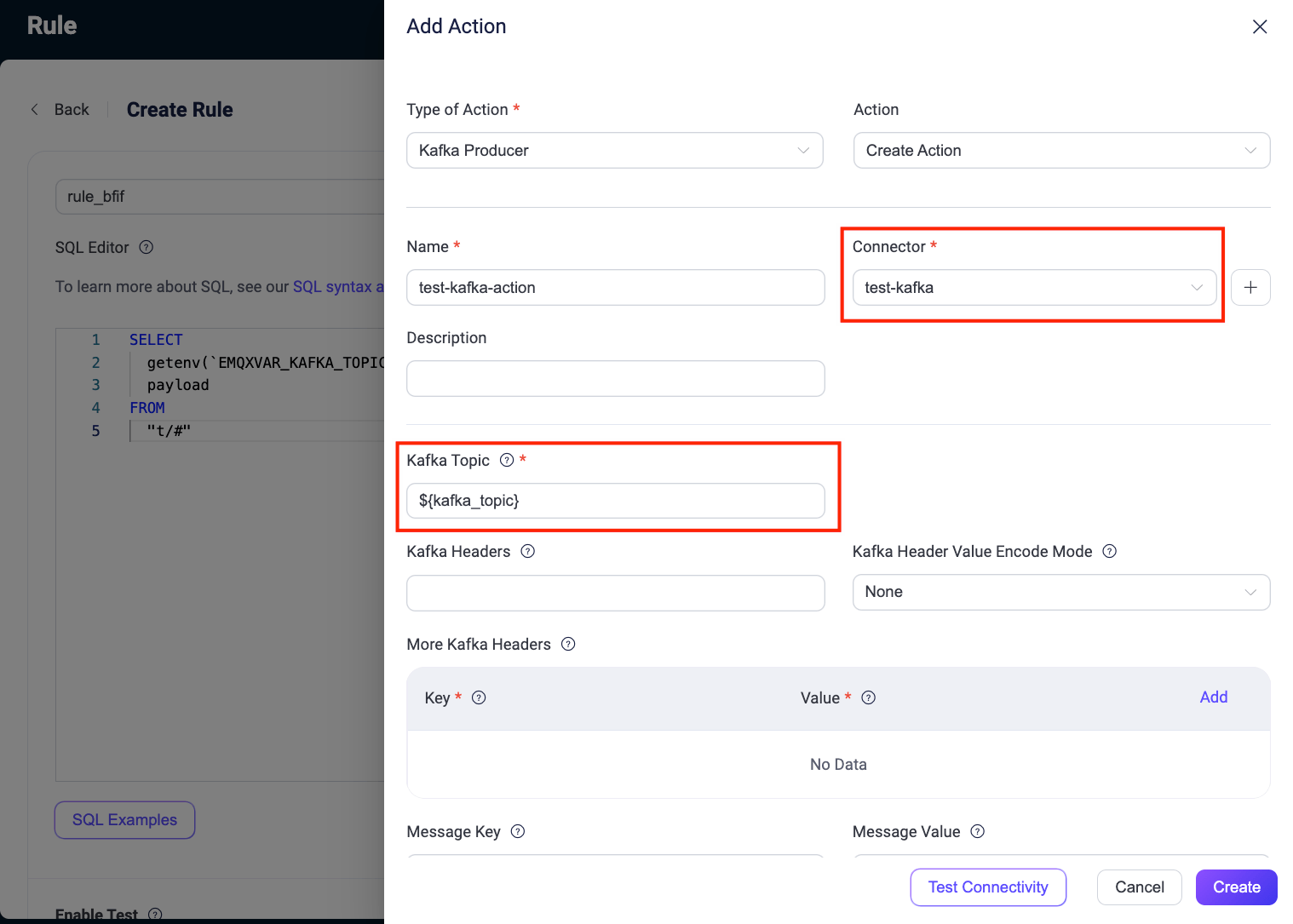
- Connector:先に作成した
Kafka Sinkルールの作成を参照して追加設定を行い、最後にCreateをクリックしてルール作成を完了します。
Kafkaプロデューサールールのテストの手順に従い、Kafkaにメッセージを送信します:
bashmqttx pub -h 127.0.0.1 -p 1883 -i pub -t t/Connection -q 1 -m 'payload string'メッセージはKafkaトピック
testtopic-inで受信されるはずです:bashbin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 \ --topic testtopic-in {"payload":"payload string","kafka_topic":"testtopic-in"} {"payload":"payload string","kafka_topic":"testtopic-in"}
変数テンプレートの使用
Kafka Topicフィールドに静的なトピック名を設定する以外に、変数テンプレートを用いて動的にトピックを生成可能です。これによりメッセージ内容に基づいてKafkaトピックを構築でき、柔軟なメッセージ処理・分配が可能になります。例えば、device-${payload.device}のように指定すると、特定デバイスからのメッセージをデバイスIDを付加したトピック(例:device-1)に送信できます。
この例では、Kafkaに送信するメッセージペイロードにdeviceキーが含まれている必要があります。例:
{
"topic": "t/devices/data",
"payload": {
"device": "1",
"temperature": 25.6,
"humidity": 60.2
}
}このキーがないとトピックのレンダリングに失敗し、メッセージが回復不能な形で破棄されます。
また、Kafkaにはdevice-1、device-2などの解決済みトピックを事前作成しておく必要があります。テンプレートが存在しないトピック名に解決された場合も、メッセージは破棄されます。
Kafka プロデューサールールのテスト
Kafkaプロデューサールールが期待通り動作するかをテストするため、MQTTXを使ってEMQXにMQTTメッセージをパブリッシュするクライアントをシミュレートできます。
- MQTTXでトピック
t/1にメッセージを送信:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "Hello Kafka" }'**Actions(Sink)**ページでSink名をクリックし統計情報を確認します。Sinkの稼働状況に新規の受信メッセージ数と送信メッセージ数が1件ずつ増えているはずです。
以下のコマンドでメッセージが
testtopic-inトピックに書き込まれているか確認します:bashbin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic testtopic-in
Kafka コンシューマーコネクターの作成
Kafka Sourceアクションを追加する前に、EMQXとKafka間の接続を確立するためKafkaコンシューマーコネクターを作成する必要があります。
EMQX Dashboardで Integration -> Connector を開きます。
ページ右上の Create をクリックします。
Create Connectorページで Kafka Consumer を選択し、Nextをクリックします。
ソースの名前を入力します。大文字・小文字の英数字の組み合わせで、例:
my-kafka-source。EMQX Dashboardで Integration -> Connector を開きます。
ページ右上の Create をクリックします。
Create Connectorページで Kafka Consumer を選択し、Nextをクリックします。
ソースの名前を入力します。英数字の組み合わせで、例:
my-kafka-source。ソースの接続情報を入力します。
Bootstrap Hosts:
127.0.0.1:9092と入力します。ローカル起動前提のため、リモート環境の場合は適宜調整してください。Authentication:Kafkaクラスターで必要な認証方式を選択します。以下の方式をサポートしています:
None:認証なしauthentication_msk_iam:EMQXがEC2インスタンス上にデプロイされている場合のAWS MSKクラスタ用Basic Auth:Mechanism(plain、scram_sha_256、scram_sha_512のいずれか)とUsername、Passwordを指定Kerberos:Kerberos PrincipalとKerberos Keytab Fileを指定
詳細は認証方式を参照してください。
暗号化接続を確立する場合は、Enable TLSのトグルをオンにします。TLS接続の詳細はTLS for External Resource Accessを参照してください。
Advanced Settings(任意):高度な設定を参照してください。
Createをクリックする前に、Test ConnectionをクリックしてKafkaサーバーへの接続が成功するかテストできます。
Createをクリックします。関連するルール作成のオプションが表示されます。KafkaコンシューマーSourceを使ったルール作成を参照してください。
KafkaコンシューマーSourceを使ったルール作成
このセクションでは、設定済みのKafkaコンシューマーSourceから転送されたメッセージをさらに処理し、MQTTトピックに再パブリッシュするルールの作成方法を示します。
このセクションでは、設定済みの Kafka コンシューマーソースから転送されたメッセージをさらに処理し、MQTT トピックに再パブリッシュするルールの作成方法を説明します。
EMQX Dashboardで Integration -> Rules を開きます。
ページ右上の Create をクリックします。
ルールIDを入力します。例:
my_ruleKafkaソース
$bridges/kafka_consumer:<sourceName>から変換されたメッセージをEMQXに転送する場合、SQL Editorに以下の文を入力します。注意:独自のSQL文を指定する場合は、後続の再パブリッシュアクションで必要なすべてのフィールドを
SELECT句に含めてください。Kafka SourceのSELECT文ではts_type、topic、ts、event、headers、key、metadata、value、timestamp、offset、nodeなどのフィールドが使用可能です。sqlSELECT * FROM "$bridges/kafka_consumer:<sourceName>"注意:初心者の方は、SQL Examplesをクリックし、Enable Testを使ってSQLルールを学習・テストできます。
KafkaコンシューマーSourceをデータ入力に追加
ルール作成画面右側のData Inputsタブを選択し、Add Inputをクリックします。
Input TypeドロップダウンからKafka Consumerを選択します。Sourceはデフォルトの
Create Sourceのままか、既存のKafka Consumerソースを選択します。本例では新規作成します。Sourceの名前と説明を入力します。
Connectorドロップダウンから先ほど作成した
my-kafka-consumerコネクターを選択します。隣のボタンをクリックするとポップアップで新規コネクターを素早く作成可能です。設定パラメータはKafkaコンシューマーコネクターの作成を参照してください。以下のフィールドを設定します:
- Kafka Topic:コンシューマーSourceがメッセージを受信するKafkaトピックを指定します。
- Group ID:このSourceのコンシューマーグループ識別子を指定します。未指定の場合、ソース名に基づき自動生成されます。
- Key Encoding ModeおよびValue Encoding Mode:Kafkaメッセージのキーと値のエンコードモードを選択します。
Offset Reset Policy:KafkaコンシューマーがKafkaトピックパーティションのどのオフセットから読み始めるかを指定します。コンシューマーのオフセットが存在しないか無効な場合に適用されます。
latestを選択すると、コンシューマーは最新のオフセットから読み始め、開始前に生成されたメッセージはスキップされます。earliestを選択すると、コンシューマーはパーティションの先頭から読み始め、開始前に生成されたメッセージも含めてすべての履歴データを読み取ります。
Advanced Settings(任意):高度な設定を参照してください。
Createをクリックする前に、Test ConnectivityをクリックしてKafkaサーバーへの接続をテスト可能です。
CreateをクリックしてSourceの作成を完了します。Create Rule画面に戻ると、Data Inputsタブに新規Sourceが表示されます。
再パブリッシュアクションの追加
Action Outputsタブを選択し、+ Add Actionボタンをクリックしてルールでトリガーされるアクションを定義します。
Type of ActionドロップダウンからRepublishを選択します。
TopicおよびPayloadフィールドに再パブリッシュしたいメッセージのトピックとペイロードを入力します。例として、
t/1と${.}を入力します。- Topicフィールドには
${}を使って動的にMQTTトピックを指定可能です。例:t/${key}(${}内のパラメータはSQLのSELECT文に含める必要があります)。
- Topicフィールドには
Addをクリックしてアクションをルールに追加します。
Create Rule画面に戻り、Saveをクリックします。
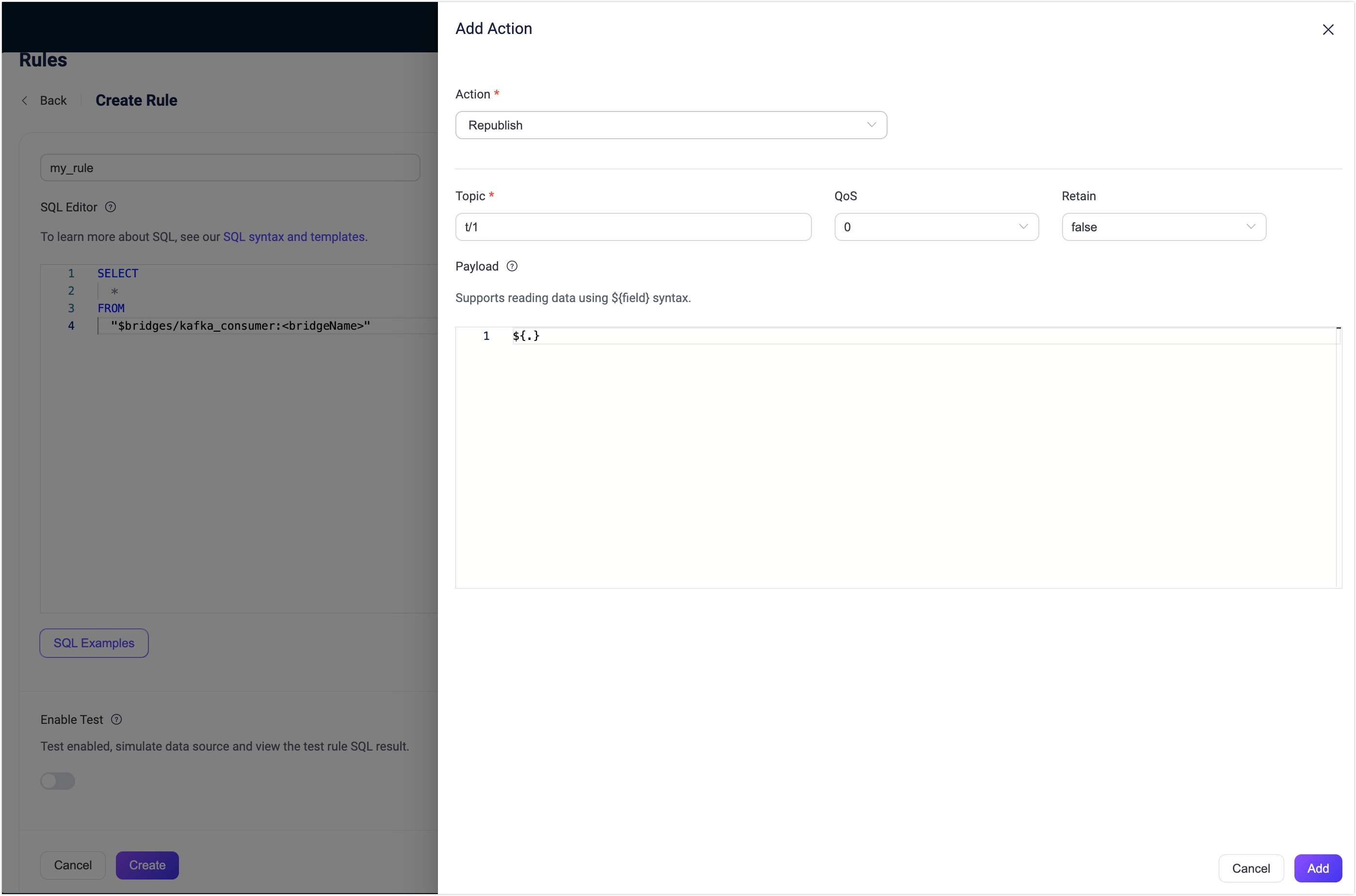
Kafka ソースルールのテスト
Kafka Sourceとルールが期待通り動作するかテストするため、MQTTXを使ってEMQXのトピックをサブスクライブするクライアントをシミュレートし、KafkaプロデューサーでKafkaトピックにデータを生成します。その後、KafkaからのデータがEMQXによってクライアントがサブスクライブするトピックに再パブリッシュされるか確認します。
MQTTXでトピック
t/1をサブスクライブ:bashmqttx sub -t t/1 -v新しいコマンドラインウィンドウを開き、以下のコマンドでKafkaプロデューサーを起動:
bashbin/kafka-console-producer --bootstrap-server 127.0.0.1:9092 --topic testtopic-outメッセージ入力待ち状態になります。
{"msg": "Hello EMQX"}を入力し、testtopic-outトピックにメッセージを生成してEnterを押します。MQTTXのサブスクリプションを確認すると、Kafkaからの以下のメッセージがトピック
t/1で受信されるはずです:json{ "value": "{\"msg\": \"Hello EMQX\"}", "ts_type": "create", "ts": 1679665968238, "topic": "testtopic-out", "offset": 2, "key": "key", "headers": { "header_key": "header_value" } }
高度な設定
このセクションでは、データ統合のパフォーマンス最適化や特定シナリオに応じたカスタマイズのための高度な設定オプションを説明します。コネクター、Sink、Source作成時にAdvanced Settingsを展開し、ビジネス要件に応じて以下の設定を行えます。
| 項目 | 説明 | 推奨値 |
|---|---|---|
| Allow Auto Topic Creation | (プロデューサーコネクターのみ)有効にすると、クライアントがメタデータ取得要求を送信した際にKafkaトピックが存在しなければ自動作成を許可します。 | disabled |
| Min Metadata Refresh Interval | クライアントがKafkaブローカーやトピックのメタデータを更新する最小間隔。短すぎるとKafkaサーバーの負荷が増加します。 | 3秒 |
| Metadata Request Timeout | Kafkaからメタデータを要求する際の最大待機時間。 | 5秒 |
| Connect Timeout | TCP接続確立の最大待機時間。認証時間も含みます。 | 5秒 |
| Max Wait Time (Source) | Kafkaブローカーからのフェッチ応答を待つ最大時間。 | 1秒 |
| Fetch Bytes (Source) | フェッチ要求ごとにKafkaから取得するバイト数。設定値がKafka内のメッセージサイズより小さいとフェッチ性能に悪影響を与える可能性があります。 | 896 KB |
| Max Batch Bytes (Sink) | Kafkaバッチ内でメッセージを収集する最大バイト数。Kafkaブローカーのデフォルトは1MBですが、EMQXはKafkaメッセージのエンコードオーバーヘッドを考慮し若干小さめに設定しています。単一メッセージがこの制限を超える場合は別バッチで送信されます。 | 896 KB |
| Offset Commit Interval (Source) | 各コンシューマーグループのオフセットコミット要求送信間隔。 | 5秒 |
| Required Acks (Sink) | Kafkaパーティションリーダーがフォロワーから待つ必要のあるアック数:all_isr:全てのインシンクレプリカからのアックを要求。leader_only:リーダーからのみアックを要求。none:Kafkaからのアック不要。 | all_isr |
| Partition Count Refresh Interval (Source) | Kafkaプロデューサーがパーティション数増加を検知する間隔。増加検知後、partition_strategyに基づき新パーティションをメッセージ送信に組み込みます。 | 60秒 |
| Max Inflight (Sink) | Kafkaプロデューサーがアック受信前に送信可能な最大バッチ数(パーティション毎)。値が大きいほどスループットは向上しますが、1より大きい場合はメッセージ順序の入れ替わりリスクがあります。 未アックメッセージ数を制御し、負荷バランスを取ります。 | 10 |
| Query Mode (Source) | 非同期または同期クエリモードを選択し、要件に応じてメッセージ送信を最適化。非同期モードではKafka書き込みがMQTTパブリッシュをブロックしませんが、クライアントがKafka到達前にメッセージを受信する可能性があります。 | Async |
| Synchronous Query Timeout (Sink) | 同期クエリモード時の確認待機最大時間。メッセージ送信完了をタイムリーに保証し、長時間待機を回避します。Syncモード時のみ有効。 | 5秒 |
| Buffer Mode (Sink) | メッセージ送信前のバッファリング方式。メモリバッファリングは送信速度を向上させます。memory:メモリにバッファ。EMQXノード再起動でメッセージ消失。disk:ディスクにバッファ。再起動後もメッセージ保持。hybrid:初めはメモリバッファで、一定量超過時にディスクにオフロード。メモリモード同様、再起動で消失。 | memory |
| Per-partition Buffer Limit (Sink) | Kafkaパーティション毎の最大バッファサイズ(バイト)。上限到達時は古いメッセージを破棄しバッファ空間を確保。 メモリ使用量と性能のバランス調整に有効。 | 2 GB |
| Segment File Bytes (Sink) | バッファモードがdiskまたはhybrid時に適用。メッセージ保存用の分割ファイルサイズを制御し、ディスクストレージの最適化に影響。 | 100 MB |
| Memory Overload Protection (Sink) | バッファモードがmemory時に適用。高メモリ圧迫時に古いバッファメッセージを自動破棄し、システムの安定性を確保。Linuxシステムのみ有効。 | Enabled |
| Socket Send / Receive Buffer Size | ソケットバッファサイズを管理し、ネットワーク送信性能を最適化。 | 1024 KB |
| TCP Keepalive | Kafkaブリッジ接続のTCPキープアライブを有効化し、長時間の非アクティブによる接続切断を防止。値はIdle, Interval, Probesの3つの数値をカンマ区切りで指定:Idle:サーバーがキープアライブプローブを開始するまでのアイドル秒数(Linuxデフォルト7200秒)。 Interval:各キープアライブプローブ間の秒数(Linuxデフォルト75秒)。 Probes:応答なしと判断するまでの最大プローブ数(Linuxデフォルト9回)。 例: 240,30,5は240秒アイドル後にプローブ開始、30秒間隔で最大5回送信し応答なしなら接続切断。 | none |
| Max Linger Time | パーティション毎のプロデューサーがバッチ収集のためにメッセージを待つ最大時間。デフォルト0は待機なし。メモリバッファ以外では5msに設定するとIOPSを大幅削減可能だがレイテンシ増加のトレードオフあり。 | 0 ミリ秒 |
| Max Linger Bytes | パーティション毎のプロデューサーがバッチ収集のためにメッセージを待つ最大バイト数。 | 10 MB |
| Health Check Interval | コネクターの稼働状況チェック間隔。 | 15秒 |
参考情報
EMQX は Apache Kafka とのデータ統合に関する豊富な学習リソースを提供しています。以下のリンクから詳細を学べます。
ブログ:
- MQTTとKafkaでつくるコネクテッドビークルのストリーミングデータパイプライン:3分ガイド
- MQTTとKafka:IoTデータ統合の強化
- MQTTパフォーマンスベンチマークテスト:EMQX-Kafka統合
ベンチマークレポート:
動画:
- EMQX Cloudルールエンジンを使ったデバイスデータのKafkaブリッジ(Cloudルールエンジンに関する動画で、将来的により適切な動画に差し替え予定)