クラスターアーキテクチャ
EMQX 5.0 から、新しい Mria クラスターアーキテクチャと再設計されたデータレプリケーション機構が導入されました。これにより、EMQX の水平スケーラビリティが大幅に向上し、単一の EMQX 5.0 クラスターで最大1億の MQTT 接続をサポート可能となった主要な要因の一つです。
本ページでは、新アーキテクチャにおける EMQX クラスターのデプロイメントモデルと、デプロイ時の重要な考慮点を紹介します。自動化されたクラスターのデプロイについては、EMQX Kubernetes Operator および EMQX Core ノードと Replicant ノードの設定 のガイドを参照してください。
前提知識
まずは EMQX クラスタリング をご一読いただくことを推奨します。
Mria アーキテクチャ概要
Mria は Erlang のネイティブデータベースである Mnesia のオープンソース拡張で、データレプリケーションにおける最終的整合性を実現します。非同期トランザクションログレプリケーションを有効にすると、ノード間の接続トポロジーは Mnesia のフルメッシュモデルから Mria のメッシュ+スターのハイブリッドトポロジーに変わります。
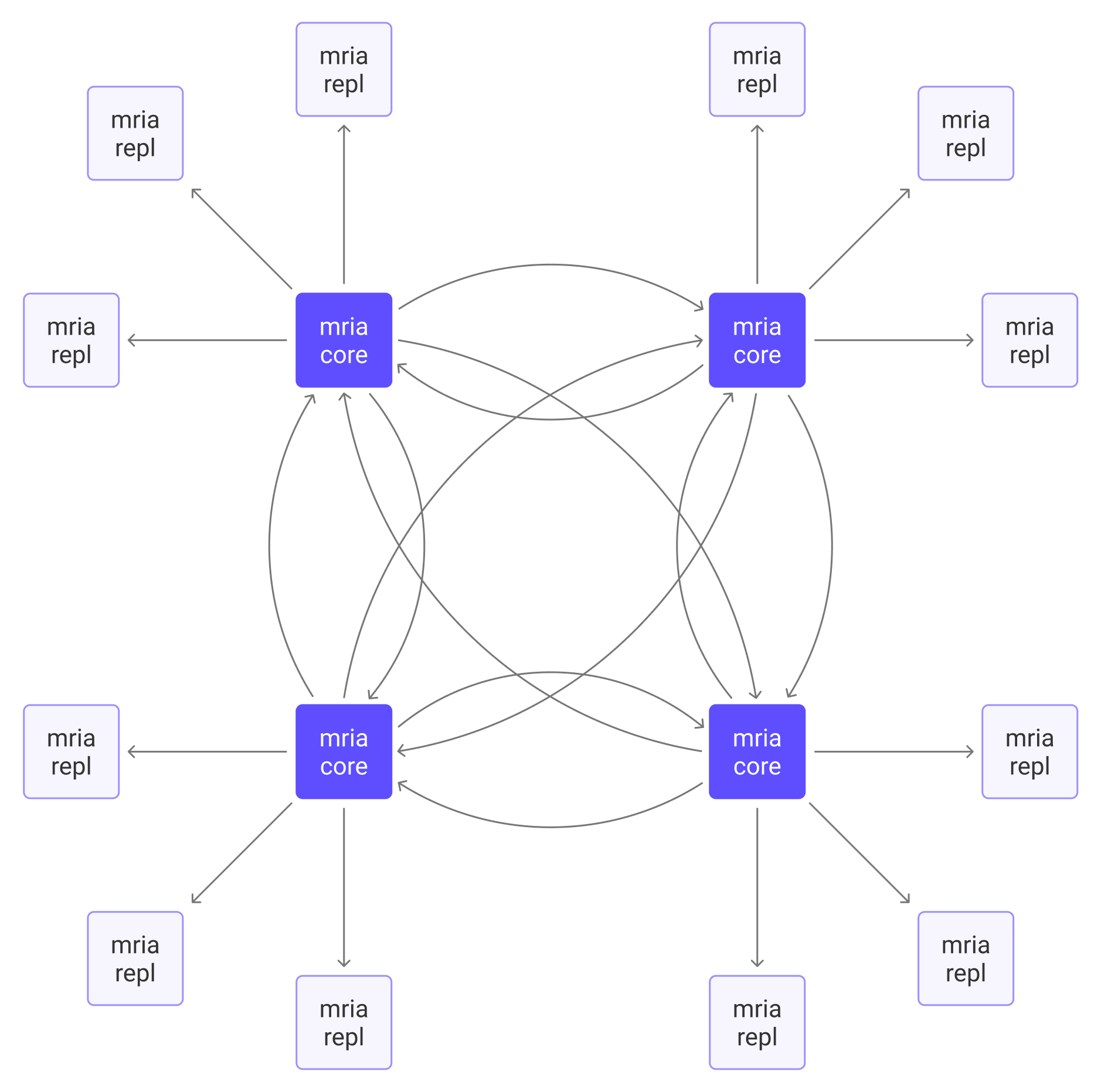
ノードの役割説明
クラスター内のノードは、コアノードとレプリカントノードの2つの役割に分類されます。
コアノード
コアノードはクラスターの完全なメッシュデータレイヤーを形成します。各コアノードはデータの完全かつ最新のレプリカを保持し、フォールトトレランスを確保します。つまり、コアノードが1つでも稼働していればデータは失われません。コアノードは一般的に静的かつ永続的であり、頻繁に追加・削除・置換されるオートスケーリングには適していません。
レプリカントノード
レプリカントノードはコアノードに接続し、そこからのデータ更新を受動的にレプリケートします。書き込み操作は許可されておらず、書き込みはすべてコアノードに転送されて処理されます。データの完全なローカルコピーを持つため、レプリカントは高速な読み取りアクセスと低いルーティングレイテンシを提供します。
Mria アーキテクチャの利点
Mria アーキテクチャはリーダーレスレプリケーションとマスター・スレーブレプリケーションの長所を組み合わせ、以下のようなメリットを提供します。
- 水平スケーラビリティの向上:EMQX 5.0 は最大23ノードの大規模クラスターをサポート。
- クラスターのオートスケーリングが簡素化:レプリカントノードは動的に追加・削除可能で、自動スケーリングに対応。
EMQX 4.x では全ノードがフルメッシュトポロジーを使用していたため、ノード数増加に伴い同期オーバーヘッドが増大していましたが、EMQX 5.0 ではレプリカントノードを読み取り専用にすることでこの問題を回避しています。レプリカントが増えても書き込み効率は低下せず、より大規模なクラスター構築が可能です。
さらに、レプリカントノードは使い捨て可能でスケールイン・スケールアウトが容易な設計となっており、データ冗長性に影響を与えずに自動スケーリンググループに最適化されています。これにより DevOps の運用効率も向上します。
注意:データセットが大きくなると、コアノードから新しいレプリカントへの初期データ同期に多くのリソースを消費します。レプリカントノードのオートスケーリングポリシーは過度に積極的にしないよう注意してください。
デプロイメントアーキテクチャ
デフォルトではすべてのノードがコアノードの役割を担い、クラスターは EMQX 4.x と同様の動作をします。このモードは7ノード以下の小規模クラスターに推奨されます。コア+レプリカントモードはクラスターが7ノードを超える場合にのみ推奨されます。
注意
コア+レプリカントのクラスターアーキテクチャは EMQX Enterprise でのみ利用可能です。オープンソース版はコアノードのみのクラスターをサポートします。
推奨
クラスターには最低1つのコアノードが必要です。ベストプラクティスとしては、3つのコアノードと N 個のレプリカントノードで開始することを推奨します。
ノードの役割割り当ては、実際のビジネス要件と想定されるクラスター規模に基づいて行ってください。
| シナリオ | 推奨デプロイメント |
|---|---|
| 小規模クラスター(7ノード以下) | コアノードのみのモードで十分。すべてのノードが MQTT トラフィックを処理。 |
| 中規模クラスター | コアノードが MQTT トラフィックを処理するかはワークロード次第。テストで最適解を探す。 |
| 大規模クラスター(10ノード以上) | コアノードはデータベースレイヤーのみを担当。レプリカントノードがすべての MQTT トラフィックを処理し、安定性とスケーラビリティを最大化。 |
コア+レプリカントモードの有効化
コア+レプリカントモードを有効にするには、特定のノードをレプリカントノードとして指定する必要があります。これは node.role パラメータを replicant に設定することで実現します。加えて、自動クラスター ディスカバリーストラテジー(cluster.discovery_strategy)を有効にする必要があります。
TIP
レプリカントノードは manual ディスカバリーストラテジーを使用してコアノードを検出できません。
設定例:
node {
## ノードをレプリカントノードとして設定する場合:
role = replicant
}
cluster {
## 静的ディスカバリーストラテジーを有効化:
discovery_strategy = static
static.seeds = [emqx@host1.local, emqx@host2.local]
}ネットワークおよびハードウェア要件
ネットワーク
- コアノード間のネットワークレイテンシは10ms未満が望ましい。100msを超えるとクラスター障害の原因となる可能性があります。
- コアノードは同一のプライベートネットワーク内にデプロイすることを強く推奨します。
- レプリカントノードもコアノードと同じプライベートネットワーク内に配置すべきですが、ネットワーク品質の要件はやや緩和されます。
CPU とメモリ
コアノードはメモリを多く必要としますが、クライアント接続を処理していない場合は CPU 消費は比較的低いです。レプリカントノードは EMQX 4.x と同様のハードウェアサイズを推奨し、メモリ要件は想定される接続数とメッセージスループットに基づいて見積もってください。
監視とデバッグ
Mria のパフォーマンスは Prometheus メトリクスや Erlang コンソールで監視可能です。
Prometheus 指標
Prometheus と連携してクラスターの動作を監視できます。連携方法は ログと可観測性 - Prometheus 連携 を参照してください。
コアノード
| 指標名 | 説明 |
|---|---|
emqx_mria_last_intercepted_trans | ノード起動以降にシャードが受け取ったトランザクション数 |
emqx_mria_weight | コアノードの瞬間的な負荷 |
emqx_mria_replicants | コアノードに接続しているレプリカントノード数(シャードごとに集計) |
emqx_mria_server_mql | レプリカントノードに送信待ちのトランザクション数。少ないほど良い。 この値が増加傾向にある場合は、コアノードを増やす必要があります。 |
レプリカントノード
| 指標名 | 説明 |
|---|---|
emqx_mria_lag | レプリカントが上流のコアノードにどれだけ遅れているかを示す。少ないほど良い。 |
emqx_mria_bootstrap_time | レプリカントノードの起動時間。正常稼働時は安定しているべき値。 |
emqx_mria_bootstrap_num_keys | 起動時にコアノードからコピーされたデータベースレコード数。正常稼働時は安定しているべき値。 |
emqx_mria_message_queue_len | メッセージレプリケーション時のキュー長。0付近が望ましい。 |
emqx_mria_replayq_len | レプリカントノード内部のリプレイキュー長。少ないほど良い。 |
コンソールコマンド
Erlang コンソールで emqx eval 'mria_rlog:status().' コマンドを実行することで、クラスターの稼働状況を監視できます。
EMQX クラスターが正常に動作している場合、現在のログレベル、処理済みメッセージ数、破棄されたメッセージ数などのステータス情報が一覧で取得可能です。
関連情報は Mria ログとアラーム もご参照ください。