Cluster Architecture
Starting from EMQX 5.0, a new Mria cluster architecture was introduced, along with a redesigned data replication mechanism. This significantly enhanced EMQX's horizontal scalability and is one of the key factors enabling a single EMQX 5.0 cluster to support up to 100 million MQTT connections.
This page introduces the EMQX cluster deployment model under the new architecture, as well as key considerations during deployment. For automated cluster deployment, refer to the EMQX Kubernetes Operator and the guide on Configuring EMQX Core and Replicant Nodes.
Prerequisite Knowledge
It is recommended to first read EMQX Clustering.
Mria Architecture Overview
Mria is an open-source extension of Erlang’s native database, Mnesia, that enables eventual consistency in data replication. With asynchronous transaction log replication enabled, the node connection topology shifts from Mnesia’s fully meshed model to Mria’s mesh + star hybrid topology.
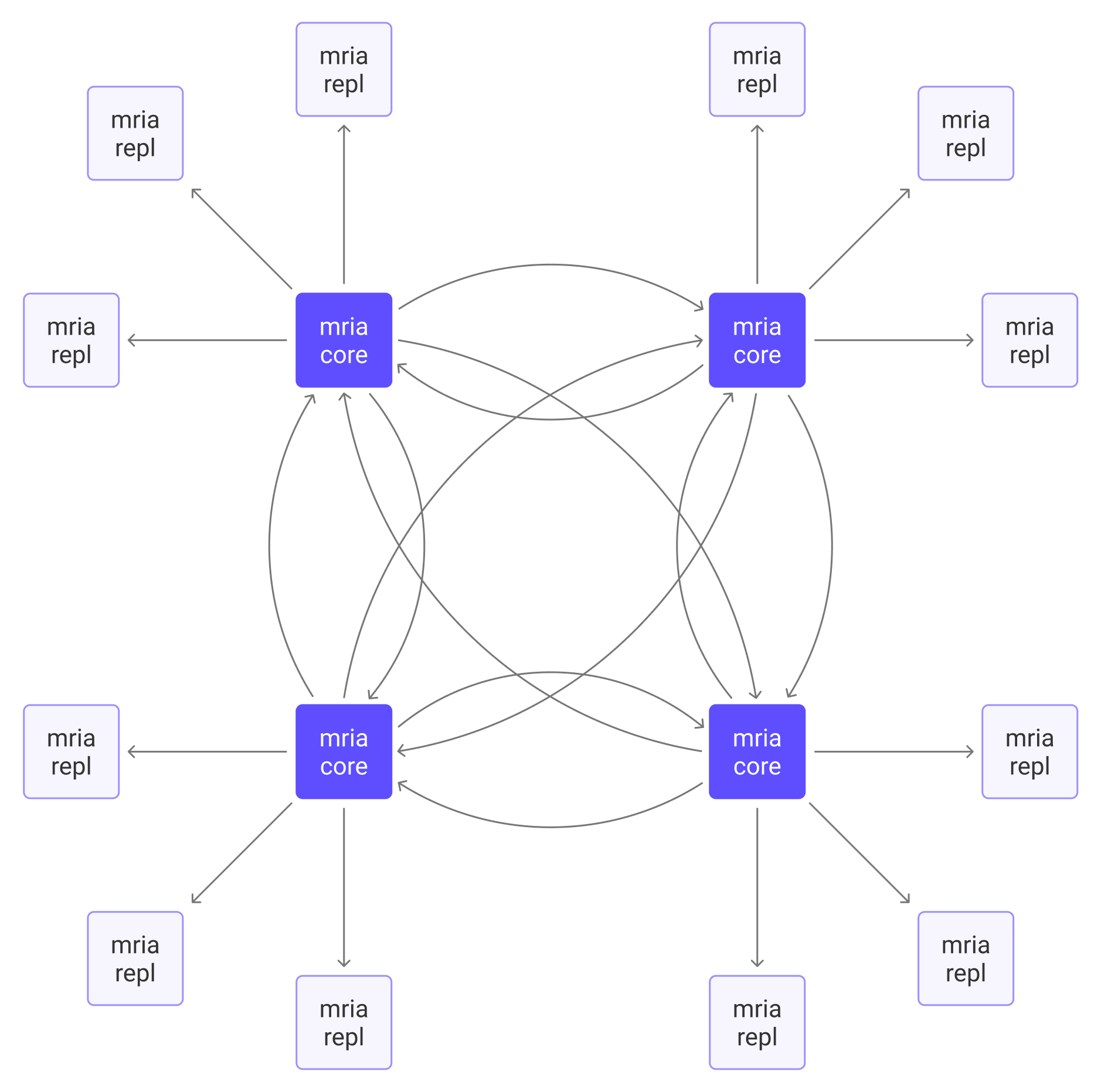
Node Role Description
Nodes in the cluster are categorized into two roles: Core nodes and Replicant nodes.
Core Nodes
Core nodes form the fully meshed data layer of the cluster. Each core node holds a complete and up-to-date replica of the data, ensuring fault tolerance: as long as one core node remains available, data is not lost. Core nodes are generally static and persistent, and are not recommended to be auto-scaling (i.e., frequently added, removed, or replaced).
Replicant Nodes
Replicant nodes connect to core nodes and passively replicate data updates from them. They are not allowed to perform write operations; instead, any writes are forwarded to the core nodes for processing. With a full local copy of data, replicants offer fast read access and lower routing latency.
Advantages of the Mria Architecture
The Mria architecture combines the strengths of leaderless replication and master-slave replication, offering several key benefits:
- Improved horizontal scalability: EMQX 5.0 supports large-scale clusters with up to 23 nodes.
- Simplified cluster auto-scaling: Replicant nodes can be added or removed dynamically to support automated scaling.
In contrast to EMQX 4.x, where all nodes used a fully connected topology (increasing sync overhead as node count grew), EMQX 5.0 avoids this issue by keeping replicant nodes read-only. As more replicants join the cluster, write efficiency is not affected, enabling the formation of much larger clusters.
Moreover, replicant nodes are designed to be disposable and easily scaled in or out without affecting data redundancy. This makes them ideal for auto-scaling groups and improves DevOps practices.
Note: As the dataset grows, the initial data sync from core nodes to a new replicant can become resource-intensive. Avoid overly aggressive auto-scaling policies for replicant nodes to prevent performance issues.
Deployment Architecture
By default, all nodes assume the Core node role, so the cluster behaves like that in EMQX 4.x, which is recommended for a small cluster with 7 nodes or fewer. The Core + Replicant mode is only recommended if there are more than 7 nodes in the cluster.
Note
The Core + Replicant cluster architecture is available only in EMQX Enterprise. The open-source edition supports Core-only clusters.
Recommendation
A cluster must include at least one Core node. As a best practice, we recommend starting with 3 Core nodes + N Replicant nodes.
Node role assignment should be based on actual business requirements and the expected cluster size:
| Scenario | Recommended Deployment |
|---|---|
| Small cluster (≤ 7 nodes) | Core-only mode is sufficient; all nodes handle MQTT traffic. |
| Medium-sized cluster | Whether Core nodes handle MQTT traffic depends on workload; test for best results. |
| Large cluster (≥ 10 nodes) | Core nodes act only as the database layer. Replicant nodes handle all MQTT traffic to maximize stability and scalability. |
Enable Core + Replicant Mode
To enable the Core + Replicant mode, it is necessary to designate certain nodes as replicant nodes. This is achieved by setting node.role parameter to replicant. Additionally, you need to enable an automatic cluster discovery strategy (cluster.discovery_strategy).
TIP
Replicant nodes cannot use manual discovery strategy to discover core nodes.
Configuration example:
node {
## To set a node as a replicant node:
role = replicant
}
cluster {
## Enable static discovery strategy:
discovery_strategy = static
static.seeds = [emqx@host1.local, emqx@host2.local]
}Network and Hardware Requirements
Network
- Network latency between Core nodes should be less than 10 ms. Latency exceeding 100 ms may cause cluster failures.
- It is strongly recommended to deploy Core nodes within the same private network.
- Replicant nodes should also be deployed in the same private network as Core nodes, although the network quality requirements are slightly more relaxed.
CPU and Memory
Core nodes require more memory, but consume relatively low CPU when not handling client connections. Replicant nodes follow the same hardware sizing as in EMQX 4.x, and their memory requirements should be estimated based on the expected number of connections and message throughput.
Monitor and Debug
The Mria performance can be monitored using Prometheus metrics or Erlang console.
Prometheus Indicators
You can integrate with Prometheus to monitor the cluster operations. On how to integrate with Prometheus, see Log and observability - Integrate with Prometheus.
Core Nodes
| Indicators | Description |
|---|---|
emqx_mria_last_intercepted_trans | Transactions received by the shard since the node started |
emqx_mria_weight | Instantaneous load of the Core node |
emqx_mria_replicants | Replicant nodes connected to the Core node Numbers are grouped per shard. |
emqx_mria_server_mql | Pending transactions waiting to be sent to the replicant nodes. Less is optimal. If this indicator shows a growing trend, more Core nodes are needed. |
Replicant Nodes
| Indicators | Description |
|---|---|
emqx_mria_lag | Indicate how far the Replicant lags behind the upstream Core node. Less is better. |
emqx_mria_bootstrap_time | Startup time of the Replica node. This value should remain stable if the system operates normally. |
emqx_mria_bootstrap_num_keys | Number of database records copied from the Core node during startup. This value should remain stable if the system operates normally. |
emqx_mria_message_queue_len | Queue length during message replication. Should be around 0. |
emqx_mria_replayq_len | Internal replay queue length on the Replicant nodes. Less is better. |
Console Commands
You can also monitor the operating status of the cluster with the command emqx eval 'mria_rlog:status().' on the Erlang console.
If the EMQX cluster is operating normally, you can get a list of status information, for example, the current log level, the number of messages processed, and the number of messages dropped.
See also: Mria Logs and Alarms