Design for EMQX Clustering
MQTT is a stateful protocol, which necessitates that the broker maintains state information for each MQTT session, including subscribed topics and incomplete message transmissions. One of the primary challenges in clustering MQTT brokers is ensuring efficient and reliable synchronization and replication of these states across all clustered nodes.
EMQX is a highly scalable and fault-tolerant MQTT broker capable of operating in a clustered mode with multiple nodes. Clustering EMQX enhances the scalability, availability, reliability, and manageability of IoT messaging systems, making it a recommended approach for larger or mission-critical applications. This page explores the necessity of clustering MQTT brokers and how EMQX achieves this, enabling support for millions of unique wildcard subscribers within a single cluster.
For detailed instructions on creating and running an EMQX cluster, refer to EMQX Cluster.
Key Aspects of Clustering
When designing a cluster, there are several key aspects that need to be considered. Often these are the most important factors that determine the success of the cluster. A quick summary is as follows:
Centralized Management: The cluster should be able to be managed centrally, as all nodes in the cluster can be monitored and controlled from a single management console.
Data Consistency: The cluster ensures that all nodes in the cluster have a consistent view of the routing information. This is achieved by replicating data across all nodes in the cluster.
Easy To Scale: To reduce the complexity of cluster management, it should not be a complex task to add more nodes to the cluster. The cluster should be able to automatically detect the new nodes and add them to the cluster.
Cluster Rebalance: With minimal operational overhead, the cluster should be able to reflect on and detect the unbalanced load of each node and reassign the workloads to the nodes with the least load. This ensures that the cluster can continue to function even if one or more nodes fail.
Large Cluster Size: To meet the increasing demands of the system, the cluster can be expanded by adding more nodes to the cluster. This allows the cluster to scale horizontally to meet the increasing demands of the system.
Automatic Failover: If a node fails, the cluster will automatically detect the failure and reassign the workloads to the remaining nodes. This ensures that the cluster can continue to function even if one or more nodes fail.
Network Partition Tolerance: The cluster should be able to tolerate network partitions, as the cluster can continue to function even if one or more nodes fail.
EMQX utilizes a variety of approaches to ensure that these goals are met in the most efficient way. In the following sections, we will discuss the key aspects of clustering in detail.
Data Replication Channels
To facilitate metadata and message replication, the Erlang distribution protocol and a custom distribution protocol are utilized for inter-broker remote procedure calls. In an EMQX cluster, there are two data replication channels:
Metadata replication, such as routing information on which (wildcard) topics are being subscribed to by which nodes. This channel is powered by the "Erlang distribution" protocol, enabling each node to function as both a client and server. The default listening port number for this protocol is 4370.
Message delivery, such as when forwarding messages from one node to another. The message delivery channel employs a connection pool, and each node is configured to listen on port number 5370 by default (5369 when running in a Docker container). This approach differs from the Erlang distribution protocol, as the latter utilizes a single connection.
The diagram below illustrates the two data replication channels with a pub-sub flow. The dashed lines connecting the nodes indicate metadata replications, while the solid arrow lines represent the message delivery channel.
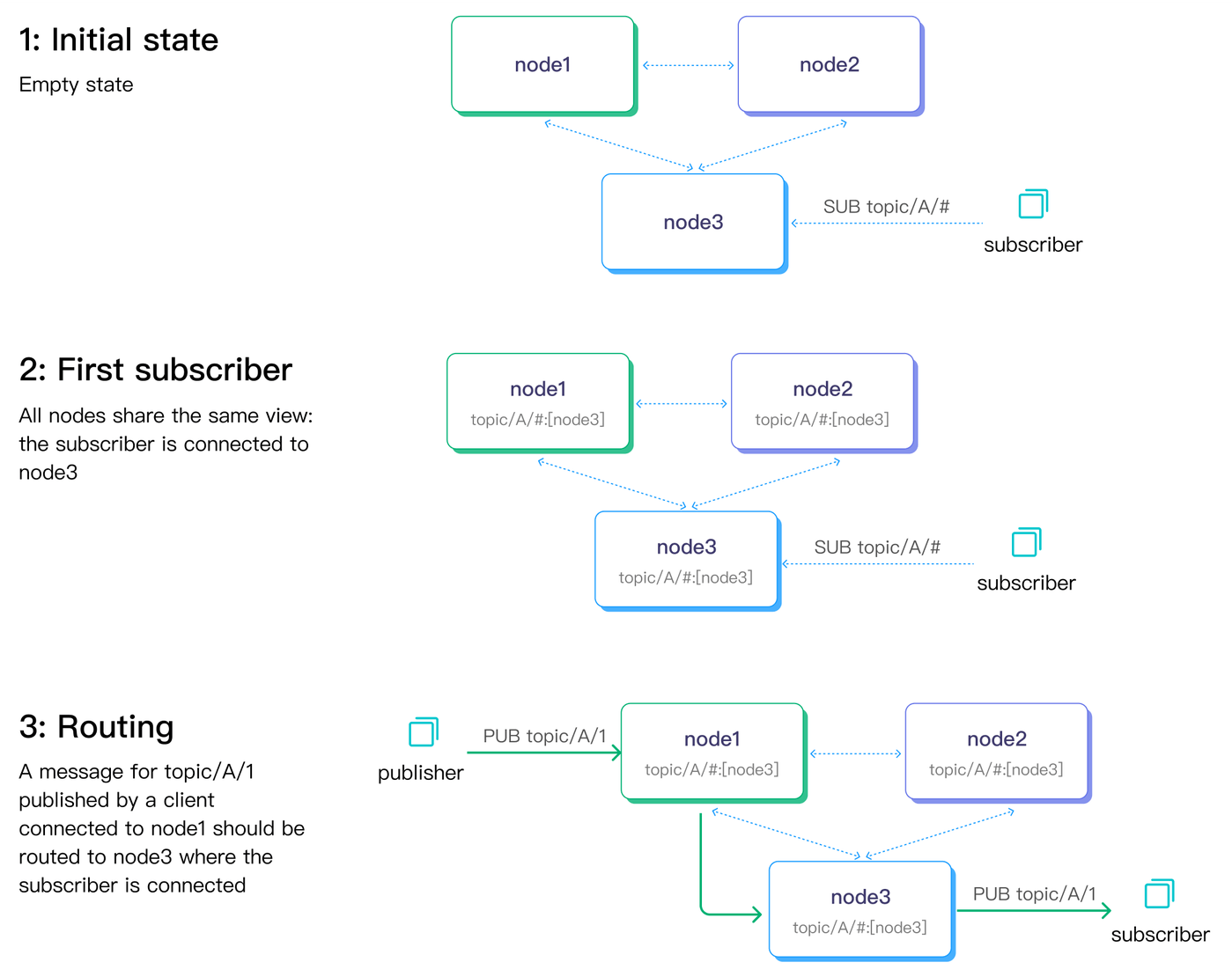
Built-in Databases
EMQX stores different kinds of internal data in one of two built-in database management systems:
Mria: a lightweight in-memory database, used for read-heavy workloads, such as the routing table and runtime configuration. In terms of the CAP theorem, this database is designed for availability.
Durable Storage (DS): a disk-based streaming database, used for write-heavy workloads and large volumes of data, such as messages sent to durable sessions and message queues. This database is designed for consistency.
These two database management systems have vastly different properties and provide different guarantees during network partition. This document focuses on Mria and behavior of EMQX without going into details about durability features, which are optional. For information regarding durable storage, please read the following document: Durable Storage.
Mria tables can be further split into two categories:
Regular, with contents of the table being globally uniform. The majority of Mria tables are regular.
Merge, a special type of table where each record is owned by a particular EMQX node. Only the EMQX node owning the record can modify it, while to the others it appears read-only.
Node Roles: Core and Replicant
Mria uses a mixed network topology that consists of two type of node roles: core and replicant.
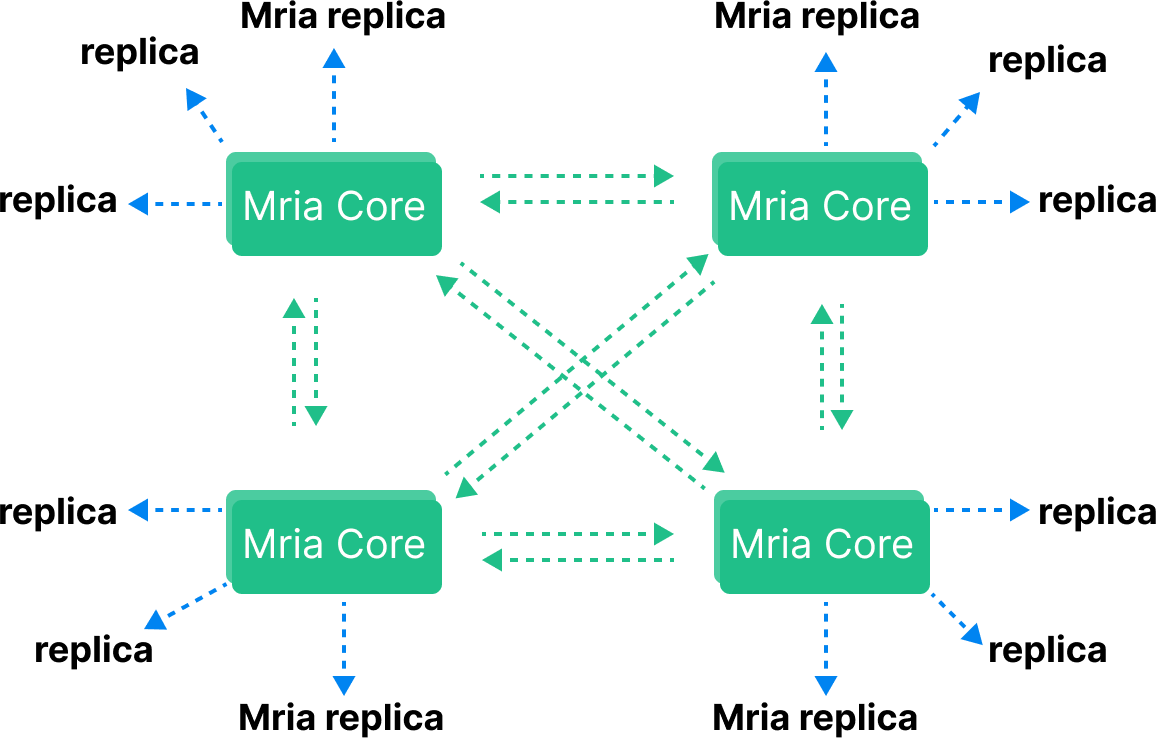
Each EMQX cluster should have at least one Core node, and any number of Replicant nodes.
Core nodes serve as the backbone of Mria, as they coordinate updates to regular tables. Updates to such tables are synchronously replicated across the cluster of core nodes. Because of the costs associated with such coordination, it is recommended to have a limited number of core nodes to cover the data redundancy requirements, and assign the Replicant role to the rest. The typical number of core nodes in a cluster is 3.
Replicant nodes are not directly involved in the processing of transactions. They connect to Core nodes and passively replicate data updates from Core nodes. Replicant nodes are not allowed to perform any write operations. Instead, write requests are forwarded to a Core node for execution. In addition, because Replicants replicate data from Core nodes, they have a complete local copy of data to achieve the highest efficiency of read operations, which helps reduce the latency of various database queries in EMQX.
Since Replicant nodes do not participate in write operations, the latency of write operations will not be affected when more Replicant nodes join the cluster. This allows the creation of larger EMQX clusters with tens of Replicant nodes.
For performance reasons, data replication is divided into independent data streams: multiple related data tables can be assigned to the same RLOG Shard (replicated log shard), and transactions are sequentially replicated from Core nodes to the Replicant node. Different RLOG Shards are independent.
Merge Tables
Merge tables are a special type of Mria table, where each record can be unambiguously associated with a particular EMQX node. One such example is the EMQX routing table. The routing table is the most important distributed data structure in an MQTT broker, used to store the routing information of all topics. The routing table is used to determine which nodes should receive a message published to a particular topic.
Contrary to the behavior of regular tables, every EMQX node (Core or Replicant) updates its own records directly, without coordination with other nodes. Then the updates are asynchronously replicated to the rest of the cluster. In a sense, each node acts as both Core and Replicant for merged tables.
This design has the following advantages:
- Reduced write latency
- Reduced load on the Core nodes
- Improved partition tolerance: even in a fully partitioned network, it is guaranteed that each node retains at least its own routes.
When a network partition heals, nodes merge contents of their routing tables, hence the name.
Centralized Management
EMQX can be managed centrally, as all nodes in the cluster can be monitored and controlled from a single management console. This makes it easy to manage a large number of devices and messages. The console is accessible via a web browser and provides a user-friendly interface for managing the cluster. Any core type node can serve as the management HTTP API endpoint.
The online configuration management feature allows making configuration changes on all nodes in the cluster without having to restart the nodes. This is especially useful for cluster configuration updates, such as adding or removing nodes.
Easy to Scale
EMQX is designed to be easy to scale horizontally. You can choose to add or delete nodes to or from the cluster at any time from the CLI, API, or even the Dashboard.
For example, to add a new node to the cluster it can be as simple as executing a command like this:
emqx ctl cluster join emqx@node1.my.netWhere emqx@node1.my.net is one of the nodes in the cluster.
Or you can, from the Dashboard, click a button to invite a new node to join the cluster.
With the help of the rich management interfaces, you can easily script the cluster management and make it part of your DevOps pipeline.
In EMQX v5, the replica nodes are designed to be stateless, so they can be placed in an autoscaling group for better DevOps practices.
Cluster Rebalance
When a node newly joins the cluster, it will start off with an empty state. With a good load balancer, the newly connected clients may have a better chance to connect to the new node. However, the existing clients will still be connected to the old nodes.
If the clients reconnect in a relatively short period of time, the cluster can reach balance quickly. If the clients are not reconnecting, the cluster may remain unbalanced for a long time.
To address this issue, EMQX (since version 4.4) introduced a new feature called "Cluster Load Rebalancing". This feature allows the cluster to automatically rebalance the load by migrating the sessions from the overloaded nodes to the underloaded nodes.
An extreme version of "rebalance" is "evacuation", in which all the sessions are migrated off the given node. This is useful when you want to remove a node from the cluster.
Cluster Size
At the scale of millions of concurrent connections, you have no choice but to scale horizontally, because there is simply no single machine that can handle that many connections.
In EMQX v5, the core-replica clustering architecture allows us to scale the cluster to a much larger size.
In our benchmark, we tested 50 million publishers plus 50 million wildcard subscribers in a 23-node cluster. You can read our blog post to find more details.
Why wildcards? Because wildcard subscriptions are the gold standard when benchmarking MQTT broker cluster scalability. They challenge the underlying data structures and algorithms to the limit.
Automatic Failover
In the MQTT protocol specification, there is no concept of session affinity. This means that a client can connect to any node in the cluster and still be able to receive messages published to the topics it has subscribed to. There is also no service discovery mechanism in MQTT, so the client needs to know the address of the cluster nodes. This often requires the client to be configured with a list of all the nodes in the cluster, or even better, a load balancer that can route the client to the right node.
EMQX is designed to work with a load balancer in front of the cluster. With a health check endpoint, the load balancer can detect the health of the nodes in the cluster and route the client to the right node.
Using Erlang's node monitoring mechanism, EMQX nodes monitor each other's health status and will automatically remove unhealthy nodes from the cluster.
Network Partition Tolerance
When a network partition occurs, the cluster may split into multiple isolated subclusters, each believing it is the only active cluster. This is also known as the "split-brain" problem. A production cluster should be able to recover from a network partition automatically.
EMQX's 'autoheal' feature can automatically heal the cluster after a network partition. When the feature is enabled, after the network partition has occurred and then recovered, the nodes in the cluster will follow the steps below to heal the cluster.
Recovery procedure is performed differently on Core and Replicant nodes.
Core Node Recovery
- The node reports the partitions to a leader node which has the longest uptime.
- The leader node creates a global net split view and chooses one core node in the majority as the coordinator.
- The leader node requests the coordinator to command the core nodes on the minority side to reboot.
- The minority core nodes replace contents of their Mria tables with the contents of the majority partition.
Replicant Recovery
Replicant nodes are not rebooted during a network partition heal. This allows them to retain client connections.
They take the following steps instead:
- Replicants in the minority partition re-initialize their replicas of regular Mria tables.
- The routing table contents are merged: nodes in the majority partition re-establish routes to the minority and vice versa.
- Clients re-establish their presence in the global session registry.
For the log messages and alarms generated during partition recovery, see Mria Logs and Alarms.
Summary
In this article, we have introduced the new clustering architecture of EMQX. We have also discussed the key aspects of a production-ready MQTT broker cluster, including scalability, automatic failover, network partition tolerance, and so on, and how EMQX can help you achieve these goals.