Ingest MQTT Data into Amazon S3
Amazon S3 is an internet-based storage service known for its high reliability, stability, and security, allowing for rapid deployment and ease of use. EMQX is capable of efficiently storing MQTT messages into Amazon S3 buckets, enabling flexible Internet of Things (IoT) data storage functionalities.
This page provides a detailed introduction to the data integration between EMQX and Amazon S3 and offers practical guidance on the rule and Sink creation.
TIP
EMQX is also compatible with other storage services supporting the S3 protocol, such as:
- MinIO: MinIO is a high-performance, distributed object storage system. It is an open-source object storage server compatible with the Amazon S3 API, suitable for building private clouds.
- Google Cloud Storage: Google Cloud Storage is Google Cloud's unified object storage for developers and enterprises to store large amounts of data. It offers an Amazon S3-compatible interface.
You can choose the appropriate storage service based on your business needs and scenarios.
How It Works
Amazon S3 data integration in EMQX is a ready-to-use feature that can be easily configured for complex business development. In a typical IoT application, EMQX acts as the IoT platform responsible for device connectivity and message transmission, while Amazon S3 serves as the data storage platform, handling message data storage.
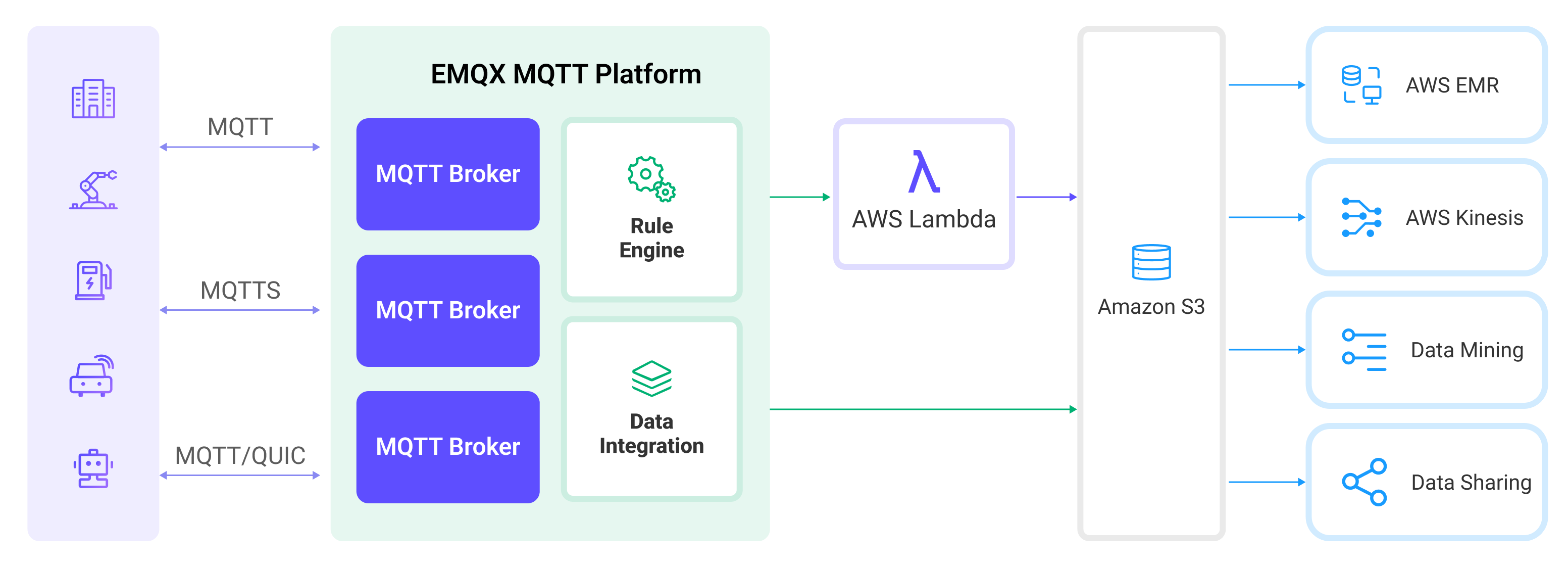
EMQX utilizes rules engines and Sinks to forward device events and data to Amazon S3. Applications can read data from Amazon S3 for further data applications. The specific workflow is as follows:
- Device Connection to EMQX: IoT devices trigger an online event upon successfully connecting via the MQTT protocol. The event includes device ID, source IP address, and other property information.
- Device Message Publishing and Receiving: Devices publish telemetry and status data through specific topics. EMQX receives the messages and compares them within the rules engine.
- Rules Engine Processing Messages: The built-in rules engine processes messages and events from specific sources based on topic matching. It matches corresponding rules and processes messages and events, such as data format transformation, filtering specific information, or enriching messages with context information.
- Writing to Amazon S3: The rule triggers an action to write the message to S3. Using the Amazon S3 Sink, users can extract data from processing results and send it to S3. Messages can be stored in text or binary format, or multiple lines of structured data can be aggregated into a single CSV, JSON Lines or Parquet file, depending on the message content and the Sink configuration.
After events and message data are written to Amazon S3, you can connect to Amazon S3 to read the data for flexible application development, such as:
- Data archiving: Store device messages as objects in Amazon S3 for long-term preservation to meet compliance requirements or business needs.
- Data analysis: Import data from S3 into analytics services like Snowflake for predictive maintenance, device efficiency evaluation, and other data analysis services.
Features and Benefits
Using Amazon S3 data integration in EMQX can bring the following features and advantages to your business:
- Message Transformation: Messages can undergo extensive processing and transformation in EMQX rules before being written to Amazon S3, facilitating subsequent storage and use.
- Flexible Data Operations: With the S3 Sink, specific fields of data can be conveniently written into Amazon S3 buckets, supporting the dynamic setting of bucket and object keys for flexible data storage.
- Integrated Business Processes: The S3 Sink allows device data to be combined with the rich ecosystem applications of Amazon S3, enabling more business scenarios like data analysis and archiving.
- Low-Cost Long-Term Storage: Compared to databases, Amazon S3 offers a highly available, reliable, and cost-effective object storage service, suitable for long-term storage needs.
These features enable you to build efficient, reliable, and scalable IoT applications and benefit from business decisions and optimizations.
Before You Start
This section introduces the preparations required before creating an Amazon S3 Sink in EMQX.
Prerequisites
Before proceeding, make sure you are familiar with the following:
EMQX Concepts:
- Rule Engine: Understand how rules define the logic for extracting and transforming data from MQTT messages.
- Data Integration: Understand the concept of connectors and sinks in EMQX data integration.
AWS Concepts:
If you're new to AWS S3, review the following concepts:
- EC2: AWS’s virtual machine service (compute instances).
- IAM: AWS Identity and Access Management; an instance role can issue temporary credentials to programs running on that instance.
- IMDSv2: EC2’s Instance Metadata Service v2 for retrieving metadata/temporary credentials; token-based and more secure.
Prepare an S3 Bucket
EMQX supports Amazon S3 and other S3-compatible storage services. You can use AWS cloud services or deploy a MinIO instance with Docker.
Create a Connector
Before adding the S3 Sink, you need to create the corresponding connector.
Go to the Dashboard Integration -> Connector page.
Click the Create button in the top right corner.
Select Amazon S3 as the connector type and click Next.
Enter a name for the connector. The name must start with a letter or number and can contain letters, numbers, hyphens, or underscores. In this example, enter
my-s3.Enter the connection information.
- If you are using the Amazon S3 bucket, enter the following information:
Host: The host varies by region and is formatted as
s3.{region}.amazonaws.com.Port: Enter
443.Access Key ID and Secret Access Key:
- Enter the access keys created in AWS, or
- Leave blank if running EMQX on EC2 with an attached IAM role.
See the "Amazon S3" tab in Prepare an S3 Bucket for details.
- If you are using MinIO, enter the following information:
- Host: Enter
127.0.0.1. If you are running MinIO remotely, enter the actual host address. - Port: Enter
9000. - Access Key ID and Secret Access Key: Enter the access keys created in MinIO.
- Host: Enter
- If you are using the Amazon S3 bucket, enter the following information:
Use the default values for the remaining settings.
Before clicking Create, you can click Test Connectivity to test if the connector can connect to the S3 service.
Click the Create button at the bottom to complete the connector creation.
You have now completed the connector creation and will proceed to create a rule and Sink for specifying the data to be written into the S3 service.
Create a Rule with Amazon S3 Sink
This section demonstrates how to create a rule in EMQX to process messages from the source MQTT topic t/# and write the processed results to the iot-data bucket in S3 through the configured Sink.
Go to the Dashboard Integration -> Rules page.
Click the Create button in the top right corner.
Enter the rule ID
my_rule, and input the following rule SQL in the SQL editor:sqlSELECT * FROM "t/#"TIP
If you are new to SQL, you can click SQL Examples and Enable Debug to learn and test the rule SQL results.
Add an action, select
Amazon S3from the Action Type dropdown list, keep the action dropdown as the defaultcreate actionoption, or choose a previously created Amazon S3 action from the action dropdown. Here, create a new Sink and add it to the rule.Enter the Sink's name and description.
Select the
my-s3connector created earlier from the connector dropdown. You can also click the create button next to the dropdown to quickly create a new connector in the pop-up box. The required configuration parameters can be found in Create a Connector.Set the Bucket by entering
iot-data. This field also supports${var}format placeholders, but ensure the corresponding name bucket is created in S3 in advance.Select ACL as needed, specifying the access permission for the uploaded object.
Select the Upload Method. The differences between the two methods are as follows:
- Direct Upload: Each time the rule is triggered, data is uploaded directly to S3 according to the preset object key and content. This method is suitable for storing binary or large text data. However, it may generate a large number of files.
- Aggregated Upload: This method packages the results of multiple rule triggers into a single file (such as a CSV file) and uploads it to S3, making it suitable for storing structured data. It can reduce the number of files and improve write efficiency.
The configuration parameters differ for each method. Please configure according to the selected method:
Fallback Actions (Optional): If you want to improve reliability in case of message delivery failure, you can define one or more fallback actions. These actions will be triggered if the primary Sink fails to process a message. See Fallback Actions for more details.
Expand Advanced Settings and configure the advanced setting options as needed (optional). For more details, refer to Advanced Settings.
Use the default values for the remaining settings. Click the Create button to complete the Sink creation. After successful creation, the page will return to the rule creation, and the new Sink will be added to the rule actions.
Back on the rule creation page, click the Create button to complete the entire rule creation process.
You have now successfully created the rule. You can see the newly created rule on the Rules page and the new S3 Sink on the Actions (Sink) tab.
You can also click Integration -> Flow Designer to view the topology. The topology visually shows how messages under the topic t/# are written into S3 after being parsed by the rule my_rule.
Parquet Format Options
When the Aggregation Type is set to parquet, EMQX stores aggregated rule results in the Apache Parquet format, a columnar, compressed file format optimized for analytical workloads.
This section describes all configurable options for the Parquet output format.
Parquet Schema (Avro)
This option defines how MQTT message fields are mapped to the columns in the Parquet file. EMQX uses the Apache Avro schema specification to describe the structure of the Parquet data.
You can choose one of the following options:
Avro Schema That Lives in Schema Registry: Use an existing Avro schema managed in EMQX Schema Registry.
When this option is chosen, you must also specify a Schema Name, which identifies the schema to use for serialization.
TIP
Use this option if you manage schemas centrally in a registry and want consistent schema evolution across multiple systems.
Avro Schema Defined: Define the Avro schema directly within EMQX by entering the schema JSON structure in the Schema Definition field.
Example:
json{ "type": "record", "name": "MessageRecord", "fields": [ {"name": "clientid", "type": "string"}, {"name": "timestamp", "type": "long"}, {"name": "payload", "type": "string"} ] }
TIP
Ensure that the field names and data types match the fields returned by your rule SQL. Incorrect or missing fields may cause serialization errors when writing to Parquet.
Parquet Default Compression
This option specifies the compression algorithm applied to Parquet data pages within each row group. Compression helps reduce storage space and can improve I/O efficiency when querying data.
Supported values:
| Value | Description |
|---|---|
snappy (default) | A balanced choice offering fast compression and decompression with good compression ratio. Recommended for most cases. |
zstd | Provides a higher compression ratio with moderate CPU usage. Ideal for large-scale analytical data or long-term storage. |
None | Disables compression. Suitable only for debugging or when compression is not desired. |
Parquet Max Row Group Bytes
This option specifies the maximum size (in bytes) for each Parquet row group, which is the fundamental unit of work for reading and writing data. Once the buffered data size exceeds this threshold, EMQX flushes the current row group and starts a new one.
- Default value:
128 MB
Guidelines:
- Increase the value to improve read performance for analytical queries, especially when using Athena or Spark.
- Reduce the value to limit memory usage during writing or when using small datasets.
TIP
Parquet readers load data at the row group level. Larger row groups typically reduce metadata overhead and improve analytical query performance.
Test the Rule
This section shows how to test the rule configured with the direct upload method.
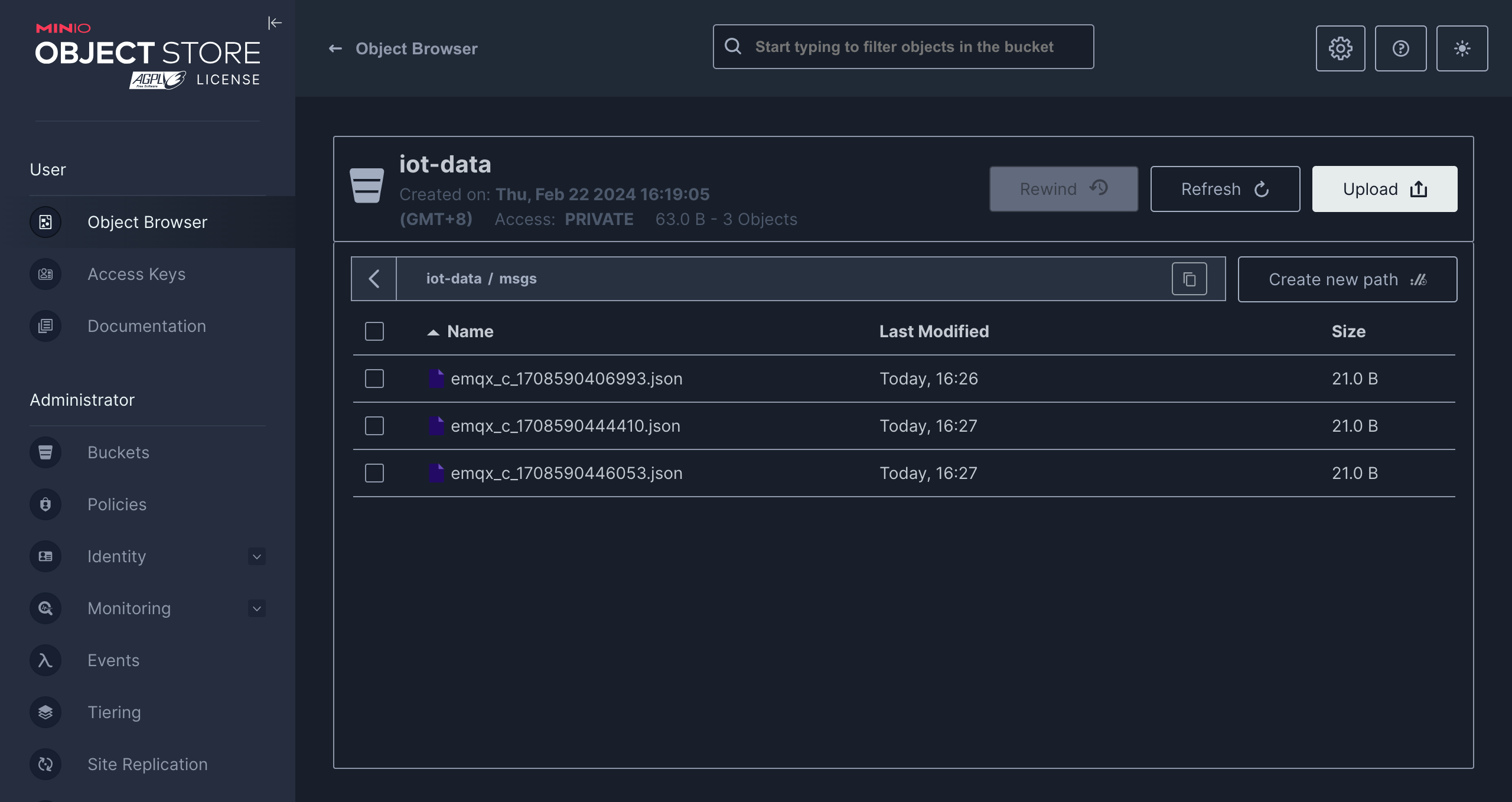
Use MQTTX to publish a message to the topic t/1:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "hello S3" }'After sending a few messages, access the MinIO console or Amazon S3 console to see the result.
Advanced Settings
This section delves into the advanced configuration options available for the S3 Sink. In the Dashboard, when configuring the Sink, you can expand Advanced Settings to adjust the following parameters based on your specific needs.
| Field Name | Description | Default Value |
|---|---|---|
| Buffer Pool Size | Specifies the number of buffer worker processes, which are allocated to manage the data flow between EMQX and S3. These workers temporarily store and process data before sending it to the target service, crucial for optimizing performance and ensuring smooth data transmission. | 16 |
| Request TTL | The "Request TTL" (Time To Live) configuration setting specifies the maximum duration, in seconds, that a request is considered valid once it enters the buffer. This timer starts ticking from the moment the request is buffered. If the request stays in the buffer for a period exceeding this TTL setting or if it is sent but does not receive a timely response or acknowledgment from S3, the request is deemed to have expired. | 45 |
| Health Check Interval | Specifies the time interval (in seconds) for the Sink to perform automatic health checks on its connection with S3. | 15 seconds |
| Health Check Interval Jitter | A uniform random delay added on top of the base health check interval to reduce the chance that multiple nodes initiate health checks at the same time. When multiple Actions or Sources share the same Connector, enabling jitter ensures their health checks are initiated at slightly different times. | 0 millisecond |
| Health Check Timeout | Specify the timeout duration for the connector to perform automatic health checks on its connection with S3 Tables. | 60 seconds |
| Max Buffer Queue Size | Specifies the maximum number of bytes that can be buffered by each buffer worker process in the S3 Sink. The buffer workers temporarily store data before sending it to S3, acting as intermediaries to handle the data stream more efficiently. Adjust this value based on system performance and data transmission requirements. | 256 MB |
| Query Mode | Allows you to choose between synchronous or asynchronous request modes to optimize message transmission according to different requirements. In asynchronous mode, writing to S3 does not block the MQTT message publishing process. However, this may lead to clients receiving messages before they arrive at S3. | Asynchronous |
| In-flight Window | "In-flight queue requests" refer to requests that have been initiated but have not yet received a response or acknowledgment. This setting controls the maximum number of in-flight queue requests that can exist simultaneously during Sink communication with S3. When Request Mode is set to asynchronous, the "Request In-flight Queue Window" parameter becomes particularly important. If strict sequential processing of messages from the same MQTT client is crucial, then this value should be set to 1. | 100 |
| Min Part Size | The minimum chunk size for part uploads after aggregation is complete. The data to be uploaded will accumulate in memory until it reaches this size. | 5MB |
| Max Part Size | The maximum chunk size for part uploads. The S3 Sink will not attempt to upload parts exceeding this size. | 5GB |