SnowflakeへのMQTTデータ取り込み
Snowflake は、クラウドベースのデータプラットフォームであり、高いスケーラビリティと柔軟性を備えたデータウェアハウジング、分析、セキュアなデータ共有のソリューションを提供します。構造化データおよび半構造化データの処理に優れ、大量のデータを高速なクエリ性能で保存し、さまざまなツールやサービスとシームレスに統合できるよう設計されています。
本ページでは、EMQXとSnowflake間のデータ統合について詳しく紹介し、ルールとSinkの作成方法について実践的なガイダンスを提供します。
動作の仕組み
EMQXにおけるSnowflakeデータ統合はすぐに使える機能であり、複雑なIoTビジネスワークフローを簡単にサポートできるように構成可能です。典型的なIoTアプリケーションでは、EMQXがデバイスの接続とメッセージ送受信を担うIoTプラットフォームとして機能し、Snowflakeはメッセージデータの取り込み、保存、分析を行うデータストレージおよび処理プラットフォームとして役割を果たします。
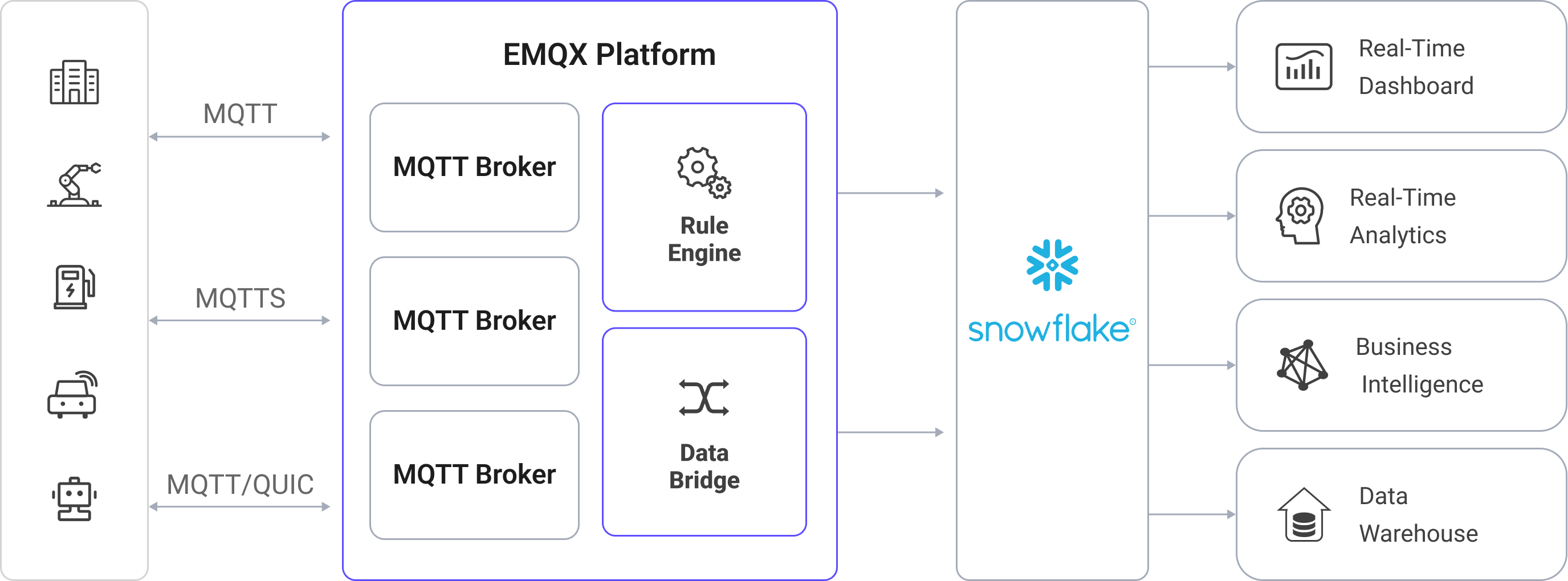
EMQXはルールエンジンとSinkを利用してデバイスのイベントやデータをSnowflakeに転送します。エンドユーザーやアプリケーションはSnowflakeのテーブル内のデータにアクセス可能です。具体的なワークフローは以下の通りです:
デバイスのEMQXへの接続:IoTデバイスはMQTTプロトコルで正常に接続されるとオンラインイベントをトリガーします。このイベントにはデバイスID、送信元IPアドレスなどの識別情報が含まれます。
デバイスのメッセージパブリッシュと受信:デバイスは特定のトピックを通じてテレメトリや状態データをパブリッシュします。EMQXはこれらのメッセージを受信し、ルールエンジン内で比較処理を行います。
ルールエンジンによるメッセージ処理:組み込みのルールエンジンはトピックマッチングに基づき特定のソースからのメッセージやイベントを処理します。対応するルールをマッチさせ、データフォーマット変換、特定情報のフィルタリング、コンテキスト情報の付加などの処理を実施します。
Snowflakeへの書き込み:ルールはメッセージデータをSnowflakeに書き込むアクションをトリガーします。メッセージをファイルにバッチングしてStageとPipe経由でロードする(集約モード)か、Snowpipe Streaming APIを使って直接ストリーミングする(ストリーミングモード)かのいずれかです。
イベントやメッセージデータがSnowflakeに書き込まれた後は、以下のようなビジネスおよび技術的な目的で利用可能です:
- データアーカイブ:IoTデータをSnowflakeに安全に長期保存し、コンプライアンスや履歴データの利用を保証します。
- データ分析:Snowflakeのデータウェアハウジングおよび分析機能を活用し、リアルタイムまたはバッチ分析を行い、予知保全、運用インサイト、デバイス性能評価を可能にします。
特長と利点
EMQXのSnowflakeデータ統合を利用することで、以下の特長と利点が得られます:
- メッセージ変換:Snowflakeに書き込む前に、EMQXのルールでメッセージを多様に処理・変換でき、後続の保存や利用を容易にします。
- 柔軟なデータ操作:Snowflake Sinkは書き込むフィールドを選択可能で、ビジネスニーズに応じた効率的かつ動的なストレージ構成を実現します。
- 統合されたビジネスプロセス:Snowflake SinkによりデバイスデータをSnowflakeの豊富なエコシステムアプリケーションと組み合わせられ、データ分析やアーカイブなど多様なビジネスシナリオを実現します。
- 低コストの長期保存:Snowflakeのスケーラブルなストレージ基盤は、従来のデータベースより低コストで長期データ保持に最適であり、大量のIoTデータ保存に適しています。
これらの特長により、効率的で信頼性が高くスケーラブルなIoTアプリケーションを構築し、ビジネスの意思決定や最適化に役立てられます。
はじめる前に
このセクションでは、EMQXでSnowflake Sinkを作成する前の準備について説明します。
前提条件
アップロードモードの選択
TIP
最初にモードを選択してください。これはEMQXとSnowflake環境の両方の設定方法を決定します。
EMQXはSnowflakeへのデータ送信に以下の2つのモードをサポートしています:
| モード | 説明 | ODBC必要性 |
|---|---|---|
| 集約(Aggregated) | EMQXがMQTTメッセージをローカルファイルにバッファリングし、SnowflakeのStageにアップロードします。COPY INTO文で設定されたPipeが自動的にステージファイルをターゲットテーブルにロードします。詳細はSnowflake Snowpipeドキュメントを参照。 | 必須 |
| ストリーミング(Streaming) | Snowpipe Streaming APIを介してリアルタイムにデータを送信し、行を直接Snowflakeテーブルに書き込みます。 | 必須 |
Snowflake ODBCドライバーの初期化
EMQXがSnowflakeと通信し効率的にデータ転送を行うために、SnowflakeのOpen Database Connectivity(ODBC)ドライバーをインストールおよび設定する必要があります。このドライバーはEMQXがSnowflakeのStageにデータを書き込むための通信橋渡し役を果たし、データの適切なフォーマット、認証、転送を保証します。
詳細は公式のODBCドライバーページおよびライセンス契約を参照してください。
LinuxでのSnowflake ODBCドライバー初期化
EMQXはDebian系(Ubuntuなど)向けにSnowflake ODBCドライバーの迅速な導入と必要なシステム設定を行うインストールスクリプトを提供しています。
注意
このスクリプトはテスト用であり、本番環境でのODBCドライバー設定方法として推奨するものではありません。公式のLinux向けインストール手順を参照してください。
インストールスクリプトの実行
scripts/install-snowflake-driver.sh スクリプトをローカルマシンにコピーし、chmod a+xで実行権限を付与後、sudoで実行します:
chmod a+x scripts/install-snowflake-driver.sh
sudo ./scripts/install-snowflake-driver.shスクリプトはSnowflake ODBCの.debインストールパッケージ(例:snowflake-odbc-3.4.1.x86_64.deb)をカレントディレクトリに自動ダウンロードし、ドライバーをインストール、以下のシステム設定ファイルを更新します:
/etc/odbc.ini:Snowflakeデータソース設定を追加/etc/odbcinst.ini:Snowflakeドライバーパスを登録
設定例
/etc/odbc.iniの設定を確認するコマンド例:
emqx@emqx-0:~$ cat /etc/odbc.ini
[snowflake]
Description=SnowflakeDB
Driver=SnowflakeDSIIDriver
Locale=en-US
PORT=443
SSL=on
[ODBC Data Sources]
snowflake = SnowflakeDSIIDriver/etc/odbcinst.iniの設定を確認するコマンド例:
emqx@emqx-0:~$ cat /etc/odbcinst.ini
[ODBC Driver 18 for SQL Server]
Description=Microsoft ODBC Driver 18 for SQL Server
Driver=/opt/microsoft/msodbcsql18/lib64/libmsodbcsql-18.5.so.1.1
UsageCount=1
[ODBC Driver 17 for SQL Server]
Description=Microsoft ODBC Driver 17 for SQL Server
Driver=/opt/microsoft/msodbcsql17/lib64/libmsodbcsql-17.10.so.6.1
UsageCount=1
[SnowflakeDSIIDriver]
APILevel=1
ConnectFunctions=YYY
Description=Snowflake DSII
Driver=/usr/lib/snowflake/odbc/lib/libSnowflake.so
DriverODBCVer=03.52
SQLLevel=1
UsageCount=1macOSでのSnowflake ODBCドライバー初期化
macOSでSnowflake ODBCドライバーをインストールおよび設定する手順は以下の通りです:
unixODBCをインストール(例):
brew install unixodbc詳細なインストールおよび設定手順はmacOS向けODBCドライバーのインストールと設定を参照してください。
インストール後、以下の設定ファイルを更新します。
Snowflake ODBCドライバーの権限と設定を更新:
bashchown $(id -u):$(id -g) /opt/snowflake/snowflakeodbc/lib/universal/simba.snowflake.ini echo 'ODBCInstLib=libiodbcinst.dylib' >> /opt/snowflake/snowflakeodbc/lib/universal/simba.snowflake.iniODBC接続設定のために
~/.odbc.iniファイルを作成または更新:cat << EOF > ~/.odbc.ini [ODBC] Trace=no TraceFile= [ODBC Drivers] Snowflake = Installed [ODBC Data Sources] snowflake = Snowflake [Snowflake] Driver = /opt/snowflake/snowflakeodbc/lib/universal/libSnowflake.dylib EOF
ユーザーアカウント作成とSnowflakeリソースのセットアップ
アップロードモードに関わらず、Snowflake環境においてユーザーアカウント、データベース、関連リソースを設定し、データ取り込み用の準備を行う必要があります。以下の認証情報は後でEMQXのコネクターおよびSink設定時に必要となります:
| 項目名 | 値 | 説明 |
|---|---|---|
| データソース名(DSN) | snowflake(集約モードのみ) | /etc/odbc.iniに設定されたODBC DSN。集約アップロード用。 |
| ユーザー名 | snowpipeuser | Snowflake接続認証に使用するユーザー。適切な権限が必要。 |
| パスワード | Snowpipeuser99 | キーペア認証使用時は省略可能。 |
| データベース名 | testdatabase | 対象テーブルが存在するSnowflakeデータベース。 |
| スキーマ | public | データベース内のスキーマ。テーブルおよびパイプが存在する場所。 |
| ステージ(集約モード) | emqx | データ取り込み前にファイルを保持するSnowflakeステージ。 |
| パイプ(集約モード) | emqx | ステージからテーブルへデータをロードするパイプ。 |
| パイプ(ストリーミング) | emqxstreaming | Snowpipe Streaming API用にDATA_SOURCE(TYPE => 'STREAMING')で作成したパイプ。 |
| プライベートキー | file://<path to snowflake_rsa_key.private.pem> | API認証用JWT署名に使用するRSA秘密鍵のパス。 |
RSAキーペアの生成(集約モードは任意)
Snowflakeは複数の認証方式をサポートしており、EMQXではアップロードモードや接続設定に応じて選択します:
| アップロードモード | 認証オプション | キーペア必要性 |
|---|---|---|
| ストリーミング(HTTPS) | RSAキーペア+JWT(唯一のサポート方式) | 必須 |
| 集約(ODBC) | ユーザー名/パスワード(DSNまたはEMQX経由) RSAキーペア+JWT(任意、EMQXのみ設定) | 任意 |
キーペア認証はストリーミングモードで必須であり、EMQXはJWTに署名してSnowflakeのStreaming APIに安全に認証します。
集約モードではユーザー名/パスワードまたはRSAキーペアのいずれかを使用可能です。認証情報の提供方法は以下のいずれかです:
- ダッシュボードのEMQXコネクター設定にユーザー名とパスワードを直接入力。
- キーペア認証の場合は秘密鍵のパスを指定。
- EMQXにいずれも設定しない場合は、Linuxの
/etc/odbc.iniやmacOSの~/.odbc.iniなどのシステムDSNに正しく設定されていることを確認。
TIP
認証にはパスワードかプライベートキーのいずれかを使用し、両方を同時に使わないでください。
EMQXにどちらも設定しない場合は、/etc/odbc.iniの認証情報が使用されます。
例:ユーザー名/パスワードを使った/etc/odbc.ini
[snowflake]
Driver=SnowflakeDSIIDriver
Server=<account>.snowflakecomputing.com
UID=snowpipeuser
PWD=Snowpipeuser99
Database=testdatabase
Schema=public
Warehouse=compute_wh
Role=snowpipeこの方法により、EMQXは設定内で直接認証情報を含めずにDSN(
snowflake)を参照できます。
キーペア認証を使用する場合
RSAキーペア認証を使用または必須とする(例:ストリーミングモード)場合、以下のコマンドで鍵を生成し設定します:
# 秘密鍵の生成
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out snowflake_rsa_key.private.pem -nocrypt
# 公開鍵の生成
openssl rsa -in snowflake_rsa_key.private.pem -pubout -out snowflake_rsa_key.public.pemEMQXがキーペア認証を使用する場合(集約・ストリーミング両モード対応):
- EMQXは秘密鍵でJWTに署名し、安全かつ検証可能なIDトークンとして利用。
- Snowflakeは公開鍵で署名を検証。
詳細はキーペア認証とキーペアローテーションを参照してください。
SQLによるSnowflakeリソースのセットアップ
RSAキーペア生成後、aggregatedまたはstreamingの取り込み用に必要なSnowflakeオブジェクトをSQLで作成します。
対象は以下を含みます:
- データベースとテーブルの作成
- ステージとパイプの作成(
aggregated用) - ストリーミングパイプの作成(
streaming用) - ユーザーとロールの作成および権限付与
SnowflakeコンソールのSQLワークシートで以下のSQLを実行し、データベース、テーブル、ステージ、パイプを作成します:
sqlUSE ROLE accountadmin; -- データ格納用データベース作成(存在しない場合) CREATE DATABASE IF NOT EXISTS testdatabase; -- MQTTデータ受け取り用テーブル作成 CREATE OR REPLACE TABLE testdatabase.public.emqx ( clientid STRING, topic STRING, payload STRING, publish_received_at TIMESTAMP_LTZ ); -- ファイルアップロード用Snowflakeステージ作成(集約モードのみ) CREATE STAGE IF NOT EXISTS testdatabase.public.emqx FILE_FORMAT = (TYPE = CSV PARSE_HEADER = TRUE FIELD_OPTIONALLY_ENCLOSED_BY = '"') COPY_OPTIONS = (ON_ERROR = CONTINUE PURGE = TRUE); -- ステージからロードする集約モード用パイプ作成 CREATE PIPE IF NOT EXISTS testdatabase.public.emqx AS COPY INTO testdatabase.public.emqx FROM @testdatabase.public.emqx MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE; -- ストリーミングモード用パイプ作成(直接取り込み) CREATE PIPE IF NOT EXISTS testdatabase.public.emqxstreaming AS COPY INTO testdatabase.public.emqx ( clientid, topic, payload, publish_received_at ) FROM ( SELECT $1:clientid::STRING, $1:topic::STRING, $1:payload::STRING, $1:publish_received_at::TIMESTAMP_LTZ FROM TABLE(DATA_SOURCE(TYPE => 'STREAMING')) );- パイプ内の
COPY INTOにより、Snowflakeはステージまたはストリーミングされたデータを自動的にテーブルにロードします。 - ストリーミングパイプの
$1:field構文は、EMQX経由で取り込まれたJSONペイロードからフィールドを抽出します。
- パイプ内の
EMQXが認証に使用する専用ユーザー(例:
snowpipeuser)を作成し、RSA公開鍵をバインドします:sql-- ユーザーアカウント作成 CREATE USER IF NOT EXISTS snowpipeuser PASSWORD = 'Snowpipeuser99' MUST_CHANGE_PASSWORD = FALSE; -- RSA公開鍵をユーザーに設定 ALTER USER snowpipeuser SET RSA_PUBLIC_KEY = ' <YOUR_PUBLIC_KEY_CONTENTS_LINE_1> <YOUR_PUBLIC_KEY_CONTENTS_LINE_2> <YOUR_PUBLIC_KEY_CONTENTS_LINE_3> <YOUR_PUBLIC_KEY_CONTENTS_LINE_4> ';TIP
PEMファイルの
-----BEGIN PUBLIC KEY-----および-----END PUBLIC KEY-----の行は削除し、改行を保持したまま残りの内容を貼り付けてください。この鍵はSnowflakeユーザーにアップロードされ、Snowflake内に保存されます。
ユーザーに必要なロールを作成し、Snowflakeリソース管理権限を付与します:
sqlCREATE OR REPLACE ROLE snowpipe; -- データベースおよびスキーマの使用権限付与 GRANT USAGE ON DATABASE testdatabase TO ROLE snowpipe; GRANT USAGE ON SCHEMA testdatabase.public TO ROLE snowpipe; GRANT INSERT, SELECT ON testdatabase.public.emqx TO ROLE snowpipe; -- 集約モード用にステージとパイプの権限付与 GRANT READ, WRITE ON STAGE testdatabase.public.emqx TO ROLE snowpipe; GRANT OPERATE, MONITOR ON PIPE testdatabase.public.emqx TO ROLE snowpipe; -- ストリーミングモード用にストリーミングパイプの権限付与 GRANT OPERATE, MONITOR ON PIPE testdatabase.public.emqxstreaming TO ROLE snowpipe; -- ユーザーにロールを付与しデフォルトに設定 GRANT ROLE snowpipe TO USER snowpipeuser; ALTER USER snowpipeuser SET DEFAULT_ROLE = snowpipe;
集約モード用Snowflakeコネクターの作成
Snowflake Sinkで集約アップロードモードを使用する場合は、Snowflake環境との接続を確立するためにSnowflakeコネクターを作成する必要があります。このコネクターはODBC(DSN経由)を使用してステージを通じて接続します。
ダッシュボードの Integration -> Connector ページに移動。
右上の Create ボタンをクリック。
コネクタータイプで Snowflake を選択し、次へ。
コネクター名を入力(英数字の組み合わせ)。例として
my-snowflakeと入力。接続情報を入力。
Server Host:SnowflakeのエンドポイントURL。通常は
<Your Snowflake Organization ID>-<Your Snowflake Account Name>.snowflakecomputing.comの形式。<Your Snowflake Organization ID>-<Your Snowflake Account Name>はSnowflakeインスタンス固有のサブドメインに置き換え。Account:Snowflakeの組織IDとアカウント名をハイフン(
-)で区切って入力。SnowflakeコンソールのURLの一部。Data Source Name (DSN):ODBCドライバー設定時に
.odbc.iniで設定したsnowflakeを入力。Username:前述の設定で作成した
snowpipeuserを入力。Password:ODBC経由のユーザー名/パスワード認証用パスワード。任意入力:
ここに
Snowpipeuser99などを入力可能。または
/etc/odbc.iniに設定。キーペア認証の場合は空欄に。
TIP
認証にはパスワードかプライベートキーのいずれかを使用し、両方を同時に使わないでください。ここに設定がない場合は
/etc/odbc.iniの認証情報が使用されます。
Private Key Path:ODBC経由でSnowflake認証に使用するRSA秘密鍵の絶対パス。クラスター内の全ノードで同一パスである必要があります。例:
/etc/emqx/certs/snowflake_rsa_key.private.pem。Private Key Password:秘密鍵ファイルが暗号化されている場合の復号用パスワード。OpenSSLの
-nocryptオプションで生成した鍵は空欄。Proxy:HTTPプロキシ経由でSnowflakeに接続する設定。HTTPSプロキシは非対応。デフォルトはプロキシなし。プロキシを使う場合は
Enable Proxyを選択し、以下を入力:- Proxy Host:プロキシサーバーのホスト名またはIPアドレス。
- Proxy Port:プロキシサーバーのポート番号。
暗号化接続を有効にする場合は、Enable TLSのトグルをオンにします。TLS接続の詳細は外部リソースアクセスのTLSを参照。ストリーミングモードではHTTPS通信のためTLS必須。
詳細設定(任意):詳細設定を参照。
Createをクリックする前に、Test ConnectivityでSnowflakeへの接続確認が可能。
Createボタンをクリックしてコネクター作成を完了。
これでコネクターの作成が完了し、ルールとSinkを作成してSnowflakeへの書き込みを指定できます。
Snowflakeストリーミングコネクターの作成
Snowflake Sinkでストリーミングアップロードモードを使用する場合は、Snowflake環境との接続を確立するためにSnowflakeストリーミングコネクターを作成します。このコネクターはHTTPSとSnowpipe Streaming REST APIを使用します。
ダッシュボードの Integration -> Connector ページに移動。
右上の Create ボタンをクリック。
コネクタータイプで Snowflake Streaming を選択し、次へ。
コネクター名を入力(英数字の組み合わせ)。例として
my-snowflake-streamingと入力。接続情報を入力。
Server Host:SnowflakeのエンドポイントURL。通常は
<Your Snowflake Organization ID>-<Your Snowflake Account Name>.snowflakecomputing.comの形式。<Your Snowflake Organization ID>-<Your Snowflake Account Name>はSnowflakeインスタンス固有のサブドメインに置き換え。Account:Snowflakeの組織IDとアカウント名をハイフン(
-)で区切って入力。SnowflakeコンソールのURLの一部。Pipe User:対象パイプを操作できる権限を持つSnowflakeユーザー名。例:
snowpipeuser。ロールには少なくともOPERATEとMONITOR権限が必要。Private Key Path:EMQXがJWT署名に使用するRSA秘密鍵。PEM形式の秘密鍵全文を文字列として貼り付けるか、
file://で始まる秘密鍵ファイルのパスを指定可能。例:file:///etc/emqx/certs/snowflake_rsa_key.private.pem。Private Key Password:秘密鍵ファイルが暗号化されている場合の復号用パスワード。OpenSSLの
-nocryptオプションで生成した鍵は空欄。Proxy:HTTPプロキシ経由でSnowflakeに接続する設定。HTTPSプロキシは非対応。デフォルトはプロキシなし。プロキシを使う場合は
Enable Proxyを選択し、以下を入力:- Proxy Host:プロキシサーバーのホスト名またはIPアドレス。
- Proxy Port:プロキシサーバーのポート番号。
暗号化接続を有効にする場合は、Enable TLSのトグルをオンにします。TLS接続の詳細は外部リソースアクセスのTLSを参照。ストリーミングモードではHTTPS通信のためTLS必須。
詳細設定(任意):詳細設定を参照。
Createをクリックする前に、Test ConnectivityでSnowflakeへの接続確認が可能。
Createボタンをクリックしてコネクター作成を完了。
これでコネクターの作成が完了し、ルールとSinkを作成してSnowflakeへの書き込みを指定できます。
Snowflake Sinkを用いたルールの作成
このセクションでは、EMQXでルールを作成し、メッセージ(例:ソースMQTTトピックt/#)を処理して、処理結果を設定済みのSnowflake Sink経由でSnowflakeに書き込む方法を示します。
SQLを定義したルールの作成
ダッシュボードの Integration -> Rules ページに移動。
右上の Create ボタンをクリック。
ルールIDに
my_ruleを入力し、SQLエディターに以下のルールSQLを入力:sqlSELECT clientid, unix_ts_to_rfc3339(publish_received_at, 'millisecond') as publish_received_at, topic, payload FROM "t/#"TIP
SQLに不慣れな場合は、SQL ExamplesやEnable DebugをクリックしてルールSQLの結果を学習・テストできます。
TIP
Snowflake統合では、選択するフィールドはSnowflakeのテーブルのカラム数および名前と完全に一致させることが重要です。余分なフィールドを追加したり、
*で選択することは避けてください。ルールにアクションとしてSinkを追加します。
- 集約アップロードモードでSnowflakeに書き込む場合は、集約アップロードモードでSnowflake Sinkを追加を参照。
- ストリーミングアップロードモードでSnowflakeに書き込む場合は、ストリーミングアップロードモードでSnowflake Sinkを追加を参照。
アクション追加後、Action Outputsセクションに新しいSinkが表示されます。Create RuleページでSaveをクリックし、ルール作成を完了します。
これでルールの作成が完了し、Rulesページで新規ルールを確認でき、**Actions (Sink)**タブで新しいSnowflake Sinkも確認可能です。
また、Integration -> Flow Designerをクリックするとトポロジーが表示され、トピックt/#のメッセージがルールmy_ruleで処理されSnowflakeに書き込まれる流れを視覚的に確認できます。
集約アップロードモードでSnowflake Sinkを追加
このセクションでは、集約アップロードモードを使って処理結果をSnowflakeに書き込むSinkをルールに追加する方法を示します。このモードは複数のルールトリガー結果を1つのファイル(例:CSVファイル)にまとめてアップロードし、ファイル数を減らして書き込み効率を向上させます。
Create RuleページのAction OutputsセクションでAdd Actionをクリックし、ルールにアクションを追加。
Action Typeドロップダウンから
Snowflakeを選択し、ActionはデフォルトのCreate Actionのままか、既存のSnowflakeアクションを選択。ここでは新規Sinkを作成してルールに追加。Sink名(例:
snowflake_sink)と簡単な説明を入力。Connectorsドロップダウンから先に作成した
my-snowflakeコネクターを選択。隣の作成ボタンで新規コネクターをポップアップで素早く作成可能。必要な設定は集約モード用Snowflakeコネクターの作成を参照。集約アップロードモードの設定を行う。
Database Name:
testdatabaseを入力。EMQXデータ保存用に作成したSnowflakeデータベース。Schema:
publicを入力。testdatabase内のデータテーブルがあるスキーマ。Stage:
emqxを入力。Snowflakeで作成した、ロード前のファイルを保持するステージ。Pipe:
emqxを入力。ステージからテーブルへ自動ロードするパイプ。Pipe User:
snowpipeuserを入力。パイプ管理権限を持つSnowflakeユーザー。Private Key:パイプユーザーがSnowflakeパイプに安全にアクセスするためのRSA秘密鍵。以下いずれかの形式で指定可能:
- プレーンテキスト:PEM形式の秘密鍵全文を文字列として貼り付け。
- ファイルパス:
file://で始まる秘密鍵ファイルのパス。クラスター全ノードで同一パスかつEMQXアプリケーションユーザーがアクセス可能である必要あり。例:file:///etc/emqx/certs/snowflake_rsa_key.private.pem。
Private Key Password:秘密鍵ファイルが暗号化されている場合の復号パスワード。OpenSSLの
-nocryptオプションで生成した鍵は空欄。Aggregation Upload Format:現在は
csvのみ対応。Snowflakeにカンマ区切りCSV形式でステージング。Column Order:ドロップダウンからカラムの並び順を選択。生成されるCSVは選択したカラム順にソートされ、未選択カラムはアルファベット順に並びます。
Max Records:集約をトリガーする最大レコード数。例:
1000に設定すると1000件収集後にアップロード。最大レコード数到達時に1ファイルの集約が完了しアップロードされ、時間間隔がリセットされます。Time Interval:集約を行う時間間隔(秒)。例:
60に設定すると最大レコード数に達していなくても60秒ごとにアップロードされ、最大レコード数がリセットされます。Proxy:HTTPプロキシ経由でSnowflakeに接続する設定。HTTPSプロキシは非対応。デフォルトはプロキシなし。プロキシを使う場合は
Enable Proxyを選択し、以下を入力:- Proxy Host:プロキシサーバーのホスト名またはIPアドレス。
- Proxy Port:プロキシサーバーのポート番号。
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義可能。詳細はフォールバックアクションを参照。
詳細設定を展開し、必要に応じて高度な設定を行う(任意)。詳細は詳細設定を参照。
Createをクリックする前に、Test ConnectivityでSinkがSnowflakeに接続可能かテスト可能。
CreateボタンをクリックしてSink作成を完了。作成成功後はルール作成画面に戻り、新しいSinkがルールアクションに追加されます。
ストリーミングアップロードモードでSnowflake Sinkを追加
このセクションでは、ストリーミングアップロードモードを使って処理結果をSnowflakeに書き込むSinkをルールに追加する方法を示します。このモードはSnowpipe Streaming APIを利用したリアルタイム取り込みを可能にします。
Create RuleページのAction OutputsセクションでAdd Actionをクリックし、ルールにアクションを追加。
Action Typeドロップダウンから
Snowflake Streamingを選択し、ActionはデフォルトのCreate Actionのままか、既存のSnowflakeアクションを選択。ここでは新規Sinkを作成してルールに追加。Sink名(例:
snowflake_sink_streaming)と簡単な説明を入力。コネクターのドロップダウンから先に作成した
my-snowflake-streamingを選択。隣の作成ボタンで新規コネクターをポップアップで素早く作成可能。必要な設定はSnowflakeストリーミングコネクターの作成を参照。ストリーミングアップロードモードの設定を行う。
- Database Name:
testdatabaseを入力。EMQXデータ保存用に作成したSnowflakeデータベース。 - Schema:
publicを入力。testdatabase内のデータテーブルがあるスキーマ。 - Pipe:
emqxstreamingを入力。SQLで作成したSnowflakeストリーミングパイプ名。Snowflakeで定義した名前と完全一致させる必要あり。 - HTTP Pipelining:レスポンスを待たずに送信可能な最大HTTPリクエスト数。デフォルト:
100。 - Connect Timeout:Snowflakeへの接続確立のタイムアウト秒数。デフォルト:
15秒。 - Connection Pool Size:EMQXがこのSink用にSnowflakeと維持可能な同時接続数の最大値。デフォルト:
8。 - Max Inactive:アイドル状態の接続を閉じるまでの最大待機時間(秒)。デフォルト:
10秒。
- Database Name:
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義可能。詳細はフォールバックアクションを参照。
詳細設定を展開し、必要に応じて高度な設定を行う(任意)。詳細は詳細設定を参照。
Createをクリックする前に、Test ConnectivityでSinkがSnowflakeに接続可能かテスト可能。
CreateボタンをクリックしてSink作成を完了。作成成功後はルール作成画面に戻り、新しいSinkがルールアクションに追加されます。
ルールのテスト
このセクションでは、設定したルールのテスト方法を示します。
テストメッセージのパブリッシュ
MQTTクライアントMQTTXを使ってトピックt/1にメッセージをパブリッシュします:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "Hello Snowflake" }'複数回繰り返して複数のテストメッセージを生成してください。
Snowflake内のデータ確認
テストメッセージ送信後、Snowflakeに正常にデータが書き込まれたかを確認します。
SnowflakeのWebインターフェースにログイン。
Snowflakeコンソールで以下のSQLクエリを実行し、ルールで書き込まれた
emqxテーブルのデータを確認:SELECT * FROM testdatabase.public.emqx;これにより、
clientid、topic、payload、publish_received_atなどのフィールドを含む全レコードが表示されます。送信したテストメッセージ(例:
{ "msg": "Hello Snowflake" })やトピック、タイムスタンプなどのメタデータが確認できるはずです。
高度な設定
このセクションでは、Snowflake Sinkの詳細な設定オプションについて説明します。ダッシュボードでSink設定時にAdvanced Settingsを展開し、用途に応じて以下のパラメーターを調整可能です。
| 項目名 | 説明 | デフォルト値 |
|---|---|---|
| Buffer Pool Size | EMQXとSnowflake間のデータフローを管理するバッファワーカーの数を指定します。これらのワーカーはデータを一時的に保持・処理し、パフォーマンス最適化とスムーズなデータ送信を支えます。 | 16 |
| Request TTL | バッファに入ってからリクエストが有効とみなされる最大秒数です。TTLを超えたリクエストや、送信済みでSnowflakeからの応答やアックがタイムリーに得られない場合は期限切れと判断されます。 | 45 秒 |
| Health Check Interval | Snowflakeとの接続状態を自動でチェックする間隔(秒)を指定します。 | 15 秒 |
| Health Check Interval Jitter | 複数ノードが同時にヘルスチェックを開始するのを避けるために、基本間隔に加算される一様ランダム遅延です。複数のアクションやソースが同じコネクターを共有する場合に有効です。 | 0 ミリ秒 |
| Health Check Timeout | Snowflake接続の自動ヘルスチェックのタイムアウト時間(秒)を指定します。 | 60 秒 |
| Max Buffer Queue Size | Snowflake Sinkの各バッファワーカーが一時的に保持可能な最大バイト数を指定します。バッファワーカーはデータ送信前の中継役として機能し、システム性能やデータ送信要件に応じて調整してください。 | 256 MB |
| Query Mode | synchronousまたはasynchronousのリクエストモードを選択し、メッセージ送信を最適化します。非同期モードではSnowflakeへの書き込みがMQTTメッセージパブリッシュをブロックしませんが、クライアントがSnowflake到達前にメッセージを受信する可能性があります。 | Asynchronous |
| Batch Size | EMQXからSnowflakeへ一度に送信するデータバッチの最大サイズを指定します。サイズ調整により転送効率やパフォーマンスを最適化可能です。1に設定するとバッチングせず個別送信となります。 | 100 |
| Inflight Window | 送信済みで応答やアックをまだ受け取っていない「インフライト」リクエストの最大数を制御します。Request Modeがasynchronousの場合に重要で、同一MQTTクライアントからのメッセージを厳密に順序処理したい場合は1に設定してください。 | 100 |