Amazon S3へのMQTTデータ取り込み
Amazon S3は、高い信頼性、安定性、セキュリティを備えたインターネットベースのストレージサービスであり、迅速なデプロイと使いやすさが特徴です。EMQXはMQTTメッセージを効率的にAmazon S3バケットに保存でき、柔軟なIoTデータストレージ機能を実現します。
本ページでは、EMQXとAmazon S3間のデータ統合について詳しく紹介し、ルールおよびSinkの作成方法を実践的に解説します。
TIP
EMQXは、以下のようなS3プロトコルに対応した他のストレージサービスとも互換性があります。
- MinIO:MinIOは高性能な分散オブジェクトストレージシステムで、Amazon S3 API互換のオープンソースオブジェクトストレージサーバーです。プライベートクラウド構築に適しています。
- Google Cloud Storage:Google Cloud StorageはGoogle Cloudの統合オブジェクトストレージで、大量データの保存に対応し、Amazon S3互換のインターフェースを提供します。
用途やビジネスニーズに応じて適切なストレージサービスを選択可能です。
動作概要
EMQXのAmazon S3データ統合はすぐに使える機能で、複雑なビジネス開発も簡単に設定できます。典型的なIoTアプリケーションでは、EMQXがデバイスの接続とメッセージ転送を担うIoTプラットフォームとして機能し、Amazon S3がメッセージデータの保存を担当します。
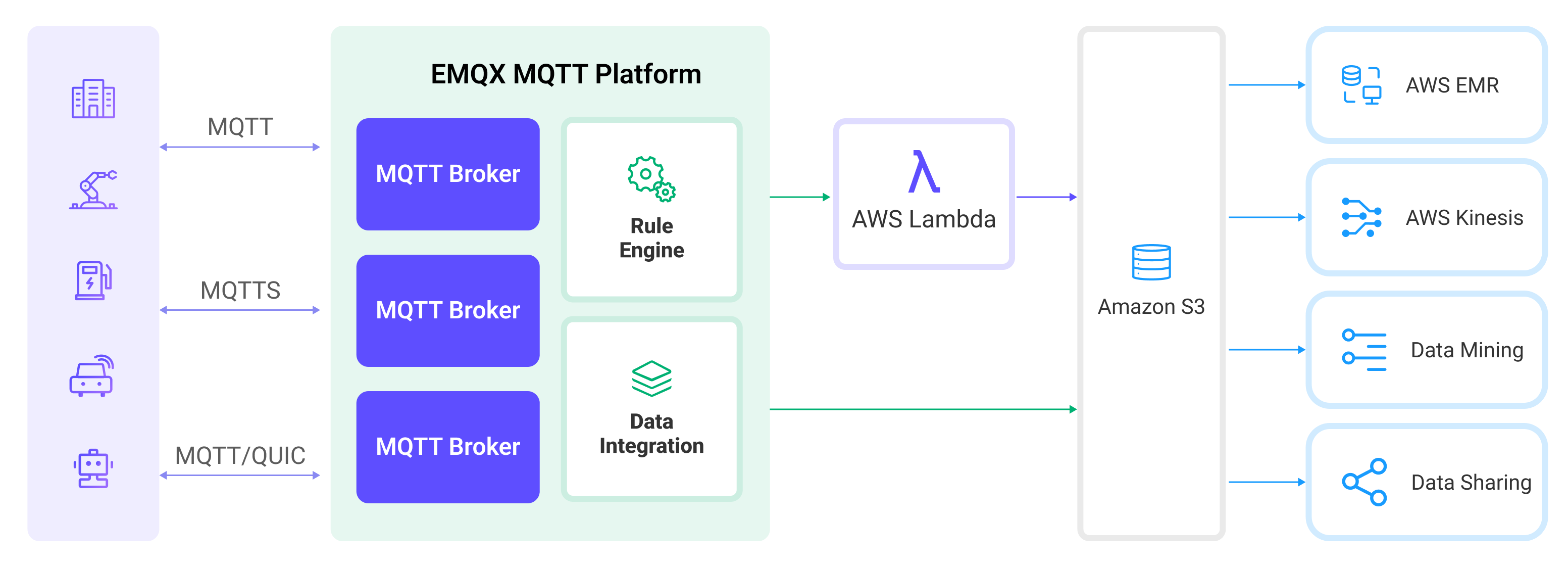
EMQXはルールエンジンとSinkを利用してデバイスのイベントやデータをAmazon S3へ転送します。アプリケーションはAmazon S3からデータを読み取り、さらなるデータ活用が可能です。具体的なワークフローは以下の通りです:
- デバイスのEMQX接続:IoTデバイスはMQTTプロトコルで正常に接続するとオンラインイベントを発生させます。このイベントにはデバイスID、送信元IPアドレスなどの属性情報が含まれます。
- デバイスのメッセージパブリッシュと受信:デバイスは特定のトピックを通じてテレメトリや状態データをパブリッシュします。EMQXはメッセージを受信し、ルールエンジン内で比較処理を行います。
- ルールエンジンによるメッセージ処理:組み込みのルールエンジンはトピックマッチングに基づき特定のソースからのメッセージやイベントを処理します。対応するルールをマッチさせ、データ形式変換、特定情報のフィルタリング、コンテキスト情報の付加などの処理を行います。
- Amazon S3への書き込み:ルールはメッセージをS3に書き込むアクションをトリガーします。Amazon S3 Sinkを利用し、処理結果からデータを抽出してS3に送信します。メッセージはテキストまたはバイナリ形式で保存可能で、複数行の構造化データを単一のCSVまたはJSON Linesファイルにまとめることもできます。これはメッセージ内容やSinkの設定によります。
イベントやメッセージデータがAmazon S3に書き込まれた後は、Amazon S3に接続してデータを読み取り、以下のような柔軟なアプリケーション開発が可能です:
- データアーカイブ:デバイスメッセージをAmazon S3のオブジェクトとして長期保存し、コンプライアンス要件やビジネスニーズに対応。
- データ分析:S3から分析サービス(例:Snowflake)にデータを取り込み、予知保全やデバイス効率評価などのデータ分析を実施。
特徴と利点
EMQXのAmazon S3データ統合を利用することで、以下の特長とメリットをビジネスにもたらします:
- メッセージ変換:メッセージはEMQXルール内で高度に処理・変換されてからAmazon S3に書き込まれ、後続の保存や利用が容易になります。
- 柔軟なデータ操作:S3 Sinkを使うことで、特定のデータフィールドをAmazon S3バケットに手軽に書き込み可能で、バケットやオブジェクトキーの動的設定にも対応し柔軟なデータ保存が可能です。
- 統合されたビジネスプロセス:S3 SinkによりデバイスデータをAmazon S3の豊富なエコシステムと連携でき、データ分析やアーカイブなど多様なビジネスシナリオを実現します。
- 低コストの長期保存:データベースと比較して、Amazon S3は高可用性かつ信頼性の高いコスト効率の良いオブジェクトストレージサービスであり、長期保存に適しています。
これらの特徴により、効率的で信頼性が高くスケーラブルなIoTアプリケーションの構築と、ビジネスの意思決定や最適化に役立ちます。
はじめる前に
このセクションでは、EMQXでAmazon S3 Sinkを作成する前の準備について説明します。
前提条件
以下の内容に慣れていることを確認してください:
EMQXの概念:
AWSの概念:
AWS S3が初めての場合、以下の概念を確認してください:
- EC2:AWSの仮想マシンサービス(コンピュートインスタンス)。
- IAM:AWS Identity and Access Management。インスタンスロールはそのインスタンス上で動作するプログラムに一時的な認証情報を発行可能。
- IMDSv2:EC2のInstance Metadata Service v2。トークンベースでより安全にメタデータや一時認証情報を取得する仕組み。
EMQX の概念:
EMQXはAmazon S3およびその他のS3互換ストレージサービスをサポートしています。AWSクラウドサービスを利用するか、DockerでMinIOインスタンスをデプロイできます。
コネクターの作成
S3 Sink を追加する前に、対応するコネクターを作成する必要があります。
ダッシュボードのIntegration -> Connectorページに移動します。
右上のCreateボタンをクリックします。
コネクタータイプとしてAmazon S3を選択し、Nextをクリックします。
コネクター名を入力します。名前は英数字で始まり、英数字、ハイフン、アンダースコアを含めることができます。例として
my-s3を入力します。接続情報を入力します。
- Amazon S3バケットを使用する場合、以下を入力します:
Host:リージョンによって異なり、
s3.{region}.amazonaws.comの形式です。Port:
443を入力します。Access Key IDとSecret Access Key:
- AWSで作成したアクセスキーを入力するか、
- EC2上でIAMロールをアタッチしている場合は空欄のままにします。
詳細はPrepare an S3 Bucketの「Amazon S3」タブを参照してください。
- MinIOを使用する場合、以下を入力します:
- Host:
127.0.0.1を入力。リモートでMinIOを実行している場合は実際のホストアドレスを入力します。 - Port:
9000を入力します。 - Access Key IDとSecret Access Key:MinIOで作成したアクセスキーを入力します。
- Host:
- Amazon S3バケットを使用する場合、以下を入力します:
残りの設定はデフォルト値のままにします。
Createをクリックする前に、Test ConnectivityをクリックしてコネクターがS3サービスに接続できるかテスト可能です。
下部のCreateボタンをクリックしてコネクター作成を完了します。
これでコネクター作成が完了し、次にS3サービスに書き込むデータを指定するルールとSinkの作成に進みます。
- 画面下部のCreateボタンをクリックしてコネクター作成を完了します。
このセクションでは、EMQXでソースMQTTトピックt/#からのメッセージを処理し、処理結果をS3のiot-dataバケットに書き込むルールの作成方法を示します。
ダッシュボードのIntegration -> Rulesページに移動します。
右上のCreateボタンをクリックします。
ルールIDに
my_ruleを入力し、SQLエディターに以下のルールSQLを入力します:sqlSELECT * FROM "t/#"TIP
SQLが初めての場合は、SQL ExamplesやEnable DebugをクリックしてルールSQLの学習や結果のテストが可能です。
アクションを追加し、Action Typeドロップダウンから
Amazon S3を選択します。アクションのドロップダウンはデフォルトのcreate actionのままにするか、既存のAmazon S3アクションを選択します。ここでは新しいSinkを作成し、ルールに追加します。Sink の名前と説明を入力します。
コネクタードロップダウンから先ほど作成した
my-s3を選択します。ドロップダウン横の作成ボタンをクリックするとポップアップで新規コネクター作成も可能です。必要な設定パラメータはCreate a Connectorを参照してください。Bucketに
iot-dataを入力します。このフィールドは${var}形式のプレースホルダーもサポートしますが、対応するバケットが事前にS3に作成されている必要があります。必要に応じて ACL を選択し、アップロードされるオブジェクトのアクセス権限を指定します。
Upload Methodを選択します。2つの方法の違いは以下の通りです。
- Direct Upload:ルールがトリガーされるたびに、設定済みのオブジェクトキーと内容に従ってデータを直接S3にアップロードします。バイナリや大きなテキストデータの保存に適していますが、多数のファイルが生成される可能性があります。
- Aggregated Upload:複数回のルールトリガー結果を単一ファイル(例:CSVファイル)にまとめてS3にアップロードします。構造化データの保存に適し、ファイル数を減らし書き込み効率を向上させます。
選択した方法により設定パラメータが異なります。以下のタブから該当する方法の設定を行ってください:
Object Contentを設定します。デフォルトはすべてのフィールドを含むJSONテキスト形式で、
${var}形式のプレースホルダーをサポートします。ここでは${payload}を入力し、メッセージ本文をオブジェクト内容として使用します。この場合、オブジェクトの保存形式はメッセージ本文の形式に依存し、圧縮ファイルや画像、その他バイナリ形式もサポートします。フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義可能です。これらはメインのSinkがメッセージ処理に失敗した場合にトリガーされます。詳細はフォールバックアクションを参照してください。
詳細設定を展開し、必要に応じて高度な設定オプションを構成します(任意)。詳細は高度な設定を参照してください。
残りの設定はデフォルト値のままにし、CreateボタンをクリックしてSink作成を完了します。作成成功後はルール作成画面に戻り、新しいSinkがルールのアクションに追加されます。
ルール作成画面に戻り、Createボタンをクリックしてルール作成全体を完了します。
これでルールの作成が完了しました。Rulesページで新規作成したルールを確認でき、**Actions (Sink)**タブで新しいS3 Sinkも確認可能です。
また、Integration -> Flow Designerをクリックするとトポロジーが表示されます。トポロジーは、トピックt/#のメッセージがルールmy_ruleで解析されてS3に書き込まれる流れを視覚的に示します。
ルールのテスト
このセクションでは、Direct Upload方式で設定したルールのテスト方法を示します。
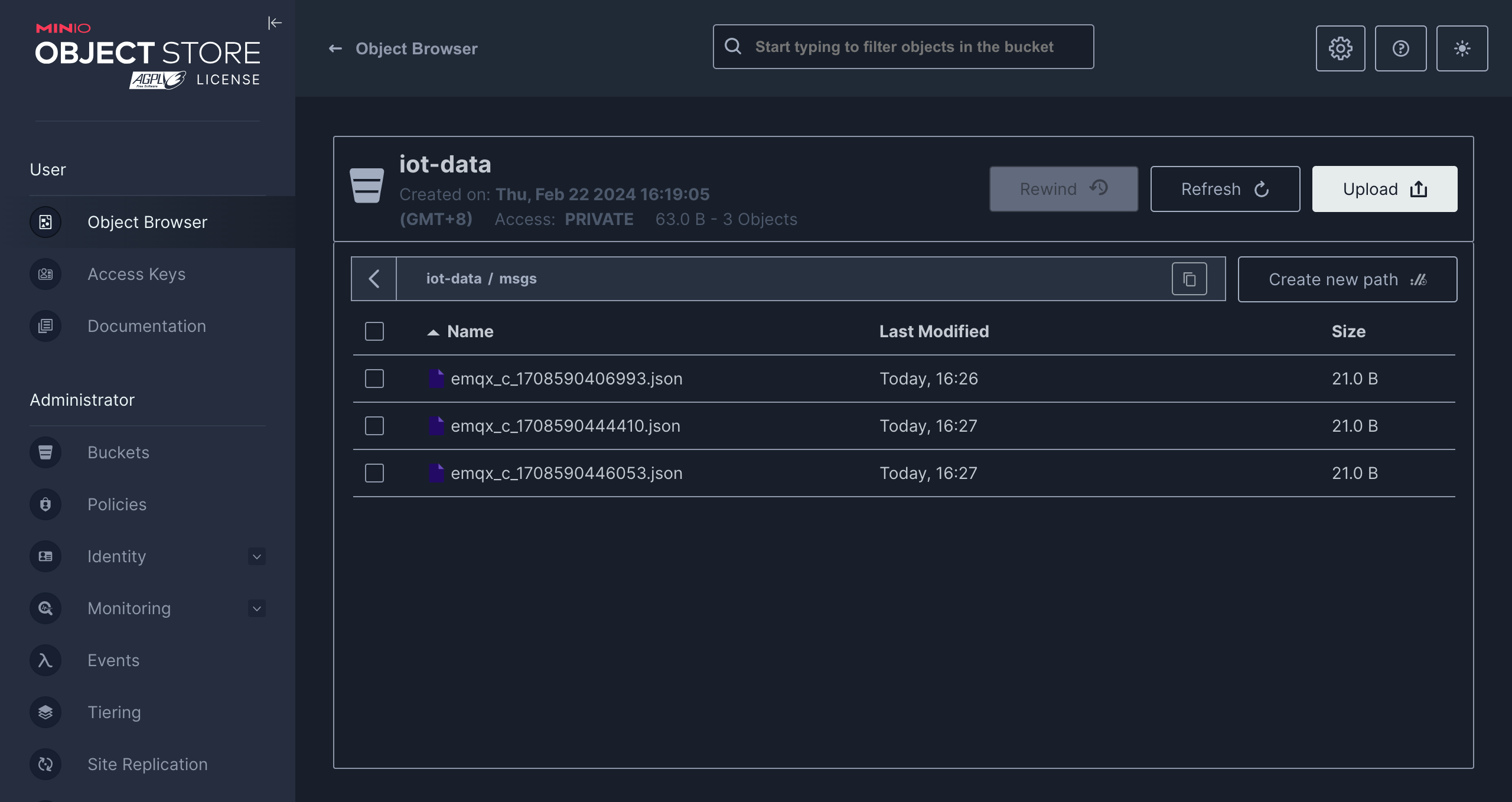
MQTTXを使い、トピックt/1にメッセージをパブリッシュします:
mqttx pub -i emqx_c -t t/1 -m '{ "msg": "hello S3" }'数件メッセージを送信後、MinIOコンソールまたはAmazon S3コンソールで結果を確認します。
高度な設定
このセクションでは、S3 Sinkの詳細設定オプションについて説明します。ダッシュボードでSinkを設定する際にAdvanced Settingsを展開し、必要に応じて以下のパラメータを調整できます。
| 項目名 | 説明 | デフォルト値 |
|---|---|---|
| Buffer Pool Size | EMQXとS3間のデータフローを管理するバッファワーカープロセスの数を指定します。これらのワーカーはデータを一時的に保持・処理し、ターゲットサービスへの送信を最適化しスムーズなデータ転送を実現します。 | 16 |
| Request TTL | 「Request TTL(Time To Live)」は、リクエストがバッファに入ってから有効とみなされる最大秒数を指定します。バッファに入った瞬間からカウントが始まり、このTTLを超えてバッファに滞留するか、S3からの応答やアックがタイムリーに得られない場合、リクエストは期限切れとみなされます。 | 45 |
| Health Check Interval | SinkがS3との接続状態を自動的にヘルスチェックする間隔(秒)を指定します。 | 15秒 |
| Health Check Interval Jitter | ベースのヘルスチェック間隔に加える一様ランダム遅延です。複数ノードが同時にヘルスチェックを開始する確率を減らします。複数のアクションやソースが同じコネクターを共有する場合、ジッターを有効にするとヘルスチェックがずれて実行されます。 | 0ミリ秒 |
| Health Check Timeout | コネクターがS3テーブルとの接続状態を自動ヘルスチェックする際のタイムアウト時間を指定します。 | 60秒 |
| Max Buffer Queue Size | S3 Sinkの各バッファワーカーがバッファリング可能な最大バイト数を指定します。バッファワーカーはデータを一時的に保持し、S3への送信を効率化する仲介役です。システム性能やデータ転送要件に応じて調整してください。 | 256MB |
| Query Mode | メッセージ送信の最適化のため、synchronous(同期)またはasynchronous(非同期)のリクエストモードを選択可能です。非同期モードではS3への書き込みがMQTTメッセージのパブリッシュ処理をブロックしませんが、クライアントがメッセージ到達前に受信する可能性があります。 | Asynchronous |
| In-flight Window | 「In-flightキューリクエスト」とは、送信済みだがまだ応答やアックを受け取っていないリクエストを指します。この設定はSinkとS3間の通信で同時に存在可能なin-flightリクエストの最大数を制御します。Request Modeがasynchronousの場合、このパラメータは特に重要です。同一MQTTクライアントからのメッセージを厳密に順序処理したい場合は1に設定してください。 | 100 |
| Min Part Size | 集約完了後のパートアップロードの最小チャンクサイズです。アップロード対象のデータはこのサイズに達するまでメモリに蓄積されます。 | 5MB |
| Max Part Size | パートアップロードの最大チャンクサイズです。S3 Sinkはこのサイズを超えるパートのアップロードを試みません。 | 5GB |