EMQXクラスタリングの設計
MQTTはステートフルなプロトコルであり、ブローカーは各MQTTセッションの状態情報(サブスクライブされたトピックや未完了のメッセージ送信など)を保持する必要があります。MQTTブローカーのクラスタリングにおける主な課題の一つは、これらの状態をすべてのクラスタノード間で効率的かつ信頼性高く同期・複製することです。
EMQXは高いスケーラビリティとフォールトトレランスを備えたMQTTブローカーであり、複数ノードによるクラスタモードで動作可能です。EMQXのクラスタリングは、IoTメッセージングシステムのスケーラビリティ、可用性、信頼性、管理性を向上させるため、大規模またはミッションクリティカルなアプリケーションに推奨される手法です。本ページでは、MQTTブローカーのクラスタリングの必要性とEMQXがどのようにそれを実現しているかを解説し、単一クラスタ内で数百万のユニークなワイルドカードサブスクライバーをサポートする方法を説明します。
EMQXクラスタの作成および運用に関する詳細な手順は、EMQXクラスタをご参照ください。
クラスタリングの重要な側面
クラスタ設計において考慮すべき重要な側面はいくつかあります。これらはクラスタの成功を左右する最も重要な要素であることが多いです。以下に簡単にまとめます。
集中管理:クラスタ内のすべてのノードは単一の管理コンソールから監視・制御可能であるべきです。
データ整合性:クラスタ内のすべてのノードがルーティング情報の一貫したビューを持つことを保証します。これはデータをクラスタ内のすべてのノードに複製することで実現されます。
スケールの容易さ:クラスタ管理の複雑さを減らすために、新しいノードの追加は複雑であってはなりません。クラスタは新規ノードを自動検出し、クラスタに追加できるべきです。
クラスタのリバランス:最小限の運用オーバーヘッドで、各ノードの負荷の不均衡を検知し、負荷の少ないノードにワークロードを再割り当てできるべきです。これにより、1つ以上のノードが故障してもクラスタは継続稼働可能です。
大規模クラスタサイズ:システムの増大する要求に応じて、より多くのノードを追加してクラスタを拡張可能であるべきです。これによりクラスタは水平スケール可能となります。
自動フェイルオーバー:ノードが故障した場合、クラスタは自動的に故障を検知し、残りのノードにワークロードを再割り当てします。これにより、1つ以上のノードが故障してもクラスタは継続稼働可能です。
ネットワークパーティション耐性:クラスタはネットワークパーティションを耐えられるべきであり、1つ以上のノードが故障しても継続稼働可能です。
EMQXはこれらの目標を最も効率的に達成するために様々な手法を用いています。以下のセクションでクラスタリングの主要な側面について詳述します。
データ複製チャネル
メタデータおよびメッセージ複製を実現するために、Erlang分散プロトコルとカスタム分散プロトコルがブローカー間のリモートプロシージャコールに利用されています。EMQXクラスタには2つのデータ複製チャネルがあります。
メタデータ複製:どのノードがどの(ワイルドカード)トピックをサブスクライブしているかといったルーティング情報の複製です。このチャネルは「Erlang分散」プロトコルにより動作し、各ノードはクライアントおよびサーバの両方として機能します。このプロトコルのデフォルトリッスンポートは4370です。
メッセージ配信:ノード間でメッセージを転送する際に利用されます。メッセージ配信チャネルはコネクションプールを用い、各ノードはデフォルトでポート5370(Dockerコンテナ内では5369)で待ち受けます。これはErlang分散プロトコルの単一コネクション利用とは異なります。
下図はパブリッシュ・サブスクライブのフローにおける2つのデータ複製チャネルを示しています。ノード間の破線はメタデータ複製を、実線矢印はメッセージ配信チャネルを表します。
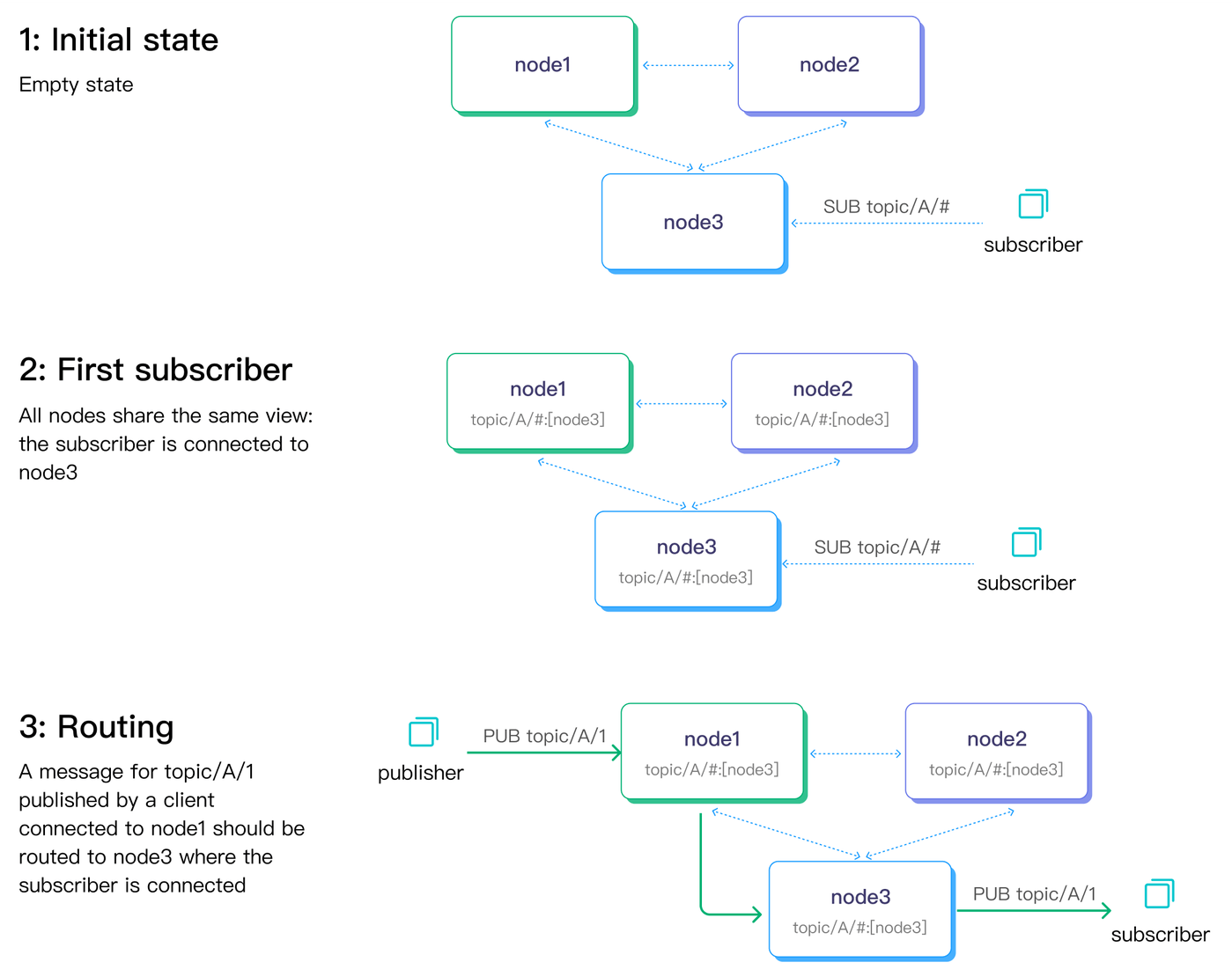
組み込みデータベース
EMQXは内部データを2種類の組み込みデータベース管理システムのいずれかに格納します。
Mria:軽量なインメモリデータベースで、ルーティングテーブルやランタイム設定など読み込みが多いワークロードに使用されます。CAP定理の観点では可用性を重視した設計です。
Durable Storage (DS):ディスクベースのストリーミングデータベースで、永続化セッションやメッセージキューなど書き込みが多く大量のデータを扱うワークロードに使用されます。整合性を重視した設計です。
これら2つのDBMSは特性が大きく異なり、ネットワークパーティション時の保証も異なります。本ドキュメントでは主にMriaとEMQXの動作に焦点を当て、永続化機能の詳細は扱いません。永続化ストレージに関する情報はDurable Storageをご参照ください。
Mriaテーブルはさらに2種類に分類されます。
Regular:テーブルの内容がグローバルに一様であるもの。Mriaテーブルの大半はこちらです。
Merge:各レコードが特定のEMQXノードに属し、そのノードのみが変更可能で、他ノードからは読み取り専用に見える特殊なテーブルです。
ノードの役割:CoreとReplicant
Mriaはcoreとreplicantの2種類のノード役割を持つ混合ネットワークトポロジーを採用しています。
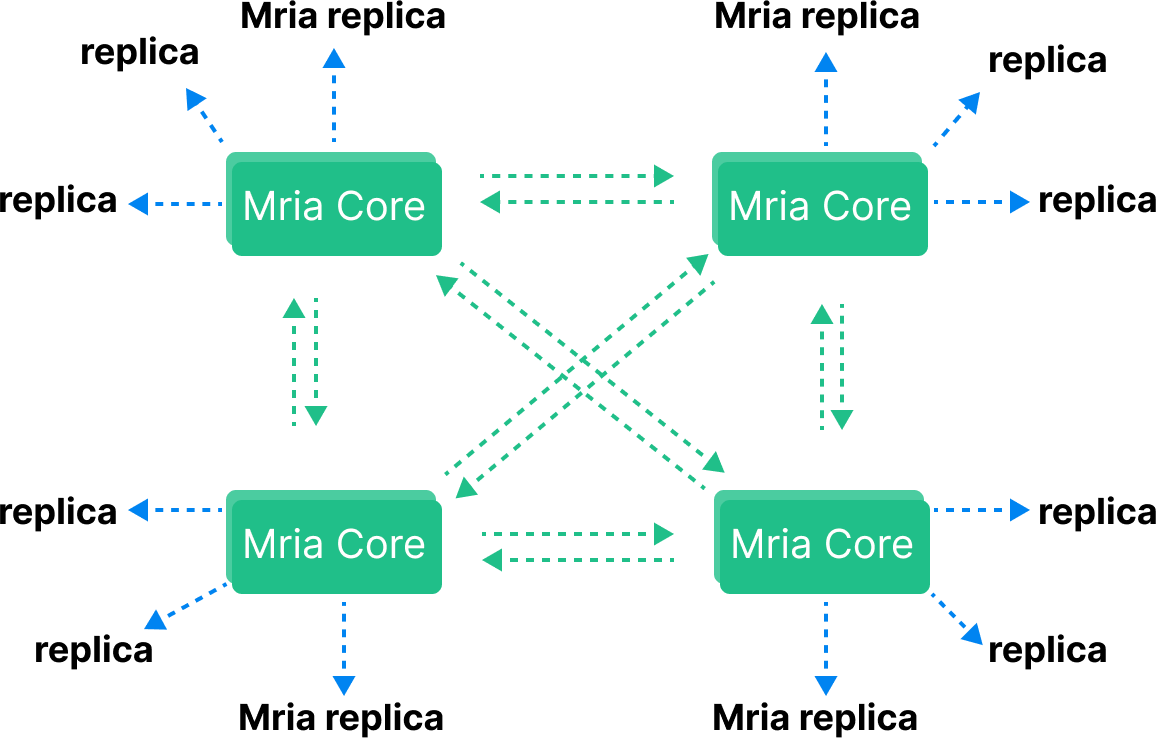
各EMQXクラスタは最低1つのCoreノードと任意数のReplicantノードで構成されます。
CoreノードはMriaの中核であり、regularテーブルの更新を調整します。これらのテーブルへの更新はCoreノードクラスタ間で同期的に複製されます。調整コストが高いため、Coreノードはデータ冗長性要件を満たす最小限の数に抑え、残りはReplicant役割を割り当てることが推奨されます。典型的なCoreノード数は3台です。
Replicantノードはトランザクション処理に直接関与せず、Coreノードに接続してデータ更新を受動的に複製します。Replicantは書き込み操作を行えず、書き込み要求はCoreノードに転送されます。ReplicantはCoreノードからデータを複製するため、ローカルに完全なデータコピーを保持し、読み取り操作のレイテンシ低減に寄与します。
Replicantは書き込みに参加しないため、Replicantノード数が増えても書き込みレイテンシは影響を受けません。これにより数十台のReplicantノードを持つ大規模クラスタの構築が可能です。
パフォーマンス向上のため、データ複製は独立したデータストリームに分割されます。複数の関連テーブルは同一のRLOGシャード(複製ログシャード)に割り当てられ、トランザクションはCoreノードからReplicantノードへ順次複製されます。異なるRLOGシャードは独立しています。
Mergeテーブル
Mergeテーブルは、各レコードが特定のEMQXノードに明確に紐づく特殊なMriaテーブルです。代表例がEMQXのルーティングテーブルです。ルーティングテーブルはMQTTブローカーにおける最重要分散データ構造であり、すべてのトピックのルーティング情報を格納し、特定トピックにパブリッシュされたメッセージをどのノードに送るかを決定します。
通常のテーブルとは異なり、すべてのEMQXノード(Core・Replicant問わず)は自身のレコードを直接更新し、他ノードとの調整は行いません。その後、更新は非同期にクラスタ内へ複製されます。各ノードはMergeテーブルにおいてCoreとReplicantの両方の役割を果たします。
この設計の利点は以下の通りです。
- 書き込みレイテンシの低減
- Coreノードの負荷軽減
- パーティション耐性の向上:完全に分断されたネットワークでも各ノードは自身のルートを保持可能
ネットワークパーティションが回復すると、ノードはルーティングテーブルの内容をマージします。これが名称の由来です。
集中管理
EMQXはクラスタ内のすべてのノードを単一の管理コンソールから監視・制御可能であり、大量のデバイスやメッセージの管理を容易にします。コンソールはWebブラウザからアクセス可能で、ユーザーフレンドリーなインターフェースを提供します。任意のcoreタイプノードが管理用HTTP APIのエンドポイントを担います。
オンライン設定管理機能により、ノードの再起動なしにクラスタ内すべてのノードの設定変更が可能です。これはノードの追加・削除などクラスタ設定の更新に特に有用です。
スケールの容易さ
EMQXは水平スケールを容易に設計されています。CLI、API、またはダッシュボードからいつでもクラスタにノードを追加・削除できます。
例えば、新しいノードをクラスタに追加するには以下のようなコマンドを実行するだけです。
emqx ctl cluster join emqx@node1.my.netここでemqx@node1.my.netはクラスタ内の既存ノードの一つです。
またダッシュボードからボタン操作で新規ノードのクラスタ参加を招待することも可能です。
豊富な管理インターフェースを活用すれば、クラスタ管理のスクリプト化やDevOpsパイプラインへの組み込みも容易です。
EMQX v5ではreplicaノードはステートレス設計となっており、オートスケーリンググループに配置してより良いDevOps運用が可能です。
クラスタのリバランス
新規ノードがクラスタに参加すると、初期状態は空の状態です。優れたロードバランサーがあれば、新規接続クライアントは新ノードに接続しやすくなりますが、既存クライアントは旧ノードに接続し続けます。
クライアントが短期間で再接続すればクラスタは早期にバランスを取れますが、再接続しない場合は長期間アンバランスな状態が続く可能性があります。
この問題に対処するため、EMQX(バージョン4.4以降)は「クラスタロードリバランシング」機能を導入しました。この機能により、過負荷ノードから負荷の低いノードへセッションを自動的に移行し、クラスタの負荷をリバランスできます。
「リバランス」の極端な例が「エバキュエーション(避難)」であり、特定ノードからすべてのセッションを移行します。これはノードをクラスタから除去したい場合に有用です。
クラスタサイズ
数百万の同時接続を扱うスケールでは、単一マシンでの処理は不可能であり、水平スケールが必須です。
EMQX v5のcore-replicaクラスタリングアーキテクチャにより、より大規模なクラスタスケールが可能となりました。
ベンチマークでは、23ノードクラスタで5,000万のパブリッシャーと5,000万のワイルドカードサブスクライバーをテストしました。詳細はブログ記事をご覧ください。
なぜワイルドカードかというと、ワイルドカードサブスクライブはMQTTブローカークラスタのスケーラビリティを評価するゴールドスタンダードであり、基盤となるデータ構造とアルゴリズムを最大限に試すためです。
自動フェイルオーバー
MQTTプロトコル仕様にはセッションアフィニティの概念がありません。つまり、クライアントはクラスタ内の任意のノードに接続しても、サブスクライブしたトピックのメッセージを受信可能です。またMQTTにはサービスディスカバリ機構がないため、クライアントはクラスタノードのアドレスを知っている必要があります。通常、クライアントはクラスタ内のすべてのノードのリスト、またはより良い方法として適切なノードへルーティングできるロードバランサーを設定します。
EMQXはクラスタ前段にロードバランサーを配置する設計です。ヘルスチェックエンドポイントにより、ロードバランサーはクラスタノードの健全性を検知し、クライアントを適切なノードへルーティングします。
Erlangのノード監視機構を利用し、EMQXノードは互いの健全性を監視し、不健全なノードを自動的にクラスタから除外します。
ネットワークパーティション耐性
ネットワークパーティションが発生すると、クラスタは複数の孤立したサブクラスタに分割され、それぞれが唯一のアクティブクラスタと誤認する「スプリットブレイン」問題が起こります。実運用クラスタはネットワークパーティションから自動復旧可能であるべきです。
EMQXの「autoheal」機能はネットワークパーティション後のクラスタを自動的に修復します。有効化されている場合、パーティション発生後の復旧時にクラスタ内ノードは以下の手順で修復を行います。
復旧処理はCoreノードとReplicantノードで異なります。
Coreノードの復旧
- ノードは最もアップタイムの長いリーダーノードにパーティション情報を報告します。
- リーダーノードはグローバルなネットワーク分割ビューを作成し、多数派のCoreノードの1つをコーディネーターに選出します。
- リーダーノードはコーディネーターに少数派のCoreノードに再起動を指示するよう依頼します。
- 少数派のCoreノードはMriaテーブルの内容を多数派の内容に置き換えます。
Replicantノードの復旧
Replicantノードはネットワークパーティション修復時に再起動されません。これによりクライアント接続を維持します。
代わりに以下の処理を行います。
- 少数派パーティションのReplicantはregular Mriaテーブルのレプリカを再初期化します。
- ルーティングテーブルの内容をマージし、多数派パーティションのノードは少数派へのルートを再確立し、その逆も行います。
- クライアントはグローバルセッションレジストリへのプレゼンスを再確立します。
パーティション復旧時に生成されるログメッセージやアラームについてはMrIaログとアラームをご参照ください。
まとめ
本記事ではEMQXの新しいクラスタリングアーキテクチャを紹介しました。また、スケーラビリティ、自動フェイルオーバー、ネットワークパーティション耐性など、実運用に耐えるMQTTブローカークラスタの重要な側面と、EMQXがそれらの目標達成にどのように寄与するかを解説しました。