Amazon S3 TablesへのMQTTデータ取り込み
Amazon S3 Tablesは、分析ワークロードに最適化された専用のストレージソリューションです。IoTセンサーの計測値などの表形式データをApache Icebergフォーマットで高性能かつスケーラブル、かつ安全に保存できます。
EMQXはAmazon S3 Tablesとのシームレスな連携をサポートし、MQTTメッセージを効率的にS3テーブルバケットに格納できます。この連携により、柔軟でスケーラブルなIoTデータストレージが可能となり、Amazon Athena、Amazon Redshift、Amazon EMRなどのAWSサービスを活用した高度な分析や処理が容易になります。
本ページでは、EMQXとAmazon S3 Tables間のデータ統合について詳しく解説し、ルールおよびSinkの作成方法について実践的なガイダンスを提供します。
動作の仕組み
EMQXのAmazon S3 Tables連携は標準搭載機能です。この連携はEMQXのルールエンジンとS3 Tables Sinkを活用し、MQTTメッセージを変換してApache Iceberg形式のテーブルに直接ストリーミングし、S3テーブルバケットに保存して長期保管および下流分析を実現します。
典型的なIoTシナリオでは以下のように動作します:
- EMQXはMQTTブローカーとして機器の接続管理、メッセージルーティング、データ処理を担当します。
- Amazon S3 TablesはMQTTメッセージデータを表形式で耐久的かつクエリ可能なストレージとして提供します。
- Amazon AthenaはIcebergテーブルの定義や格納データに対するSQLクエリの実行に使用されます。
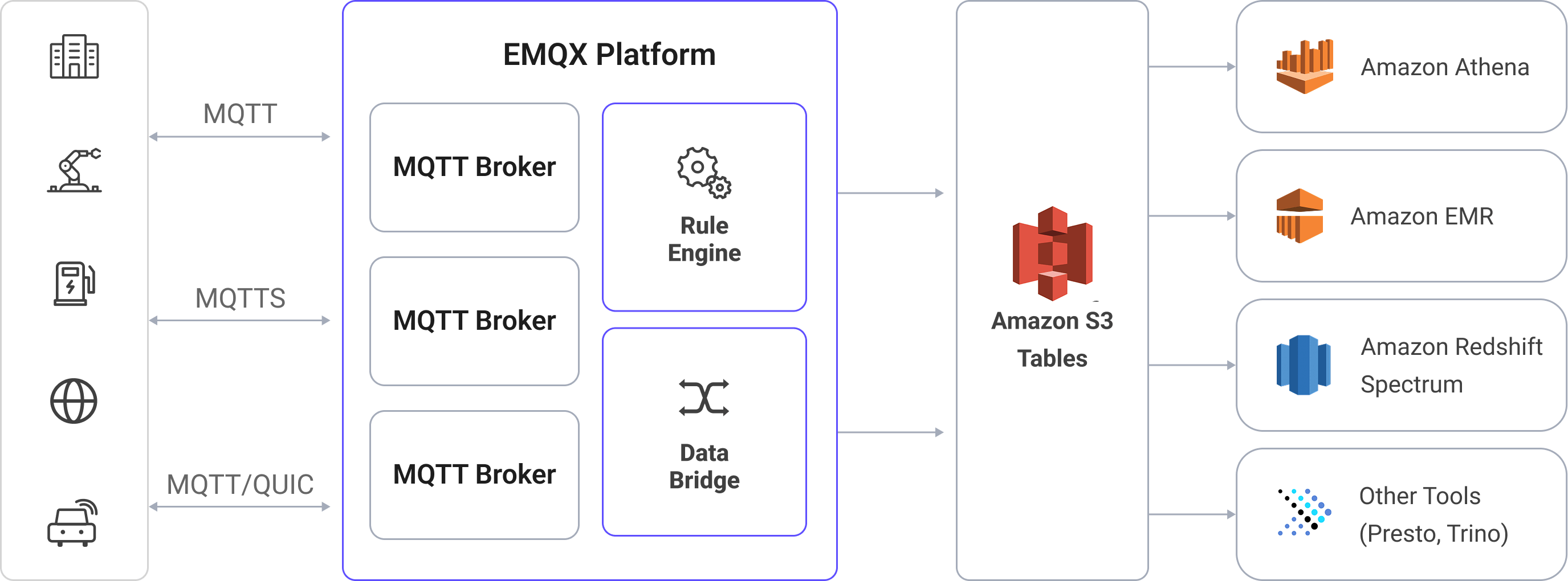
ワークフローは以下の通りです:
- デバイスのEMQX接続:IoTデバイスがMQTTでEMQXに接続し、テレメトリデータをパブリッシュします。
- メッセージルーティングとルールマッチング:EMQXのルールエンジンが受信したMQTTメッセージを定義済みトピックに照合し、特定のフィールドや値を抽出します。
- データ変換:EMQXのルールでペイロードのフィルタリング、変換、付加処理を行い、ターゲットのIcebergテーブルのスキーマに合わせます。
- Amazon S3 Tablesへの書き込み:ルールがS3 Tables Sinkアクションをトリガーし、変換済みデータをバッチ処理してIceberg互換の書き込みAPIでS3 Tablesに送信します。データはIcebergテーブルのパーティション下にParquetファイルとして永続化されます。
- クエリと分析:取り込まれたデータはAmazon Athenaでクエリ可能となり、他のデータセットと結合したり、Redshift Spectrum、Amazon EMR、PrestoやTrinoなどのサードパーティ分析エンジンで分析できます。
特長とメリット
EMQXのAmazon S3 Tablesデータ統合を利用することで、以下の特長と利点を得られます:
- リアルタイムストリーム処理:EMQXのルールエンジンにより、MQTTメッセージをリアルタイムに抽出・変換・条件付きルーティングしてS3 Tablesに届けられます。
- IcebergベースのS3ストレージ:メッセージはApache Icebergテーブルに書き込まれ、従来のデータベース不要でSQLライクなアクセスが可能です。
- 分析ツールとの簡単連携:S3 Tablesに格納後はAmazon Athena(SQL)、Amazon EMR、Redshift Spectrum、Presto、Trino、Snowflakeなどでクエリや分析が行えます。
- 柔軟かつコスト効率の高いストレージ:Amazon S3は高耐久かつ低コストのオブジェクトストレージを提供し、アーカイブ、コンプライアンス、時系列分析に最適です。
はじめる前に
このセクションでは、EMQXでAmazon S3 Tables Sinkを作成するための準備について説明します。
前提条件
以下の内容に慣れていることを推奨します:
EMQXの概念:
AWSの概念:
AWS S3 Tablesが初めての場合は以下の用語を確認してください:
- EC2:AWSの仮想マシンサービス(コンピュートインスタンス)。
- IAM:AWS Identity and Access Management。インスタンスロールはそのインスタンス上で動作するプログラムに一時的な認証情報を発行可能。
- IMDSv2:EC2のインスタンスメタデータサービスv2。トークンベースでより安全にメタデータや一時認証情報を取得。
- Table Bucket:S3 TablesでIcebergベースのテーブルデータとメタデータを保存する専用のS3バケット。
- Amazon Athena:Amazon S3に保存されたデータに対して直接SQLクエリを実行できるサーバーレスクエリエンジン。DDLステートメント(
CREATE TABLEなど)を使ってスキーマや構造を定義可能。 - Catalog:Athenaのメタデータコンテナで、データベース(ネームスペース)やテーブルを管理。
- Database (Namespace):Catalog内の論理的なテーブルグループ。
- Iceberg Table:高性能でトランザクショナルなデータレイク向けテーブルフォーマット。スキーマ進化、パーティションプルーニング、タイムトラベルクエリをサポート。
デプロイ前提条件と認証情報の取得方法
S3 Tablesコネクターは認証情報を取得する方法が2通りあります。EMQXのデプロイ環境に応じて選択してください:
オプション1:アクセスキーを手動設定 コネクター作成時にAccess Key IDとSecret Access Keyを入力します。これらの認証情報は対象のS3 TablesおよびAthenaへの必要な権限を持つ必要があります。ローカル環境、コンテナ、Kubernetes、非AWSクラウド、またはインスタンスロールが割り当てられていないEC2で適用可能です。
IAMユーザーのアクセスキーの作成・管理についてはAWSのアクセスキー管理ドキュメントを参照してください。
オプション2:一時認証情報を自動取得(EC2のみ) EMQXがAWS EC2インスタンス上で動作し、かつそのインスタンスに必要な権限を持つIAMロールが割り当てられている場合、コネクター作成時にAccess Key IDとSecret Access Keyを空欄にできます。EMQXはIMDSv2 APIを使い、そのロールに紐づく一時認証情報を取得します。
EC2インスタンスにIAMロールを割り当てる方法はAWSのEC2用IAMロールドキュメントを参照してください。
注意事項
- インスタンスロールには対象のS3 Tables(バケット/テーブル)およびAthenaへの十分な権限が必要です。権限不足の場合、Test Connectivityが失敗します。
- 一時認証情報の管理にはEC2インスタンスに割り当てたIAMロールの利用を推奨します。EC2以外の環境やロール未割り当ての場合はオプション1でアクセスキーを手動設定してください。
S3 Tablesバケットの準備
EMQXでSinkを作成する前に、AWS S3 TablesのMQTTデータ受け入れ先を準備する必要があります。以下を用意してください:
- 実際のデータファイルを格納するTable Bucket
- 関連テーブルを論理的にグループ化するNamespace
- 構造化されたMQTTデータを受け取るIcebergベースのテーブル
AWSマネジメントコンソールにログインします。
S3サービスに移動し、左のナビゲーションペインでTable bucketsをクリックします。
Create table bucketをクリックし、テーブルバケット名(例:
mybucket)を入力してCreate table bucketをクリックします。バケット作成後、クリックしてテーブル一覧に移動します。
Create table with Athenaをクリックすると、Namespaceの入力を求めるポップアップが表示されます。
Create a namespaceを選択し、Namespace名を入力して作成を確定します。
Namespace作成後、再度Create table with Athenaをクリックします。
Icebergテーブルのスキーマを定義します:
Query table with Athenaをクリックし、Query editorで以下を設定します:
- Catalogセレクターから、作成したバケット名に対応するCatalog(例:
s3tablescatalog/mybucket)を選択。 - Databaseセレクターから先ほど作成したNamespaceを選択。
- Catalogセレクターから、作成したバケット名に対応するCatalog(例:
以下のDDLを実行し、テーブルタイプが
ICEBERGであることを確認してテーブルを作成します。例:sqlCREATE TABLE testtable ( c_str string, c_long int ) TBLPROPERTIES ('table_type' = 'ICEBERG');これはEMQXからの構造化MQTTデータを格納するIcebergテーブルを定義します。
テーブルが正常に作成されて空であることを確認するため、以下のクエリを実行します:
sqlselect * from testtableTIP
AthenaでSQLを実行する前に、正しいCatalogおよびDatabase(Namespace)が選択されていることを必ず確認してください。これにより、意図したS3 Table Bucket内にテーブルが作成されます。
コネクターの作成
S3 Tables Sinkを追加する前に、対応するコネクターを作成します。
ダッシュボードのIntegration -> Connectorページに移動します。
右上のCreateボタンをクリックします。
コネクタータイプとしてS3 Tablesを選択し、次へ進みます。
コネクター名を入力します。名前は英数字で始まり、英数字、ハイフン、アンダースコアを含めることができます。この例では
my-s3-tablesと入力します。必要な接続情報を入力します:
- S3Tables ARN:S3 Table BucketのAmazonリソースネーム(ARN)を入力します。AWSコンソールのTable bucketsセクションで確認可能です。
- Access Key ID と Secret Access Key(任意):
- 手動設定の場合:S3 TablesとAthenaにアクセス権限を持つIAMユーザーまたはロールの認証情報を入力します。
- 自動取得の場合:EMQXがAWS EC2インスタンス上で動作し、必要な権限を持つIAMロールが割り当てられている場合は空欄のままにします。EMQXがIMDSv2経由で一時認証情報を取得します。詳細はデプロイ前提条件と認証情報の取得方法を参照してください。
- Enable TLS:S3 Tables接続時はTLSがデフォルトで有効です。TLS接続オプションの詳細はTLSによる外部リソースアクセスを参照してください。
- Health Check Timeout:コネクターがS3 Tablesとの接続状態を自動でヘルスチェックする際のタイムアウト時間を指定します。
その他の設定はデフォルト値を使用します。
Createをクリックする前に、Test Connectivityを押してS3 Tablesサービスへの接続確認を行えます。
最後にCreateボタンをクリックしてコネクター作成を完了します。
これでコネクター作成が完了し、次にルールとSinkを作成してS3 Tablesへのデータ書き込みを指定します。
Amazon S3 Tables Sinkを使ったルールの作成
このセクションでは、ソースMQTTトピックt/#からメッセージを処理し、処理結果をS3 Tablesのmybucketバケットに書き込むルール作成手順を示します。
ダッシュボードのIntegration -> Rulesページに移動します。
右上のCreateボタンをクリックします。
ルールIDに
my_ruleを入力し、SQLエディターに以下のルールSQLを入力します:sqlSELECT payload.str as c_str, payload.int as c_long FROM "t/#"TIP
SQLに不慣れな場合は、SQL ExamplesやEnable DebugをクリックしてルールSQLの学習や結果のテストが可能です。
TIP
出力フィールドがIcebergテーブルのスキーマと一致していることを必ず確認してください。必須カラムの欠落や誤った名前はデータのテーブルへの追加失敗を招きます。
アクションを追加し、Action Typeドロップダウンから
S3 Tablesを選択します。アクションドロップダウンはデフォルトのcreate actionのままにするか、既存のS3 Tablesアクションを選択します。ここでは新規Sinkを作成してルールに追加します。Sink名と任意の説明を入力します。
Connectorドロップダウンから先ほど作成した
my-s3-tablesコネクターを選択します。新規コネクターを素早く定義したい場合はドロップダウン横のCreateボタンをクリックしてください。設定パラメータはコネクターの作成を参照してください。Sink設定を行います:
- Namespace:テーブルが存在するNamespace。複数セグメントの場合はドット区切りで指定(例:
my.name.space)。 - Table:データを追加するIcebergテーブル名(例:
testtable)。 - Max Records:S3に書き込む前にバッチ処理する最大レコード数。到達すると即座にバッチをフラッシュしてアップロード。
- Time Interval:Max Recordsに達しなくても、指定した時間(ミリ秒)経過後にバッチをフラッシュ。
- Data File Format:S3に保存するバッチデータのファイル形式。サポート値:
avro:(デフォルト)行ベースのAvro形式。ストリーミングデータやスキーマ進化に適する。parquet:列指向のApache Parquet形式。大規模データの分析クエリに最適。
- Namespace:テーブルが存在するNamespace。複数セグメントの場合はドット区切りで指定(例:
フォールバックアクション(任意):メッセージ配信失敗時の信頼性向上のため、1つ以上のフォールバックアクションを定義可能です。詳細はフォールバックアクションを参照してください。
Advanced Settingsを展開し、必要に応じて詳細設定を行います(任意)。詳細は高度な設定を参照してください。
残りの設定はデフォルト値を使用し、CreateボタンをクリックしてSink作成を完了します。作成成功後、ルール作成画面に戻り、新規Sinkがルールアクションに追加されます。
ルール作成画面でCreateボタンをクリックし、ルール全体の作成を完了します。
これでルールの作成が完了しました。Rulesページで新規ルールを確認でき、**Actions (Sink)**タブで新しいS3 Tables Sinkを確認できます。
また、Integration -> Flow Designerを開くとトポロジーが視覚的に表示され、トピックt/#のメッセージがルールmy_ruleで解析されてS3 Tablesに書き込まれる流れが確認できます。
ルールのテスト
このセクションでは、S3 Tables Sinkを設定したルールのテスト方法を示します。
MQTTクライアントMQTTXを使い、トピック
t/1にメッセージをパブリッシュします:bashmqttx pub -i emqx_c -t t/1 -m '{ "str": "hello S3 Tables", "int": 123 }'このメッセージは
payload.strとpayload.intフィールドを含み、ルールSQLおよびテーブルスキーマと一致しています。RulesページでルールのメトリクスとSinkの状態を監視します。新規の受信メッセージと送信メッセージがそれぞれ1件ずつ増えているはずです。
Athenaのクエリエディターを開き、正しいCatalog(例:
s3tablescatalog/mybucket)とDatabase(Namespace)が選択されていることを確認します。以下のSQLを実行します:
sqlSELECT * FROM testtable以下のような行が表示されるはずです:
c_str c_long hello S3 Tables 123
高度な設定
このセクションでは、S3 Tables Sinkの高度な設定オプションについて説明します。ダッシュボードのSink設定画面でAdvanced Settingsを展開すると以下のパラメータを調整可能です。
| フィールド名 | 説明 | デフォルト値 |
|---|---|---|
| Min Part Size | マルチパートアップロードの最小パートサイズ。 このサイズに達するまでアップロードデータはメモリに蓄積されます。 | 5 MB |
| Max Part Size | マルチパートアップロードの最大パートサイズ。 このサイズを超えるパートはアップロードされません。 | 5 GB |
| Buffer Pool Size | バッファワーカーの数を指定します。EMQXとS3 Tables間のデータフローを管理し、一時的にデータを保持・処理します。パフォーマンス最適化とスムーズなデータ送信に重要です。 | 16 |
| Request TTL | リクエストの有効期限(秒)を指定します。リクエストがバッファに入ってからこの時間を超えるか、S3 Tablesから応答・アックが得られない場合、リクエストは期限切れとみなされます。 | 45 秒 |
| Health Check Interval | SinkがS3 Tablesとの接続状態を自動ヘルスチェックする間隔(秒)を指定します。 | 15 秒 |
| Health Check Interval Jitter | 複数ノードが同時にヘルスチェックを行うのを防ぐため、基本間隔に加える一様ランダム遅延(ミリ秒)です。複数のアクションやソースが同じコネクターを共有する場合に有効です。 | 0 ミリ秒 |
| Health Check Timeout | コネクターがS3 Tablesとの接続ヘルスチェックを行う際のタイムアウト時間を指定します。 | 60 秒 |
| Max Buffer Queue Size | S3 Tables Sinkの各バッファワーカーが一時的に保持できる最大バイト数を指定します。データ送信の効率化のためにバッファワーカーがデータを中継します。システム性能やデータ送信要件に応じて調整してください。 | 256 MB |
| Batch Size | EMQXからS3 Tablesへ一度に送信するデータバッチの最大レコード数を指定します。サイズ調整によりデータ転送の効率とパフォーマンスを最適化可能です。1に設定するとレコードを個別送信します。 | 1000 |
| Query Mode | synchronousまたはasynchronousのリクエストモードを選択し、メッセージ送信を最適化します。非同期モードではS3 Tablesへの書き込みがMQTTパブリッシュをブロックしませんが、クライアントがS3 Tables到達前にメッセージを受信する可能性があります。 | Asynchronous |
| In-flight Window | 送信済みだが応答・アック未受信のリクエスト数の最大値を指定します。asynchronousモード時に重要で、同一MQTTクライアントからのメッセージを厳密に順序処理したい場合は1に設定してください。 | 100 |