GPT-Realtime 概要
GPT-Realtime は、OpenAI が開発したマルチモーダルでリアルタイム対応のモデルであり、ライブの音声入力を受け取り、リアルタイムで音声出力を生成できます。大規模な音声データセットで学習されており、人間の自然な会話パターンに密接に沿うよう設計されています。
主な特徴は以下の通りです。
- プロトコル:WebRTC、WebSocket、SIP に対応。テキストおよび音声入力をリアルタイムで処理し、応答を継続的にストリーミングできます。
- 会話体験:低レイテンシ、自然で流暢な音声合成、会話中の複数の割り込みに強く、人間の対話に近い挙動を実現します。
- 関数呼び出しとツール:関数呼び出しおよび MCP ツールをサポートしています。
- 開発者体験:WebRTC 統合のために、2つのレベルの統合方法を提供しています。
- Voice Agents SDK:すぐに使える高レベルの抽象化機能を備えています。
- WebRTC SDK:より柔軟でカスタマイズ可能な低レベルの音声/映像トランスポートを提供します。
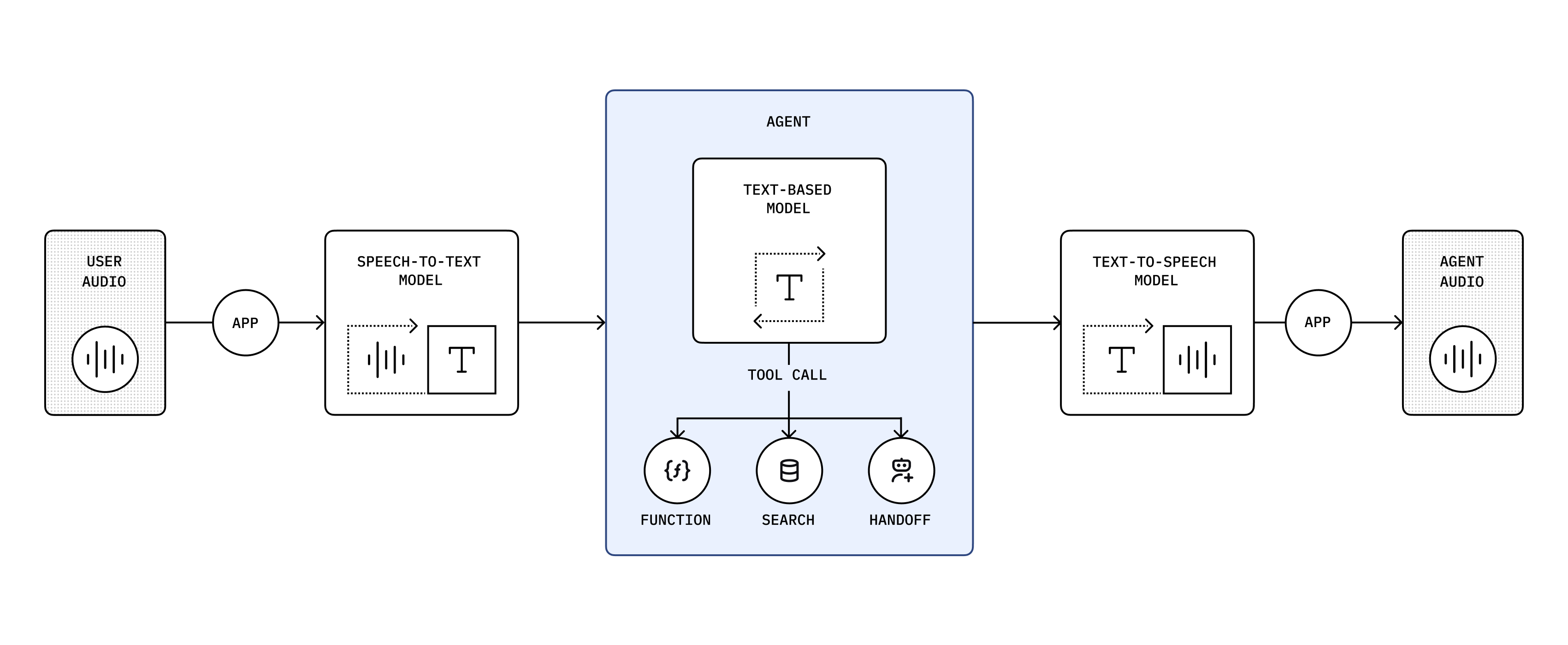
従来の RTC リアルタイム音声パイプライン(複数モデル連結)
従来の RTC リアルタイム音声ソリューションでは、音声対話を実現するために複数のモデルが連結されることが一般的です。音声はまずテキストに書き起こされ、その後大規模言語モデルで処理され、最後に音声合成されてユーザーにストリーミングされます。
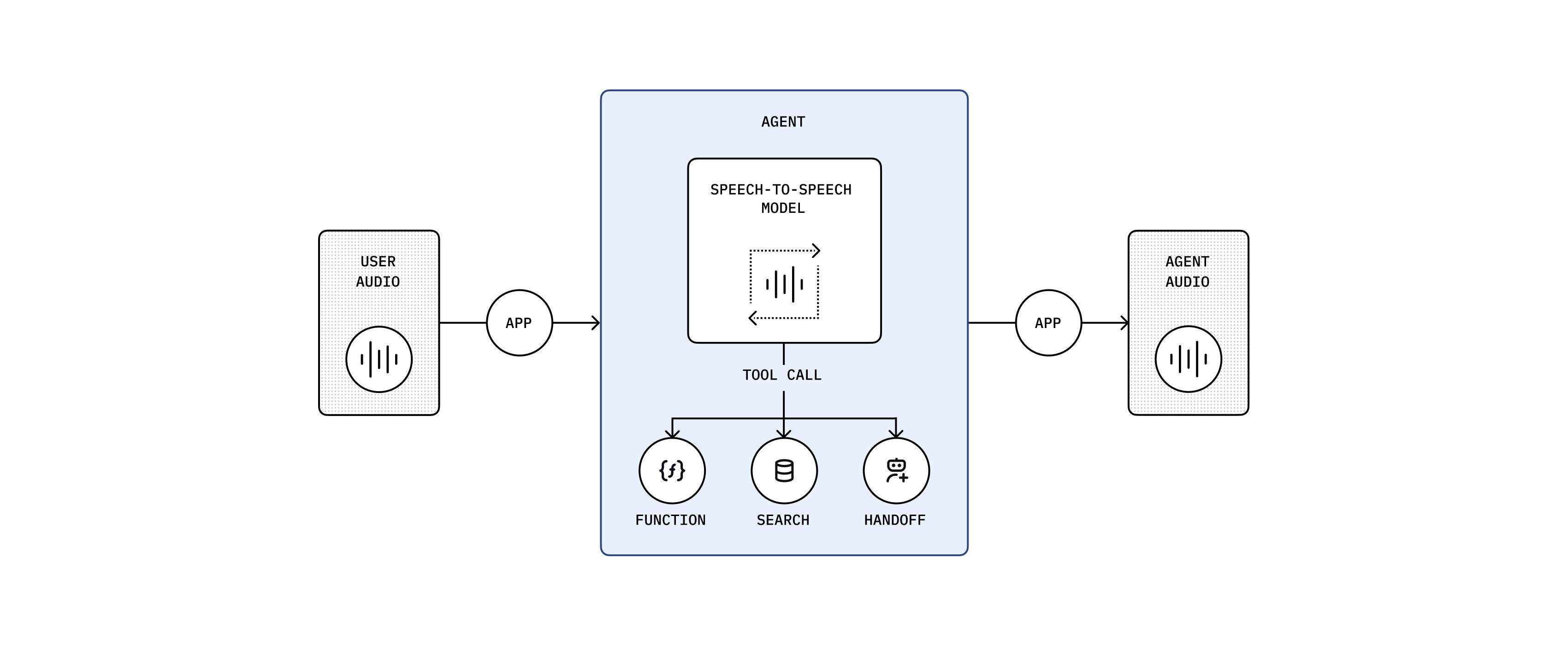
GPT-Realtime:単一モデルで統合された機能
GPT-Realtime は複数モデルの連結を不要にします。音声から音声への全プロセスを単一モデルで処理するため、エンドツーエンドのレイテンシが大幅に低減されます。