动作 (Sink)
在 NeuronEX,动作 (Sink) 用来向外部系统写入数据。
Sink 类型
用户可以直接使用 NeuronEX 的内置动作。动作类型的列表如下:
- MQTT:输出到外部 MQTT 服务。
- Neuron:输出到NeuronEX的数采模块。
- REST:输出到外部 HTTP 服务器。
- 内存:输出到内存主题以形成规则流水线。
- Log:写入日志,通常只用于调试。
- SQL:写入 SQL 数据库。
- InfluxDB: 写入 InfluxDB
v1.x。 - InfluxDB V2: 写入 InfluxDB
v2.x。 - 文件: 写入文件。
- Nop:不输出,用于性能测试。
- Kafka:输出到 Kafka 。
- Image sink:输出到图片文件。
动作公共参数配置
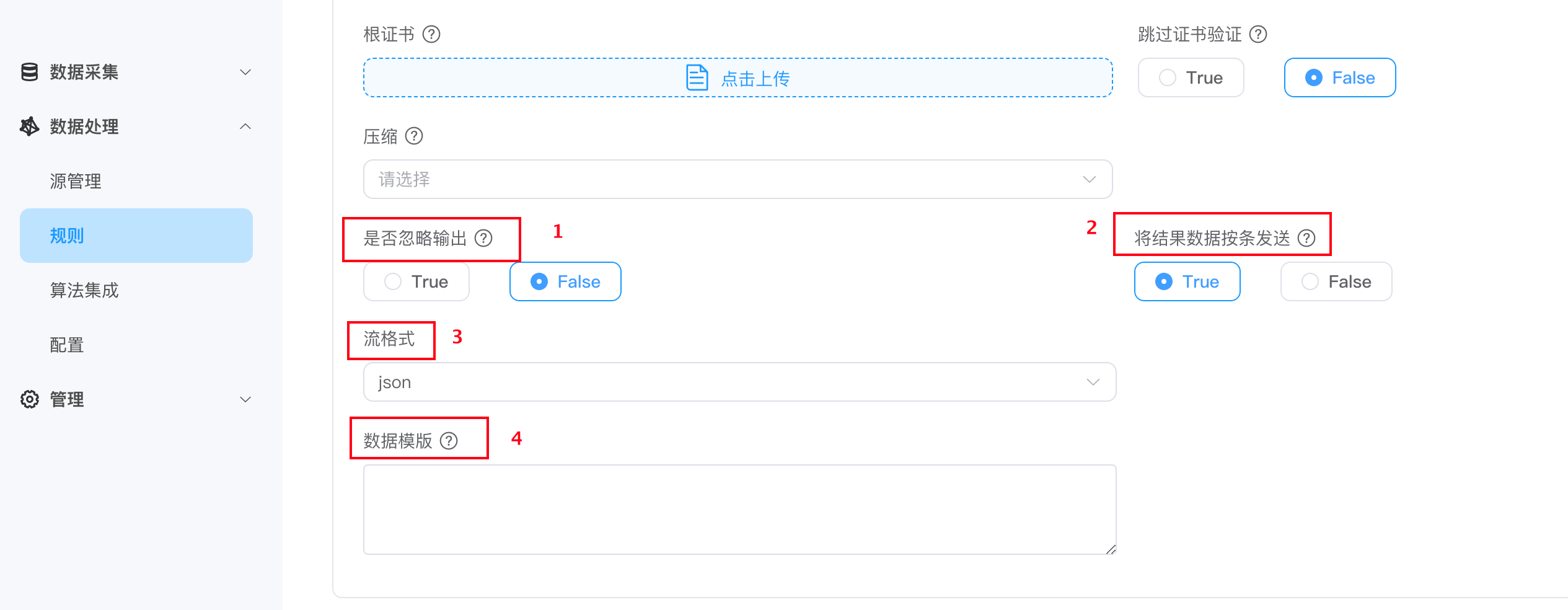
是否忽略输出
默认为 false。
是否忽略输出为true,当规则 SQL的处理结果为空时,则忽略输出。是否忽略输出为false,当规则 SQL的处理结果为空时,输出{}。
将结果数据按条发送
- 默认为 true,结果消息将一一对应发送,输出格式一般为
JSON格式。 - 如设为 false,结果消息将根据规则 SQL 的处理结果组合发送。输出格式一般为包裹 JSON 的
数组格式。
- 默认为 true,结果消息将一一对应发送,输出格式一般为
流格式
用于定义传入的数据类型,支持
json、protobuf、binary、delimited和custom,默认为JSON。以下为其中部分流格式的介绍:delimited
对于 CSV 文件数据源,需选择
delimited格式,还应指定分隔符来区分数据字段,如 ","protobuf
Protobuf 是一种序列化结构数据的方式,当流格式设置为
protobuf时,还应配置解码时使用的模式。模式可在 数据处理 -> 配置 -> 模式中定义。有关模式的详细介绍,请查阅 模式 章节。Binary
对于二进制数据流,例如图像或者视频流,需要指定数据格式为
binary。custom
custom是由用户自定义的数据格式 。
数据模版
数据模板支持用户对分析结果进行"二次处理",以满足不同接收系统的多样化格式要求。利用 Golang 模板系统,提供了动态数据转换、条件输出和迭代处理的机制,确保了与各种接收器的兼容性和精确格式化。 关于数据模版的详细介绍,请查阅 数据模版 章节。
提示
数据模版为可选配置。如不指定数据模板,则将规则处理的结果正常输出。
动态属性
有些情况下,用户需要按照数据把结果发送到不同的目标中。例如,根据收到的数据,把计算结果发到不同的 mqtt 主题中。使用基于数据模板格式的动态属性,可以实现这样的功能。在以下的例子中,目标的 topic 属性是一个数据模板格式的字符串从而在运行时会将消息发送到动态的主题中。
{
"id": "rule1",
"sql": "SELECT topic FROM demo",
"actions": [{
"mqtt": {
"sendSingle": true,
"topic": "prefix/{{.topic}}"
}
}]
}需要注意的是,上例中的 sendSingle 属性已设置。在默认情况下,目标接收到的是数组,使用的 jsonpath 需要采用 {{index . 0 "topic"}}。
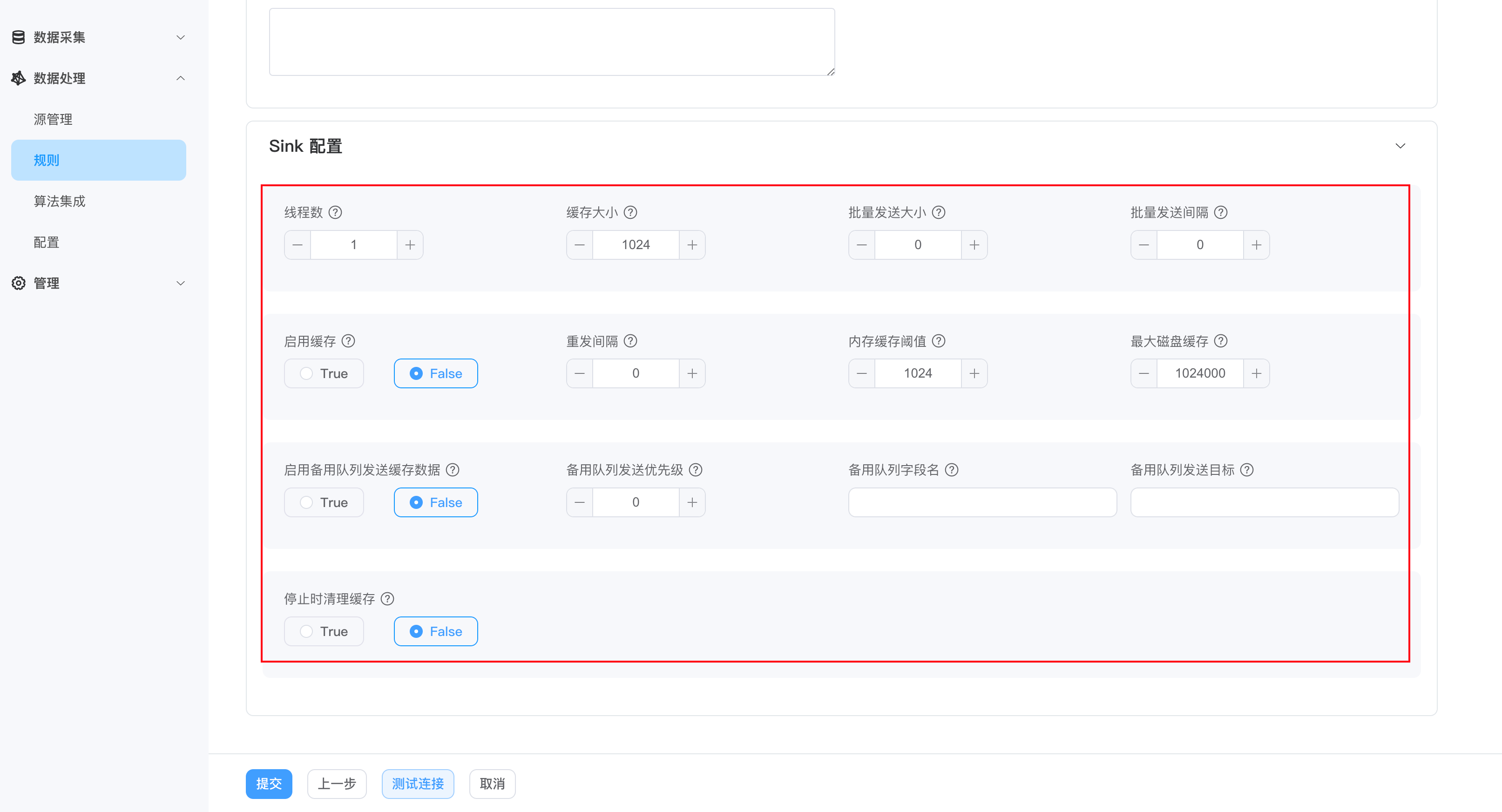
高级 Sink 配置
您可点击展开Sink 配置部分实现更加定制化的设置。
- 线程数:设置运行的线程数。该参数值大于 1 时,消息发出的顺序可能无法保证。
- 缓存大小:设置可缓存消息数目。若缓存消息数超过此限制,sink 将阻塞消息接收,直到缓存消息数目小于限制为止。
- 批量发送大小:设置批量发送的消息数目。
- 批量发送间隔:设置批量发送的间隔时间,单位为毫秒。
- 启用缓存:设置是否启用sink 缓存,可选值 True、False
- 重发间隔:故障恢复后重新发送信息的时间间隔,防止信息风暴。
- 内存缓存阈值:要缓存在内存中的消息数量。
- 最大磁盘缓存:缓存在磁盘中的消息的最大数量。
- 停止时是否清理缓存:是否在规则停止时清理所有缓存,以防止规则重新启动时对过期消息进行大量重发,可选值 True、False。
- 启用备用队列发送缓存数据:是否在重新发送缓存时使用备用队列。如果设置为true,缓存将被发送到备用队列,而不是原始队列。这将导致实时消息和重发消息使用不同的队列发送,消息的顺序发生变化,但是可以防止消息风暴。只有设置为 true 时,以下 resend 相关配置才能生效。
- 备用队列发送优先级:重新发送缓存的优先级,int 类型,默认为 0。-1 表示优先发送实时数据;0 表示同等优先级;1 表示优先发送缓存数据。
- 备用队列字段名:重新发送缓存的字段名。
- 备用队列发送目标:MQTT sink: 该属性表示重传的主题。若未设置,则仍传到原主题。
数据缓存
NeuronEX 中的动作提供了缓存功能,用于在发送错误的情况下暂存数据,并在错误恢复之后自动重发缓存数据。动作的缓存可分为内存和磁盘两级存储。用户可配置内存缓存条数,超过上限后,新的缓存将离线存储到磁盘中,通过同时利用内存和磁盘空间,实现更大的缓存容量;此外,动作还将持续检测故障恢复状态,支持在不重启规则的情况下重新发送。
- 错误检测:发送失败后,sink 应该通过返回特定的错误类型来识别可恢复的失败(网络等),这将返回一个失败的 ack,并触发缓存。成功发送后,或错误不可恢复的情况下,将发送一个成功的 ack 来删除缓存。
- 缓存机制:缓存将首先被保存在内存中。如果超过了内存的阈值,后面的缓存将被保存到磁盘中。一旦磁盘缓存超过磁盘存储阈值,缓存将开始 rotate,即内存中最早的缓存将被丢弃,并加载磁盘中最早的缓存来代替。
- 重发策略:目前缓存机制仅可运行在默认的同步模式中,如果有一条消息正在发送中,则会等待发送的结果以继续发送下个缓存数据。否则,当有新的数据到来时,发送缓存中的第一个数据以检测网络状况。如果发送成功,将按顺序链式发送所有内存和磁盘中的所有缓存。链式发送可定义一个发送间隔,防止形成消息风暴。
配置
动作 (Sink) 缓存的配置有两个层次。在配置文件中定义所有规则的默认行为。还有一个规则 sink 层的定义,用来覆盖默认行为。
- 启用缓存:是否启用sink cache。
- 内存缓存阈值:要缓存在内存中的消息数量。出于性能方面的考虑,最早的缓存信息被存储在内存中,以便在故障恢复时立即重新发送。这里的数据会因为断电等故障而丢失。
- 最大磁盘缓存:缓存在磁盘中的信息的最大数量。磁盘缓存是先进先出的。如果磁盘缓存满了,最早的一页信息将被加载到内存缓存中,取代旧的内存缓存。
- 重发间隔:故障恢复后重新发送信息的时间间隔,防止信息风暴。
- 停止时是否清理缓存:是否在规则停止时清理所有缓存,以防止规则重新启动时对过期消息进行大量重发。如果不设置为true,一旦规则停止,内存缓存将被存储到磁盘中。否则,内存和磁盘规则会被清理掉。
在以下规则的示例配置中,log sink 没有配置缓存相关选项,因此将会采用全局默认配置;而 MQTT sink 进行了自身缓存策略的配置。
{
"id": "rule1",
"sql": "SELECT * FROM demo",
"actions": [{
"log": {},
"mqtt": {
"server": "tcp://127.0.0.1:1883",
"topic": "result/cache",
"qos": 0,
"enableCache": true,
"memoryCacheThreshold": 2048,
"maxDiskCache": 204800,
"bufferPageSize": 512,
"resendInterval": 10
}
}]
}更新动作 (Sink)
默认情况下,Sink 将数据附加到外部系统中。一些系统,如内存,支持更新或删除数据。与查找源类似,只有少数 Sink 是updateble的。updateble Sink 必须支持插入、更新和删除。NeuronEX 内置的updateble类型的 Sink 包括:
为了激活更新功能,Sink 必须设置 rowkindField 属性,以指定数据中的哪个字段代表要采取的动作。在下面的例子中,rowkindField 被设置为 action。
{"sql": {
"addr": "127.0.0.1:6379",
"dataType": "string",
"field": "id",
"rowkindField": "action",
"sendSingle": true
}}流入的数据必须有一个字段来表示更新的动作。在下面的例子中,action 字段是要执行的动作。动作可以是插入、更新、 upsert 和删除。不同的 sink 的动作实现是不同的。有些 sink 可能对插入、upsert 和更新执行相同的动作。
{"action":"update", "id":5, "name":"abc"}这条信息将把 id 为 5的数据更新为新的名字。