NeuronEX 最佳实践:集成 MySQL 数据到您的 IIoT 平台
在工业数字化的浪潮中,IT 与 OT 的融合已成为不可逆转的趋势。工厂车间的设备数据(OT 数据)固然重要,但它们往往需要与来自企业 IT 系统的数据相结合,才能释放出最大的价值。这些 IT 系统,如制造执行系统(MES)、仓库管理系统(WMS)或企业资源规划(ERP),通常使用 SQL 数据库(如 MySQL)来存储生产工单、物料信息、质量标准、人员排班等关键业务数据。
将这些 SQL 数据源与实时的设备数据进行关联,可以为我们提供更丰富的上下文,从而实现更高级的应用,例如:
- 产品质量追溯:将设备运行参数与特定批次的产品工单关联。
- 生产效率分析:结合工单计划与实际设备产出,精确计算 OEE。
- 预测性维护:根据 ERP 中的设备维护记录和实时工况,优化维护计划。
NeuronEX 作为一款工业边缘网关软件,除了支持 100+ 种工业协议外,它还能采集来自数据库(如 MES/WMS/ERP)、企业服务总线(ESB)、RESTful API 等多种 IT 系统的数据。
本文将详细介绍如何使用 NeuronEX 作为强大的边缘数据桥梁,高效、可靠地从 MySQL 数据库中拉取数据,经过处理后,将其无缝转发到 EMQX Platform 平台,从而打通 IT 与 OT 之间的数据壁垒。
准备工作
在开始之前,请确保您已准备好以下环境,通过在电脑中安装 Docker Desktop 软件,您可以在自己电脑中部署以下服务,来快速体验该文章中的内容。
- NeuronEX:
docker run -d --name neuronex -p 8085:8085 --log-opt max-size=100m --privileged=true emqx/neuronex:3.6.0- MySQL 数据库:
docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0- MQTTX:
MQTTX 是一款跨平台的 MQTT 5.0 客户端,用于测试验证发送到 EMQX Platform 的数据。点击下载 MQTTX
实践步骤
我们将通过三个核心步骤完成整个数据链路的配置:
- 在 MySQL 中创建数据:在 MySQL 中创建一个数据表,并插入一些数据。
- 在 NeuronEX 中获取 MySQL 中的数据:在 NeuronEX 中创建一个数据流,用于连接并定期查询 MySQL 数据库。
- 通过 MySQL 表中的自增 id 字段实现增量查询:对从 MySQL 获取的数据进行选择和处理。
- 通过 MySQL 表中的时间戳字段实现增量查询:将处理后的数据通过 MQTT 协议发送到 EMQX。
- 配置 MQTT Sink 将数据转发至 EMQX:将处理后的数据通过 MQTT 协议发送到 EMQX。
- 配置规则选项中的流的 QoS和检查点间隔,实现规则自动恢复:在规则选项中配置流的 QoS和检查点间隔,实现规则自动恢复。
步骤一:在 MySQL 中创建数据
当我们通过以上命令启动 MySQL 服务后,我们可以通过以下命令进入 MySQL 的命令行模式,密码为123456。
docker exec -it mysql mysql -u root -p在 MySQL 中创建一个数据库,用于存储需要采集的数据。
CREATE DATABASE IF NOT EXISTS testdb;使用这个数据库
use testdb;创建数据表
CREATE TABLE DeviceData (
id INT AUTO_INCREMENT PRIMARY KEY ,
Time TIMESTAMP NOT NULL ,
DeviceName VARCHAR(100) NOT NULL ,
Current INT ,
Voltage INT
);插入一些数据
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:00', 'moter_A', 100, 200);
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:05', 'moter_B', 120, 210);
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:10', 'moter_C', 150, 220);可以通过以下命令查看表中的插入数据,确认是否执行以上操作成功。
SELECT * FROM DeviceData;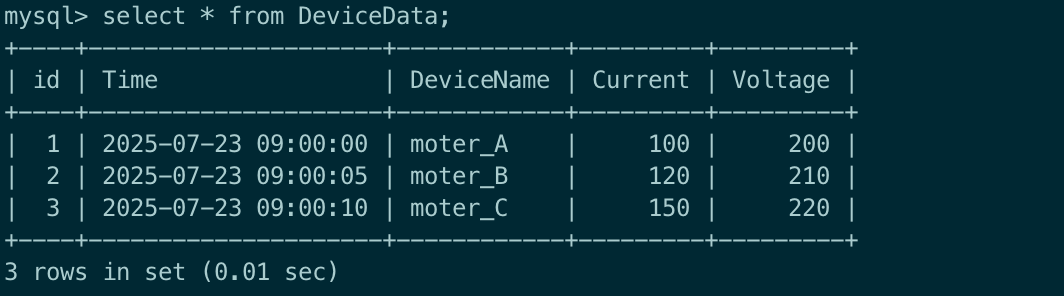
步骤二:在 NeuronEX 中获取 MySQL 中的数据
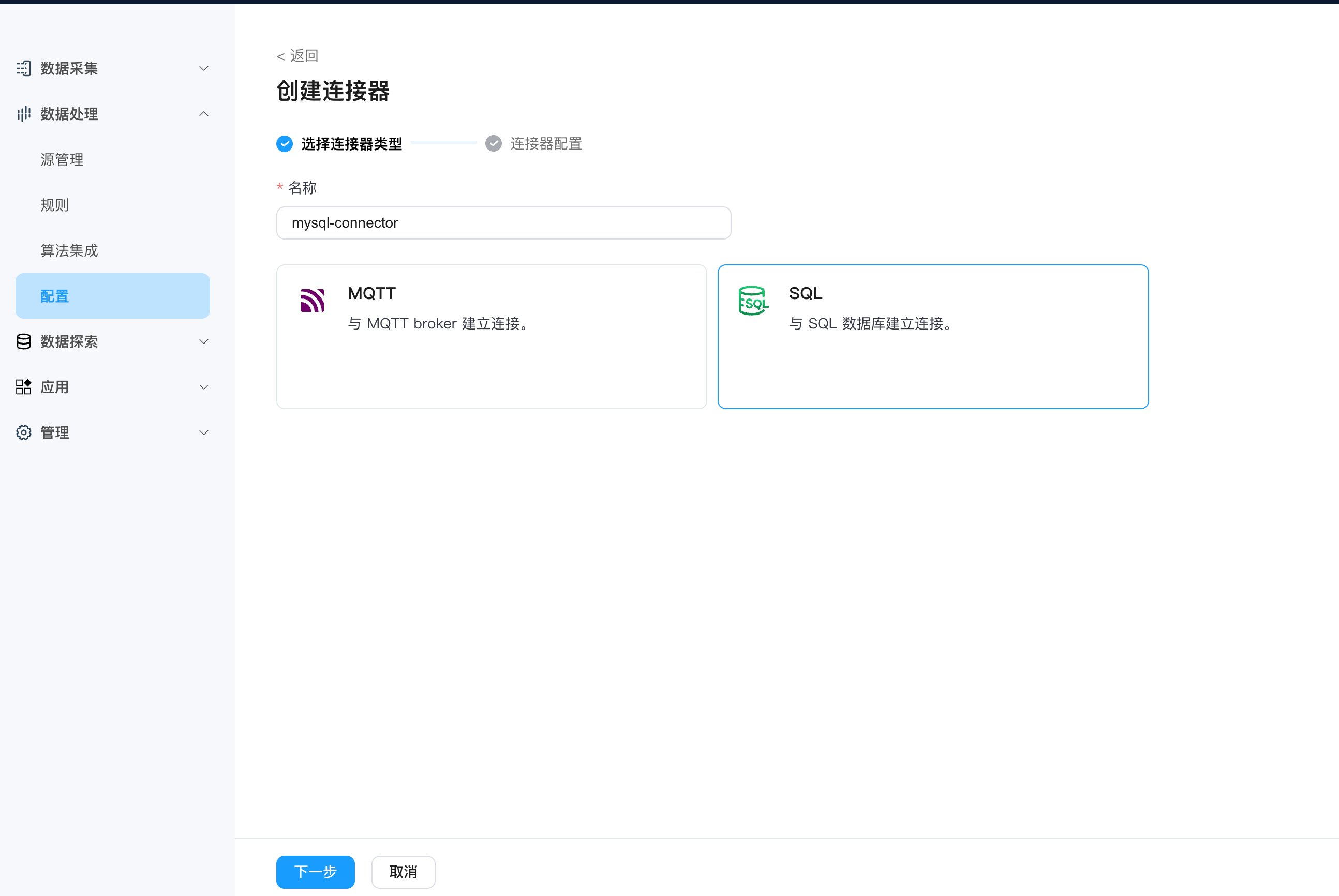
首先在 NeuronEX 的数据处理->配置 页面,创建连接器,选择 MySQL 连接器,填写以下信息:
- 数据库地址:
mysql://root:123456@192.168.1.43:3306/testdb?parseTime=true,表示连接到本地的 MySQL 数据库,数据库名称为testdb,用户名称为root,密码为123456。
TIP
由于 NeuronEX 和 MySQL 分别部署在两个容器中,所以通过 localhost 无法访问到 MySQL 数据库,需要通过 IP 地址访问。 在实际应用中,您需要将 192.168.1.43 替换为您电脑的实际 IP 地址。
连接器创建成功后,连接状态正常。
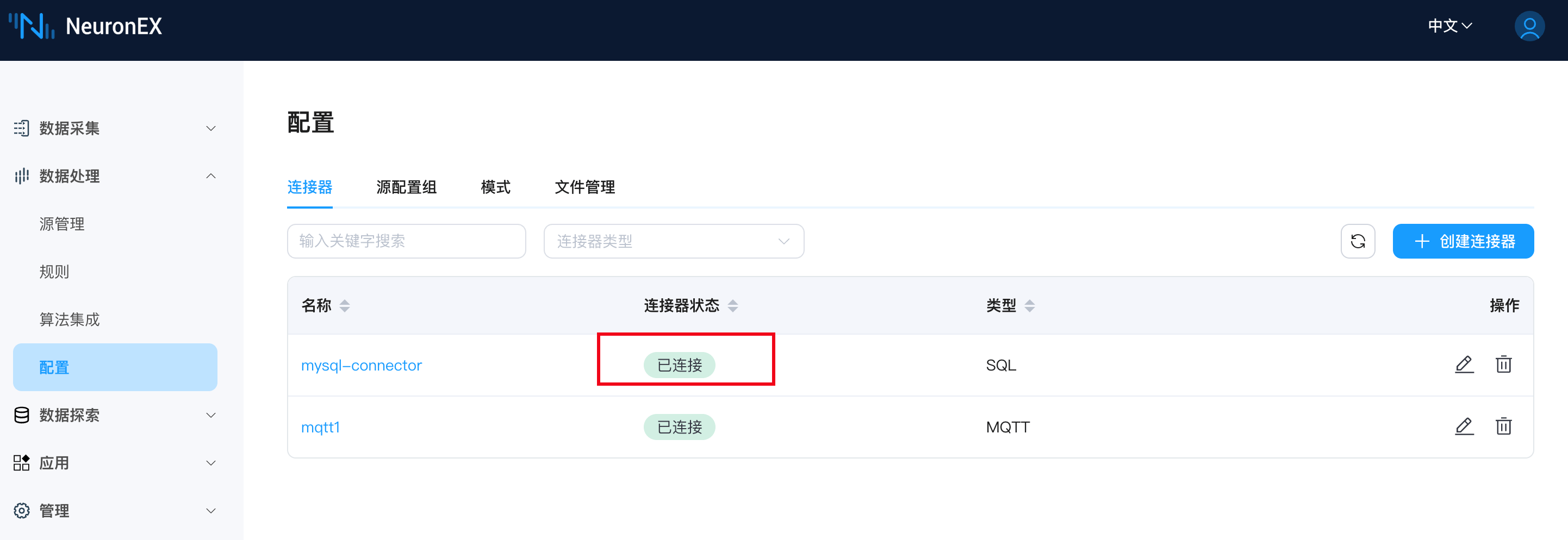
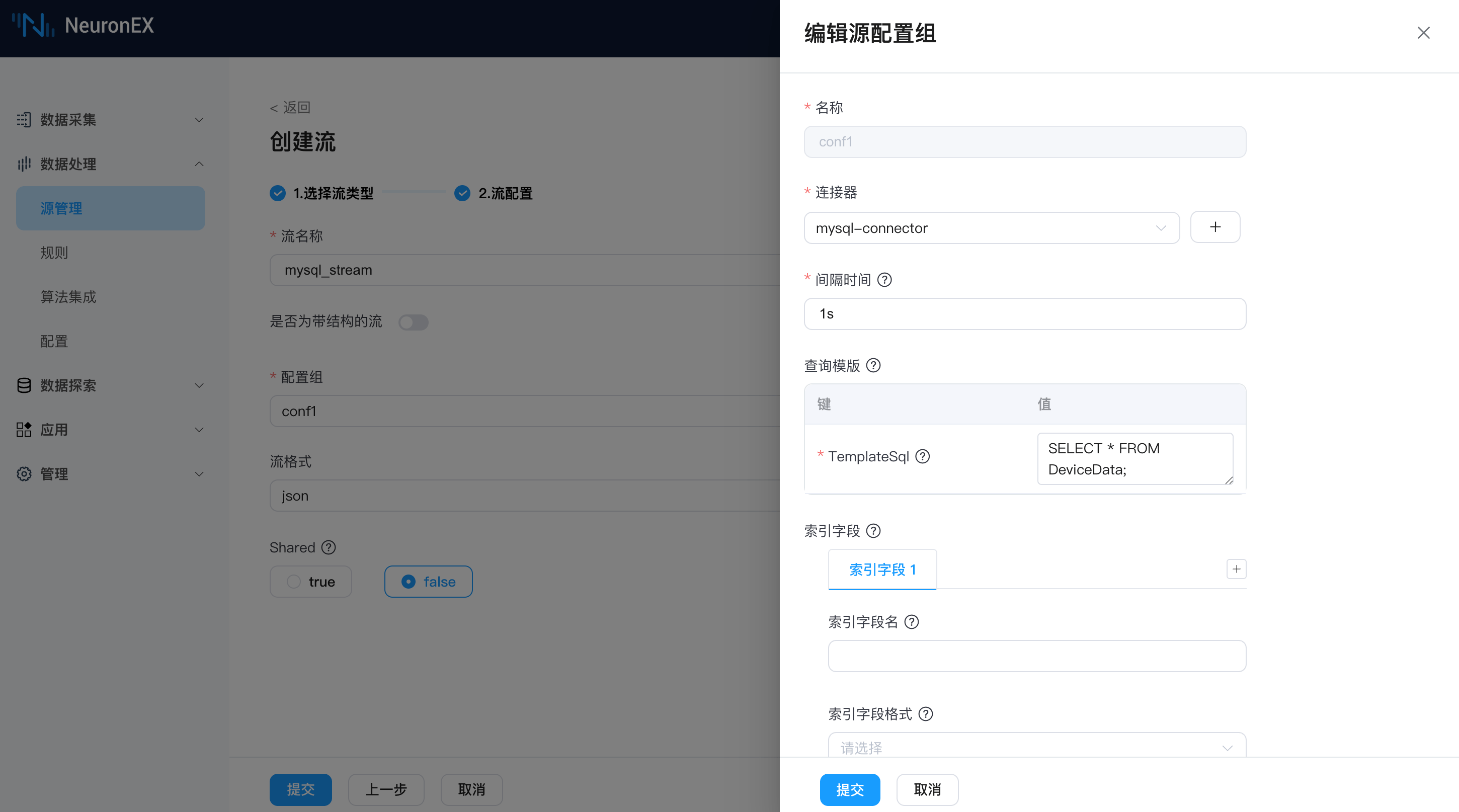
接下来我们通过这个连接器来创建数据源。在 NeuronEX 的数据处理->源管理 页面,点击 创建流,选择 SQL 类型数据源,填写以下信息:
- 流名称:
mysql_stream,也可任意命名。 - 源配置组
- 名称:
conf1 - 连接器:
mysql-connector - 间隔时间:
1s,表示每1秒向数据库拉取一次数据 - 查询模板:
SELECT * FROM DeviceData ;,先使用最简单的查询语句,后续可以修改为更复杂的查询语句。
- 名称:
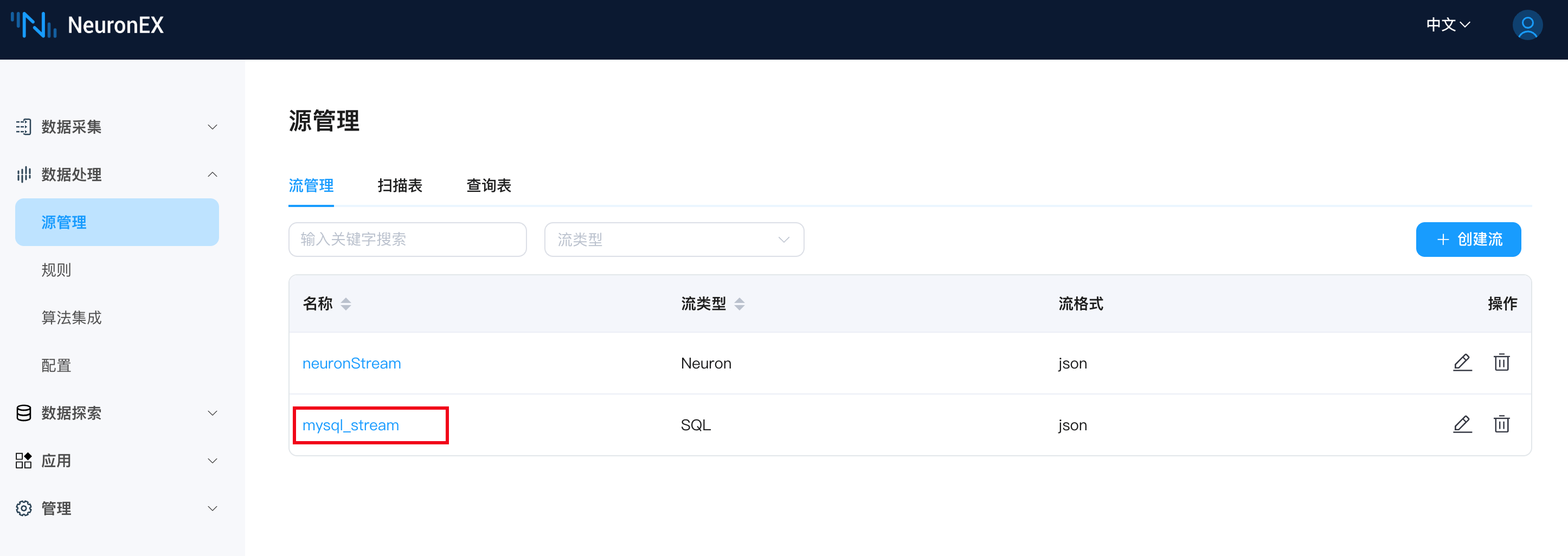
创建成功后,在源管理页面可以看到刚创建的 mysql_stream。
接下来我们在数据处理->规则 页面,点击 新建规则,进行如下操作,规则编辑器的内容改为如下,点击规则调试按钮,即可看到从 MySQL 中获取的数据。
后续当我们配置 MQTT Sink 后,即可以把当前规则调试中显示的 JSON 格式数据,发送到 EMQX 中。
SELECT
*
FROM
mysql_stream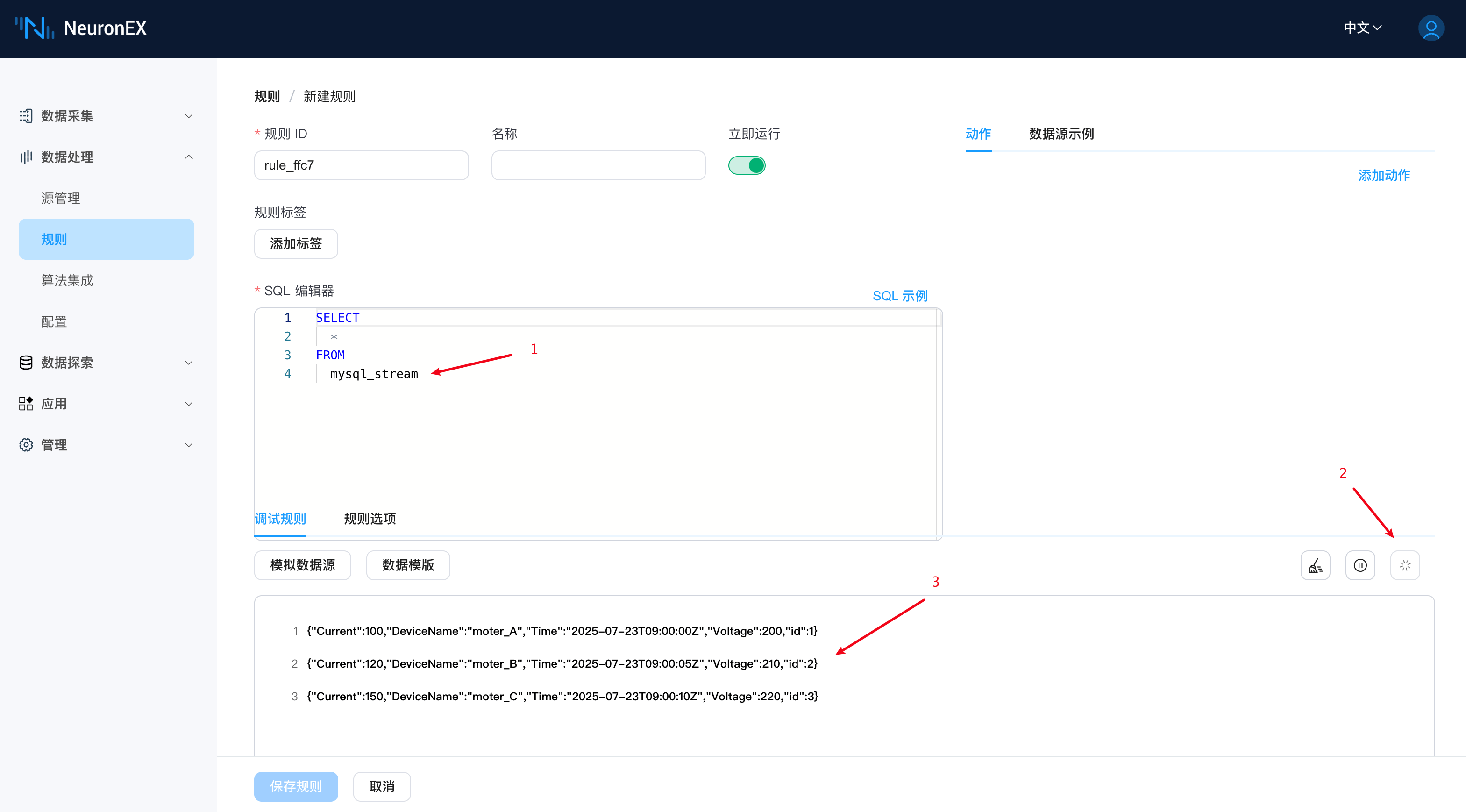
步骤三:通过 MySQL 表中的自增 id 字段实现增量查询
在 MySQL 中,我们创建的表中,id 字段是自增的,因此我们可以通过 id 字段来实现增量查询。这样 NeuronEX 每次查询时,会从上一次查询的最后一条数据开始查询,从而实现增量查询。
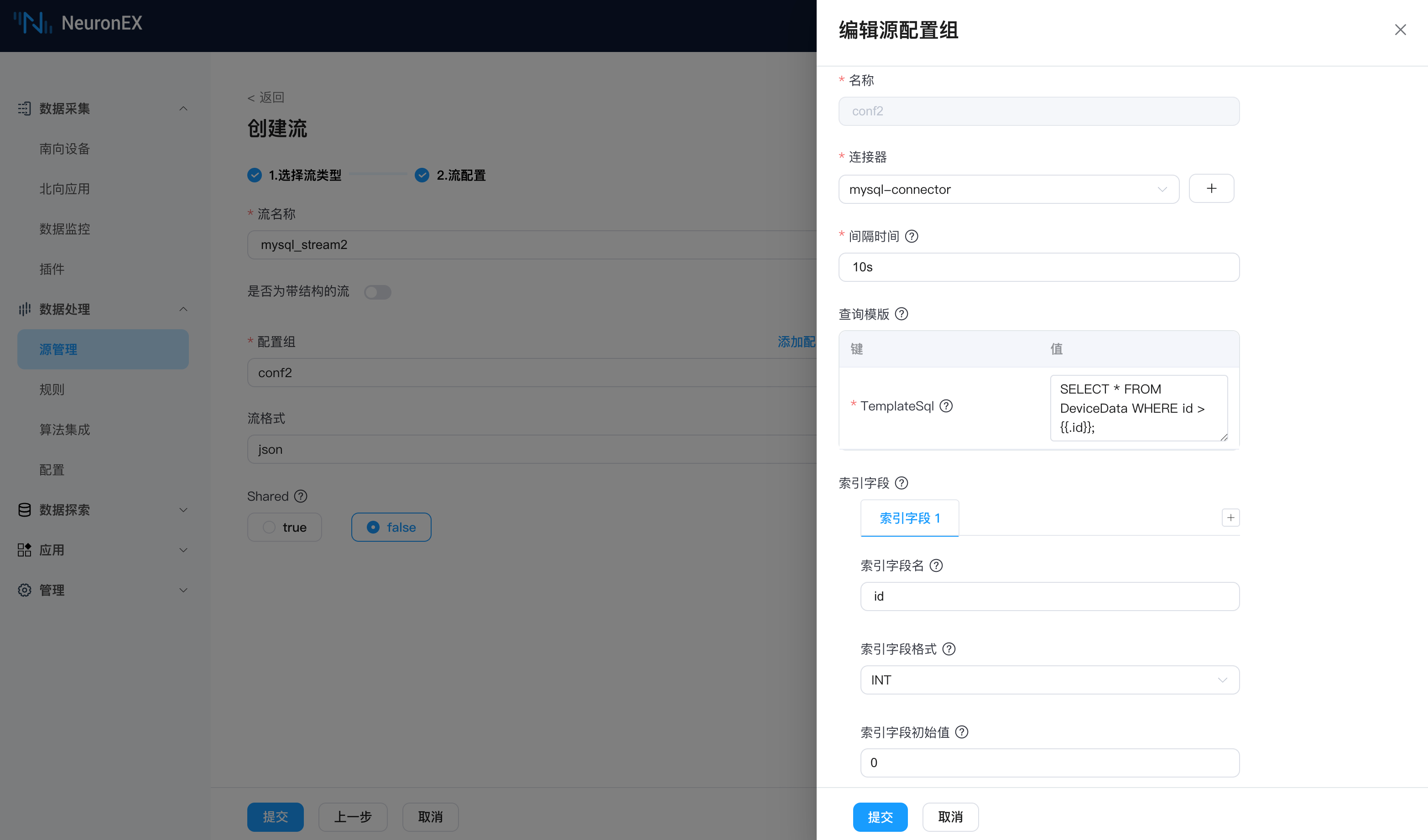
我们仍使用前序步骤中创建的连接器mysql-connector来创建数据源。在 NeuronEX 的数据处理->源管理 页面,点击 创建流,选择 SQL 类型数据源,填写以下信息:
流名称:
mysql_stream2,也可任意命名。源配置组
- 名称:
conf2,可任意命名。 - 连接器:
mysql-connector,使用前序步骤中创建的连接器。 - 间隔时间:
10s,表示每10秒向数据库拉取一次数据。 - 查询模板:使用
.id来表示上一次查询的最后一条数据的 id 值。
sqlSELECT * FROM DeviceData WHERE id > {{.id}};- 索引字段名:
id,表示使用 id 字段来实现增量查询。 - 索引字段格式:
INT,表示 id 字段是整数类型。 - 索引字段初始值:
0,表示查询的起始值为 0。
- 名称:
作如上配置后,我们在数据处理->规则 页面,点击 新建规则,将规则编辑器的内容改为如下,点击规则调试按钮,即可看到从 MySQL 中获取的数据。此时会发现,如果 MySQL 数据库中后续没有数据写入 DeviceData 表,则 NeuronEX 将不会拉取重复的数据。
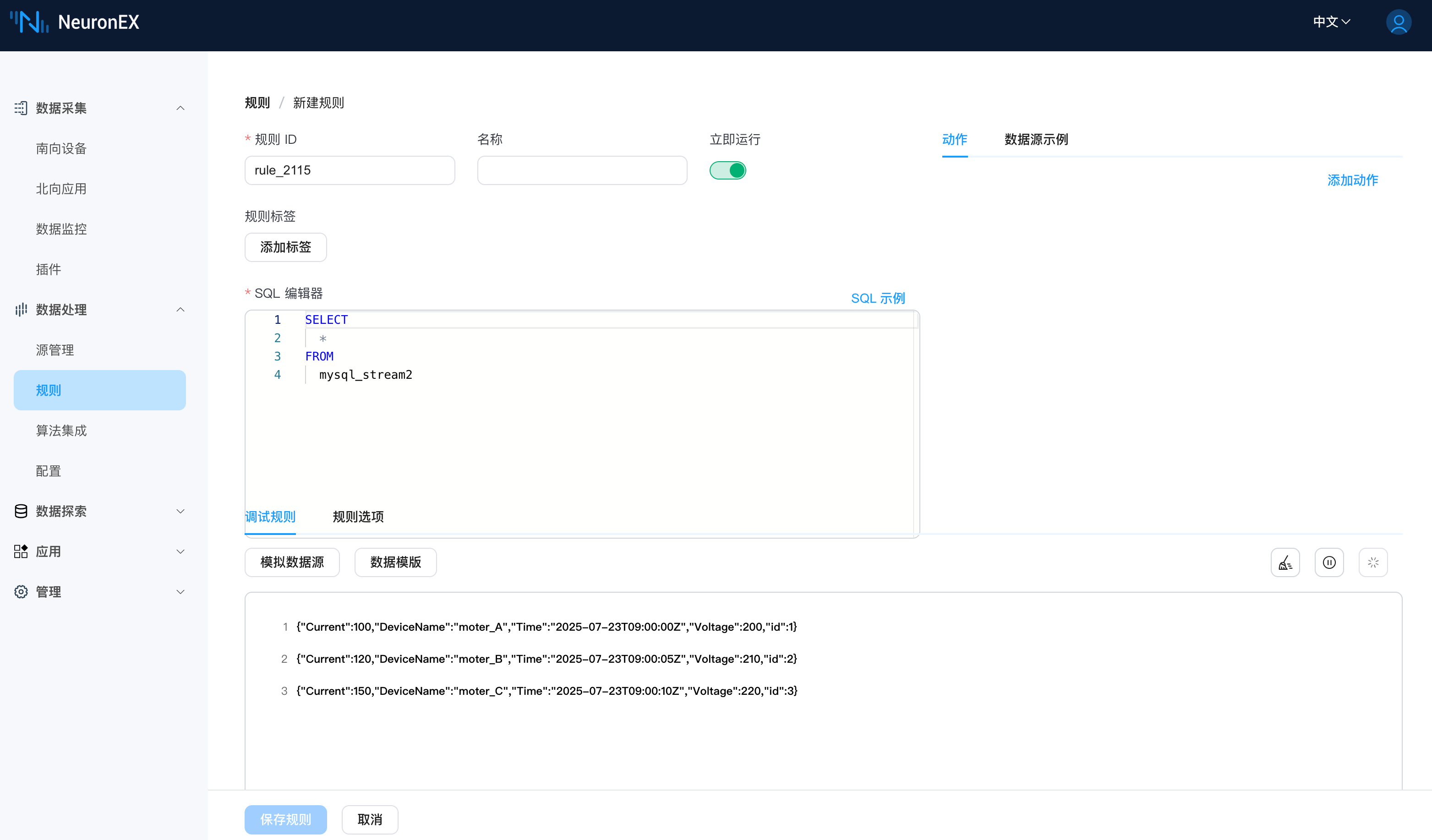
当我们在 DeviceData 表中插入一条数据后,NeuronEX 会自动拉取这条数据,并更新索引字段初始值。
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:15', 'moter_A', 150, 220);此时在规则调试页面,可以看到 NeuronEX 拉取到了这条新数据。(在上一步骤中,不需要停止规则调试)
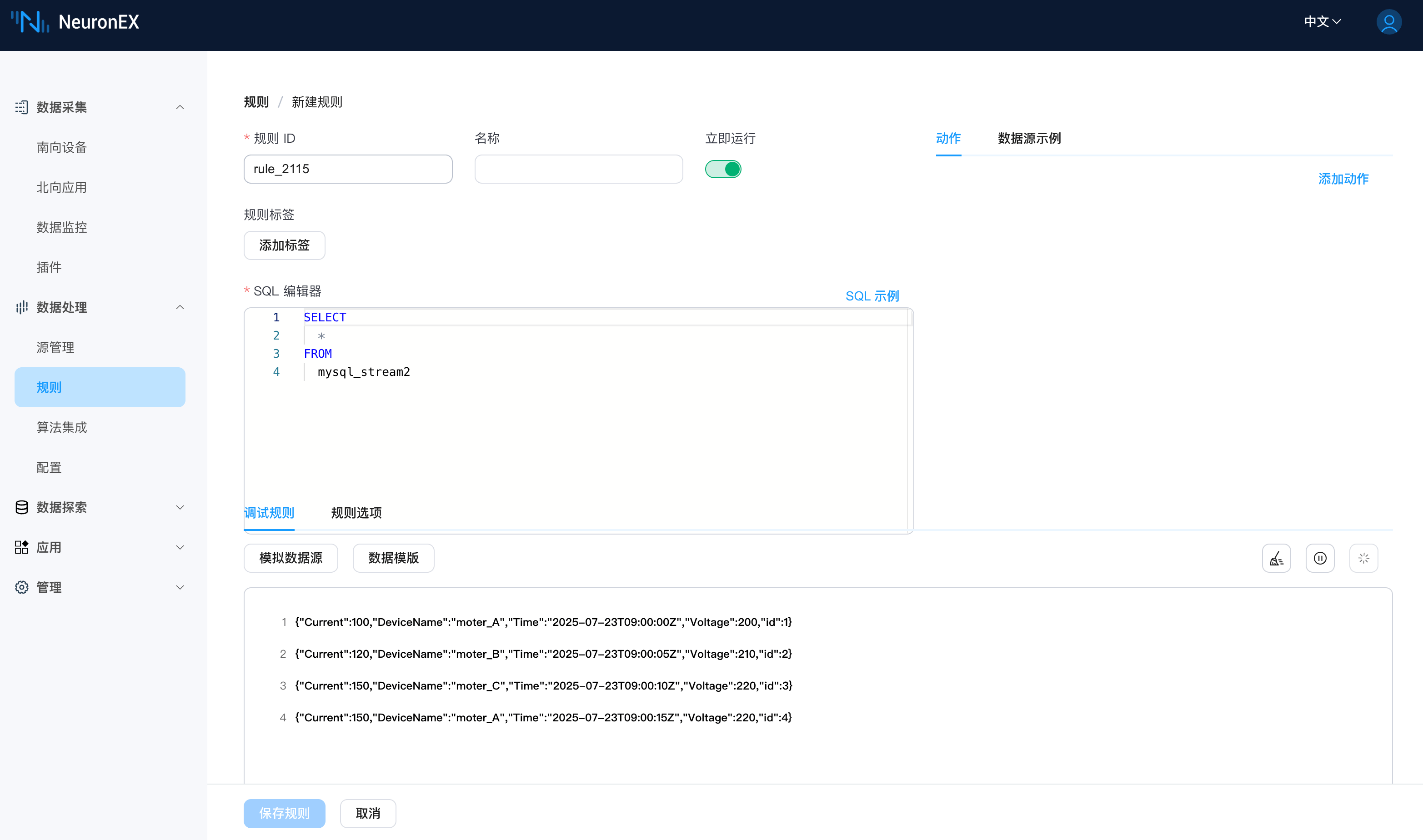
通过以上步骤,我们实现了通过 MySQL 表中的自增 id 字段实现增量查询。通过组合使用 索引字段名, 索引字段格式 和 索引字段初始值,NeuronEX 实现了高效的增量轮询。它会记住上次查询返回数据中的最大 id 值,并在下一次查询时仅拉取 id 大于该值的新数据,极大地降低了数据库负载和网络开销。
在实际应用中,您可以在做数据拉取的同时,结合 NeuronEX 强大的流式处理函数进行更复杂的数据清洗、格式转换或聚合计算。
步骤四:通过 MySQL 表中的时间戳字段实现增量查询
除了使用自增 id 字段实现增量查询外,我们还可以使用时间戳字段实现增量查询。
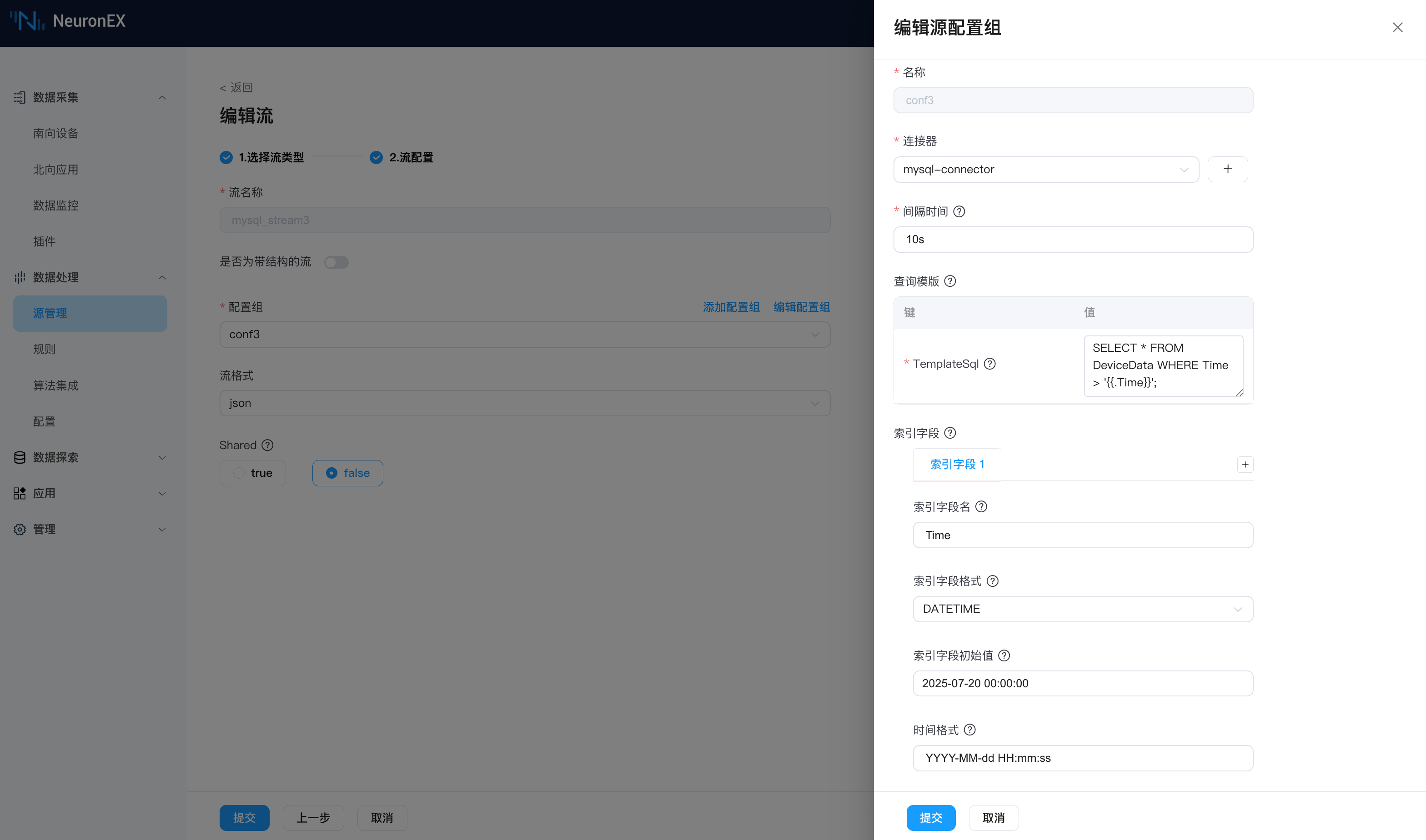
我们仍使用前序步骤中创建的连接器mysql-connector来创建数据源。在 NeuronEX 的数据处理->源管理 页面,点击 创建流,选择 SQL 类型数据源,填写以下信息:
流名称:
mysql_stream3,也可任意命名。源配置组
- 名称:
conf3,可任意命名。 - 连接器:
mysql-connector,使用前序步骤中创建的连接器。 - 间隔时间:
10s,表示每10秒向数据库拉取一次数据。 - 查询模板:使用 .Time 来表示上一次查询的最后一条数据的 Time 值。
sqlSELECT * FROM DeviceData WHERE Time > '{{.Time}}';- 索引字段名:
Time,表示使用 Time 字段来实现增量查询。 - 索引字段格式:
DATETIME,表示 id 字段是整数类型。 - 索引字段初始值:
2025-07-20 00:00:00,表示查询的起始值为 2025-07-20 00:00:00。 - 时间格式:
YYYY-MM-dd HH:mm:ss,表示时间格式。
- 名称:
作如上配置后,我们在数据处理->规则 页面,点击 新建规则,将规则编辑器的内容改为如下,点击规则调试按钮,即可看到从 MySQL 中获取的数据。此时会发现,如果 MySQL 数据库中后续没有数据写入 DeviceData 表,则 NeuronEX 将不会拉取重复的数据。
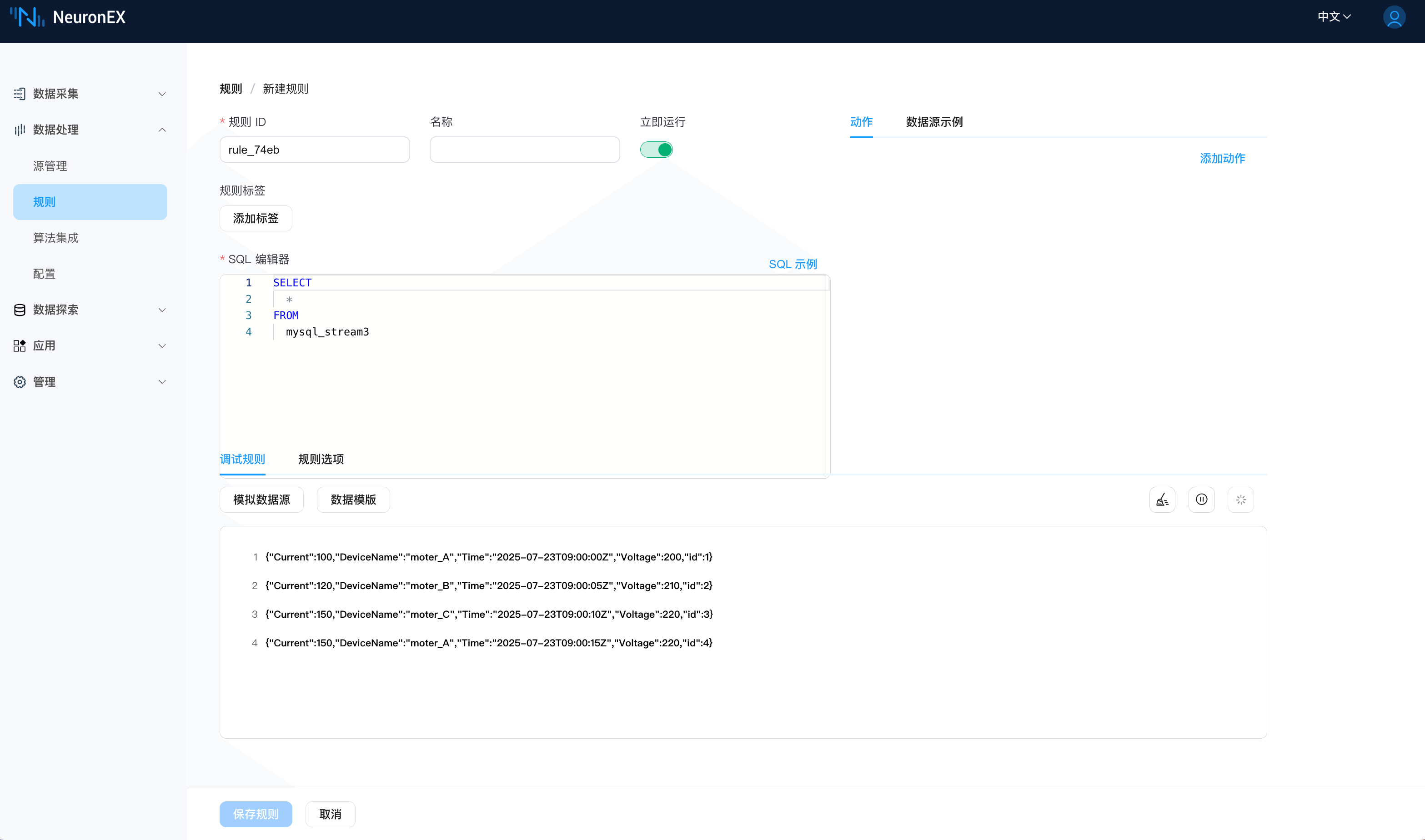
当我们在 DeviceData 表中插入一条新数据,其中 Time 字段值为 2025-07-23 09:00:20。
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:20', 'moter_B', 333, 555);此时在规则调试页面,可以看到 NeuronEX 拉取到了这条新数据。(在上一步骤中,不需要停止规则调试)
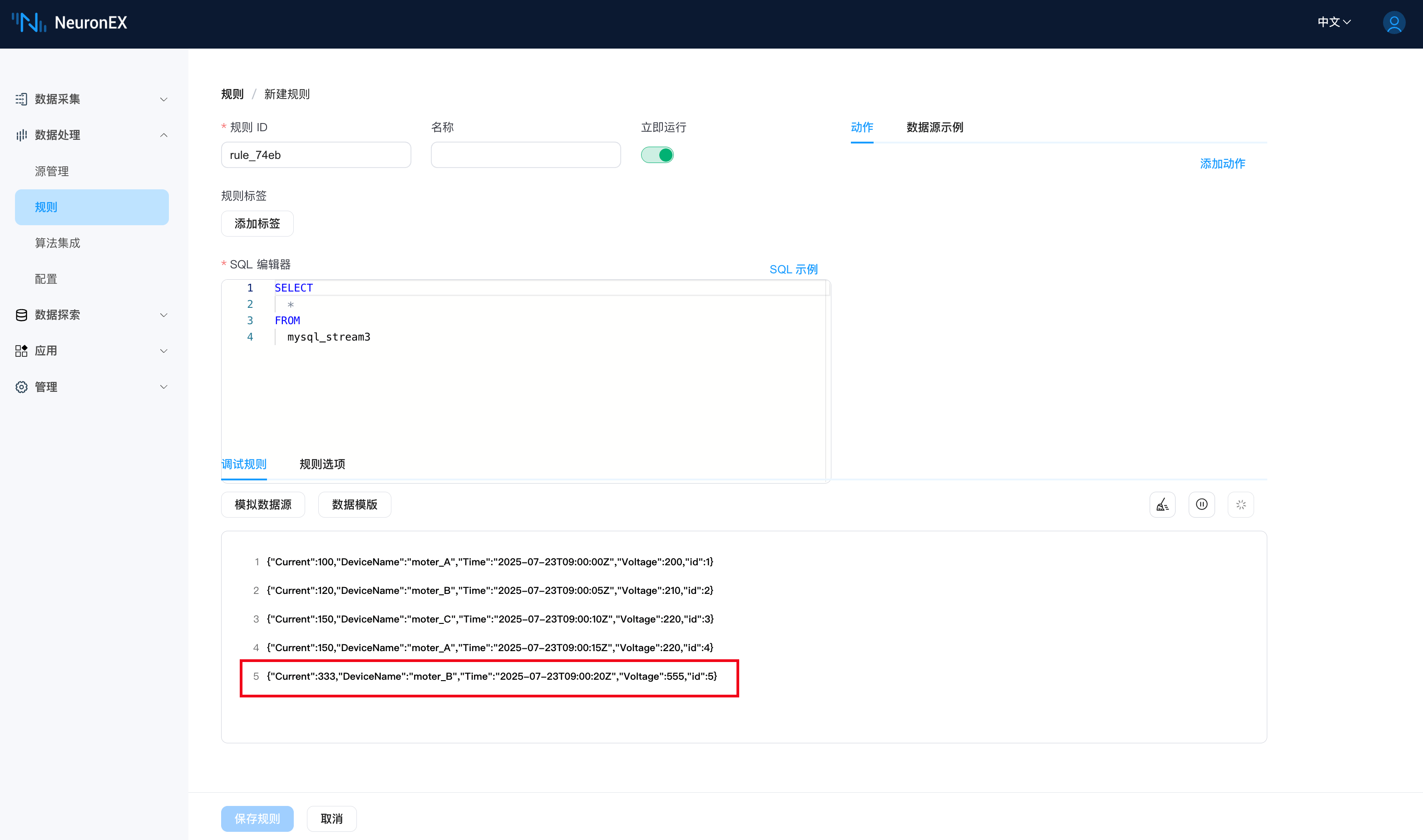
通过以上步骤,我们实现了通过 MySQL 表中的时间戳字段实现增量查询。通过组合使用 索引字段名,索引字段格式,索引字段初始值和时间格式,NeuronEX 实现了高效的增量轮询。
步骤五:配置 MQTT Sink 将数据转发至 EMQX
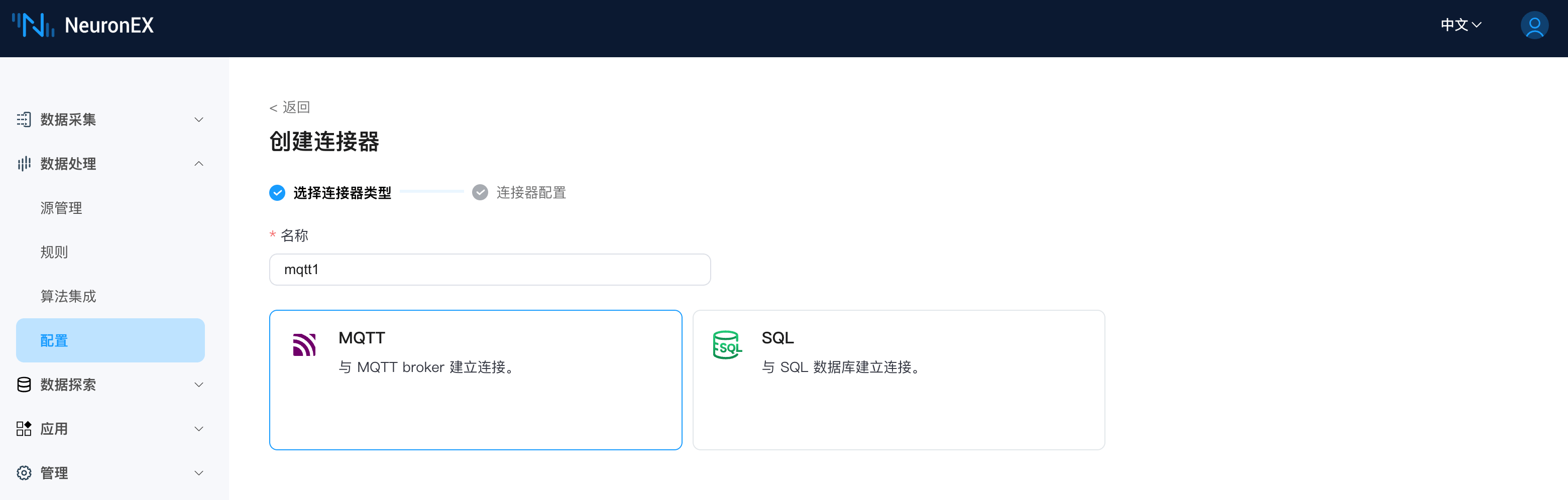
首先我们需要先创建一个 MQTT 连接器,在 NeuronEX 的数据处理->配置 页面,创建连接器,选择 MQTT 连接器,填写以下信息:
- Broker 地址:
tcp://broker.emqx.io:1883,其他使用默认值即可。
连接器创建成功后,连接状态正常。
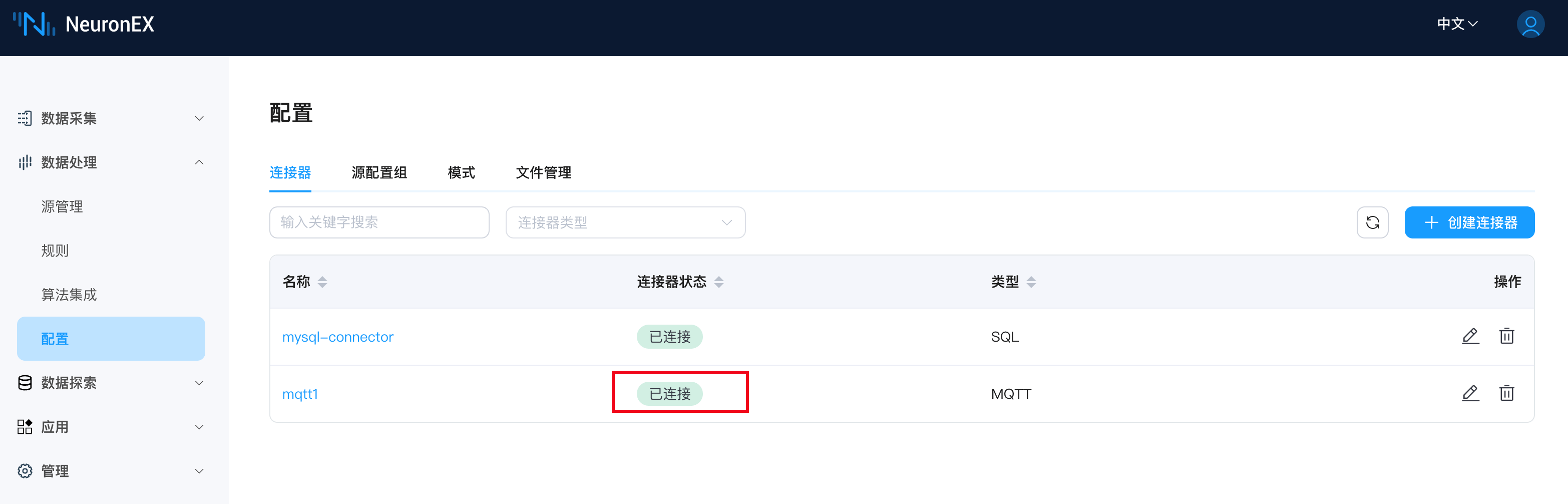
新建规则,为规则添加一个“ MQTT 动作(Action)”,将处理结果发送到 MQTT Broker EMQX 中。规则编辑器的内容如下:
SELECT
*
FROM
mysql_stream3MQTT 动作配置如下,连接器选择我们刚创建的连接器mqtt1,主题: topic/mysql,其他使用默认值即可。
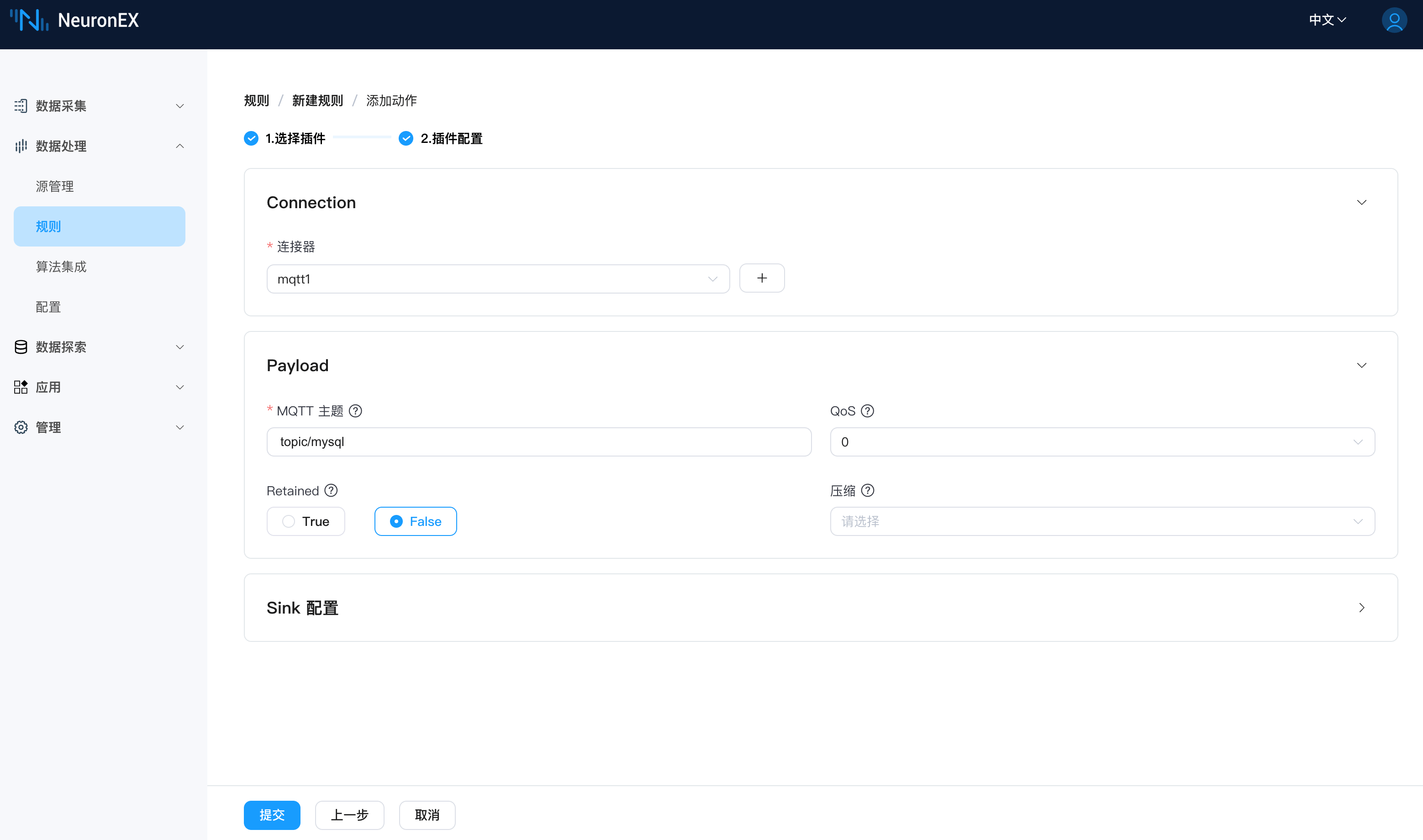
创建成功后,规则处于运行状态。

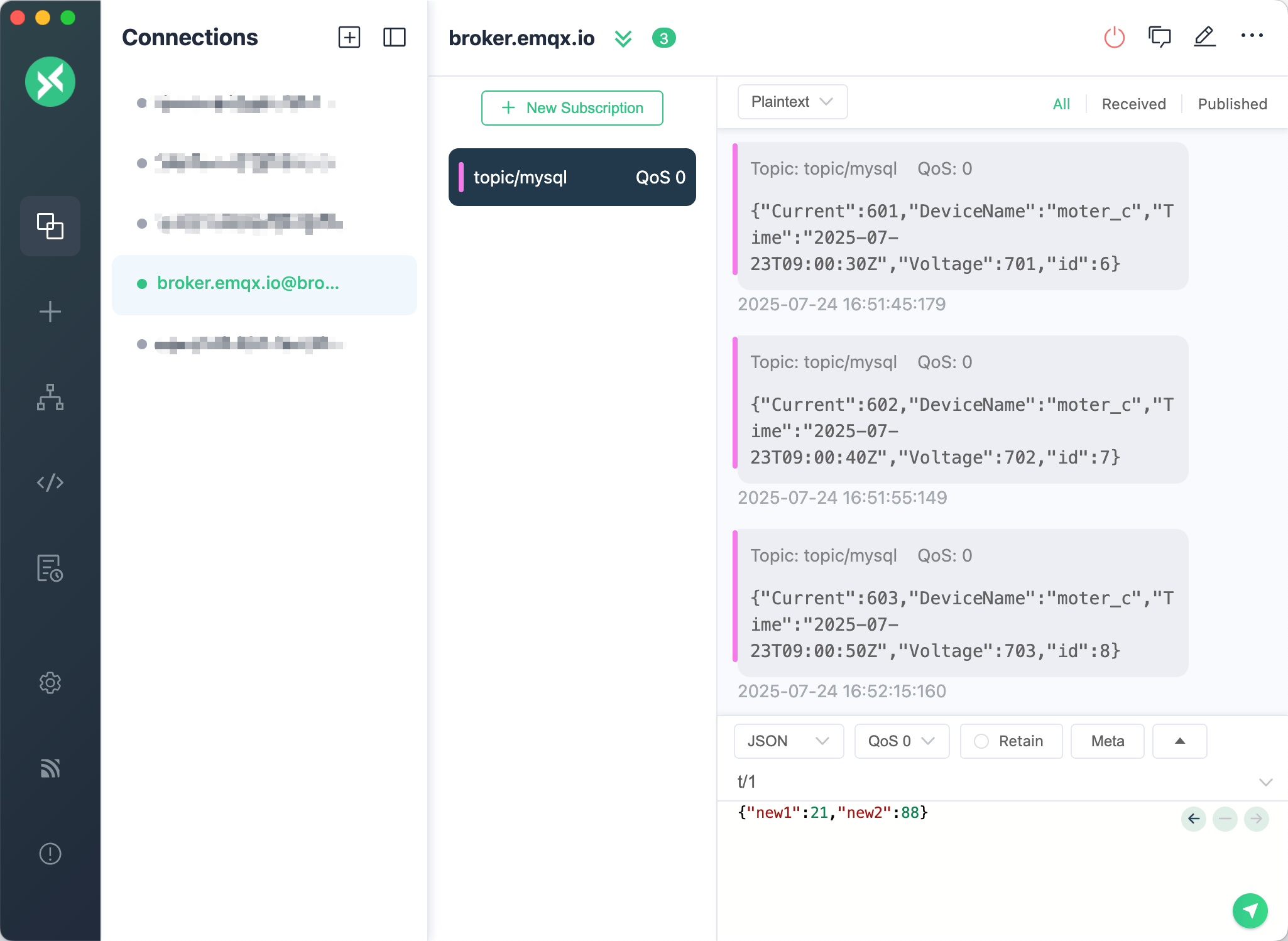
我们可以通过 MQTTX 客户端,订阅主题 topic/mysql,查看数据是否被发送到 EMQX 中。首先我们向数据库中继续插入多条数据。
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:30', 'moter_c', 601, 701);
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:40', 'moter_c', 602, 702);
INSERT INTO DeviceData (Time, DeviceName, Current, Voltage) VALUES ('2025-07-23 09:00:50', 'moter_c', 603, 703);此时在 MQTTX 客户端,可以看到数据被发送到 EMQX 中。
步骤六:配置规则选项中的流的 QoS和检查点间隔,实现规则自动恢复
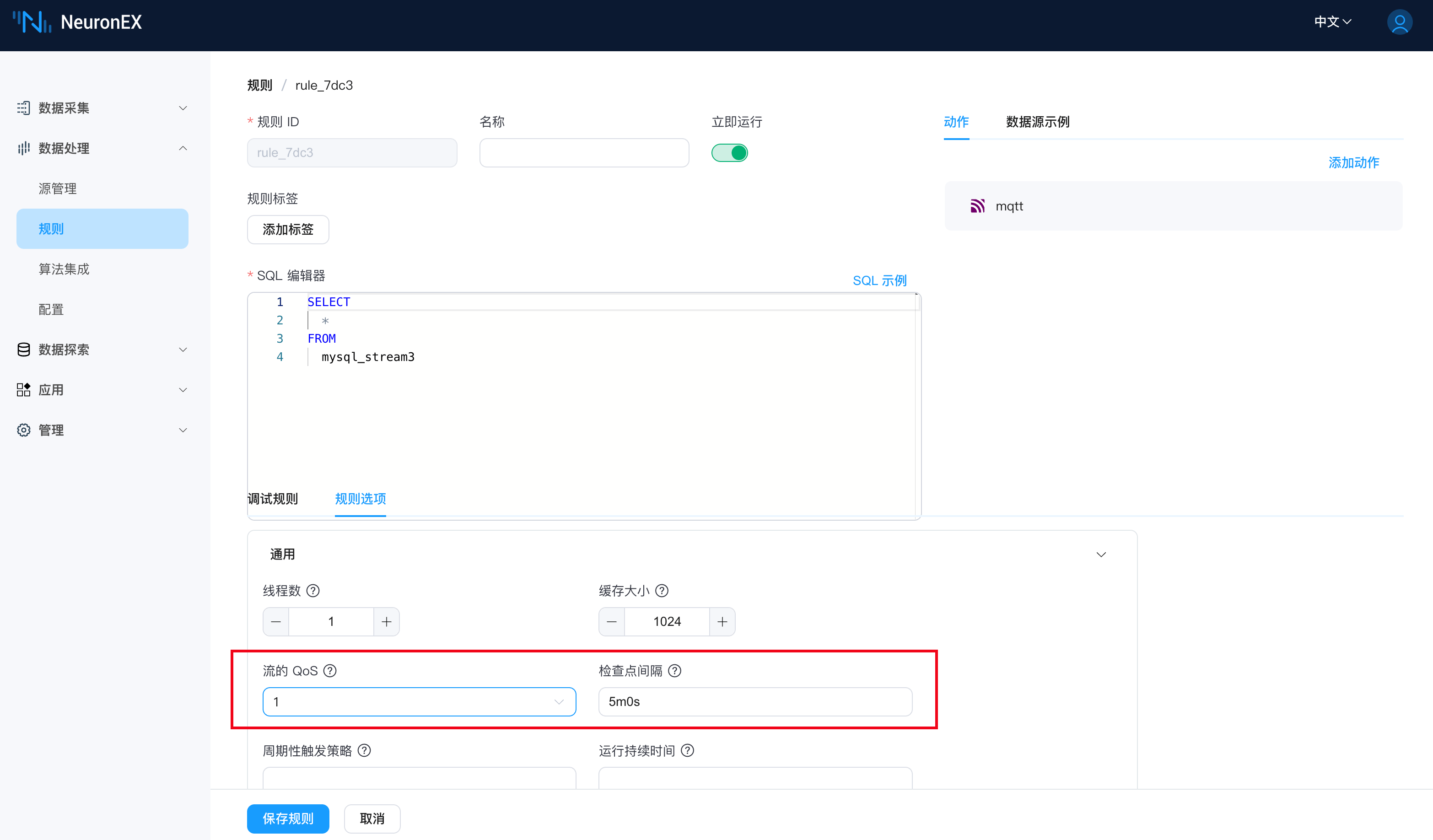
我们可以在规则页面,通过配置规则选项中的流的 QoS和检查点间隔,可以保存数据库数据增量拉取功能的索引字段名,以此来实现当规则被手动停止或者NeuronEX服务异常停止的情况下,规则可以自动恢复,继续从上一次记录的索引值开始拉取数据。
- 流的 QoS:需要设置为
1或者2。 - 检查点间隔:默认为5m0s,表示每5分钟保存一次检查点,可根据自己的实际情况进行调整。
总结
通过以上步骤,我们成功利用 NeuronEX 搭建了一个从 MySQL 数据库到 EMQX 平台的实时数据桥梁。这个方案不仅高效、可靠,而且充分利用了 NeuronEX 的增量查询能力,对源数据库的影响降到了最低。
这种将 IT 业务数据与 OT 实时数据在边缘或云端进行融合的能力,是实现智能制造、驱动数据决策的关键基础设施。NeuronEX 作为连接万物的枢纽,正在帮助越来越多的制造企业打破数据孤岛,释放其工业数据的真正潜力。