数据处理
NeuronEX 内置了数据处理引擎,提高数据处理的实时性,降低边云通信成本,为工业场景提供低延迟的数据接入管理及智能分析服务。
架构
NeuronEX 数据处理模块的架构如下:
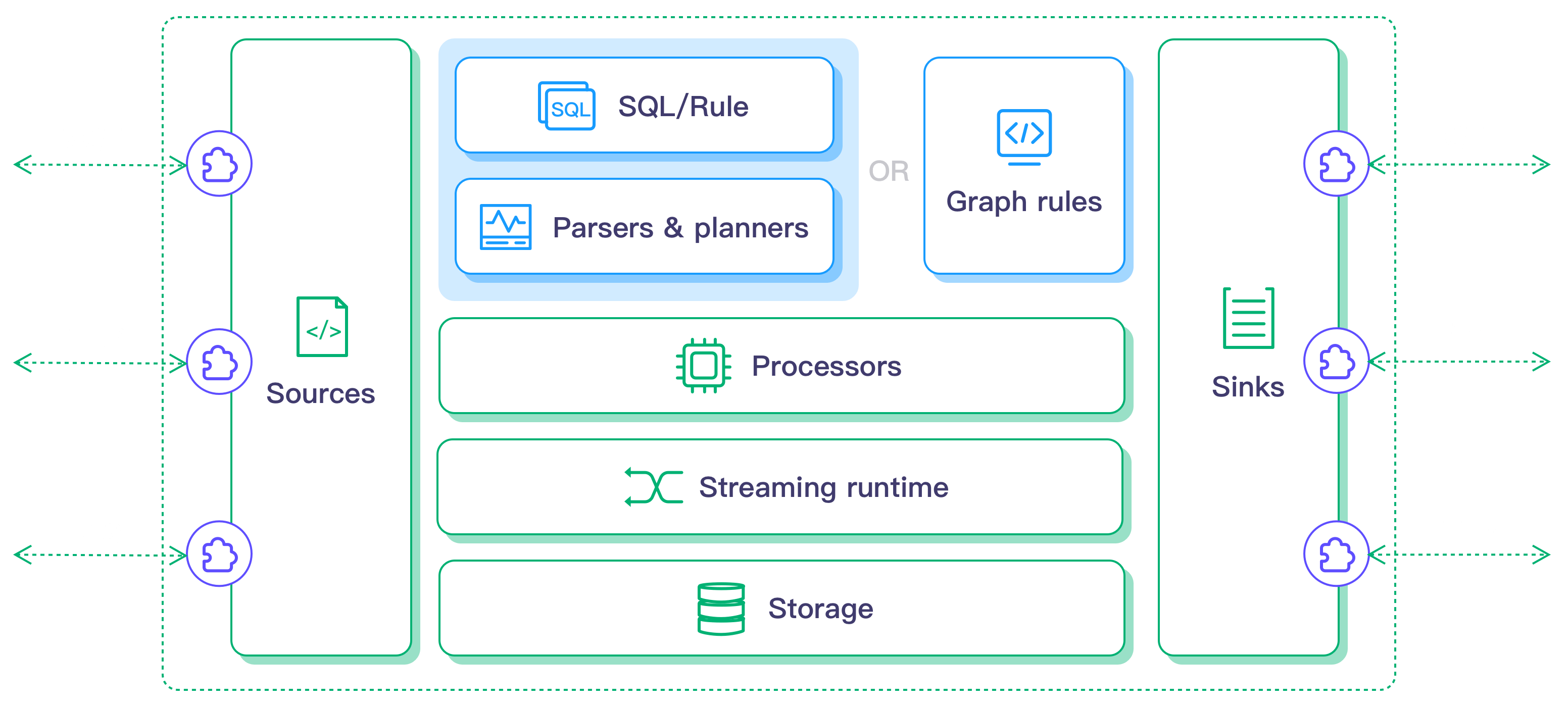
特点及优势
低延迟
提供低延迟的数据处理分析,能够更快速地将数据在多系统间传递,结合 AI/ML 算法,可以实现智能决策与控制。
完整的数据分析
- 数据抽取、转换和过滤
- 数据排序、分组、聚合、连接
- 160+ 各类函数,覆盖数学运算、字符串处理、聚合运算和哈希运算等
- 4 类时间窗口,以及计数窗口
AI/ML 集成
可通过 Python 或者 Go 扩展接入自定义函数、 AI/ML 算法等,实现在源(Source),函数(Function), 动作(Sink) 三个方面的扩展.
- 源 (Source) :允许用户接入更多的数据源用于数据分析
- 目标 (Sink):允许用户将分析结果发送到不同的扩展系统中
- 函数(Function):允许用户增加自定义函数用于数据分析(比如,AI/ML 的函数调用)
多源数据接入集成
具备各类数据灵活获取的能力,可以支持:
MES、WMS、ERP系统对接
数据库对接
企业服务总线(ESB)对接
文件数据采集
视频流接入分析
核心概念
源(Source)
源(Source)定义了与外部系统的连接方式,以便将数据加载进来。在规则中,根据数据使用逻辑,数据源可作为 流(Stream) 或者 表(Table) 使用。
流(Stream):流是 NeuronEX 中数据源接入的主要运行方式,用户可通过选择数据源类型及配置参数来定义如何连接到外部资源。数据流中有数据流入时,都会触发规则中的计算。
表(Table):表 (Table) 用于表示流的当前状态。它可以被认为是流的快照,您可通过表对数据进行批处理。通过在规则中组合使用流与表,可以实现更多的数据处理功能。
源的解码:用户可以在创建源时通过指定
format属性来定义解码方式。当前支持json、binary、protobuf和delimited格式,你也可以使用自己的编码格式,并将该字段定义为custom。源的定义与运行:创建数据源的流或者表之后,系统实际上只是创建了一个数据源的逻辑定义而非真正物理运行的数据输入。此逻辑定义可在多个规则的 SQL 的
from子句中使用。只有当使用了该定义的规则启动之后,数据流才会真正运行。
目前 NeuronEX 内置以下数据源:
- Neuron: 从 NeuronEX 数采模块读取数据;
- MQTT:从 MQTT 主题读取数据;
- HTTP pull:从 HTTP 服务器中拉取数据;
- HTTP push:通过 NeuronEX 内置的HTTP Server源接收 HTTP 客户端消息;
- 内存:从内存主题读取数据以形成规则流水线;
- SQL:从
sqlserver\postgresql\mysql\sqlite3\oracle数据库中获取数据; - 文件:从文件中读取数据;
- Video:从视频流中获取数据;
- Simulator:内置模拟数据源,用来模拟数据以及调试;
- Redis:从 Redis 读取数据。
- CAN:连接 CAN 总线读取数据。
- Kafka:从 Kafka 读取数据。
- WebSocket:从 WebSocket 读取数据。
规则(Rule)
规则代表了一个数据处理流程,定义了从数据源输入、到各种处理逻辑,再到将数据输出到动作(Sink)。
规则生命周期:规则一旦启动就会连续运行,只有在用户明确发送停止命令时才会停止。规则可能会因为错误或 NeuronEX 实例退出而异常停止。
多个规则的关系:规则在运行时上是分开的,一个规则的错误不影响其他规则。所有的规则都共享相同的硬件资源,每条规则可以指定算子缓冲区,以限制处理速度,避免占用所有资源。
规则流水线:多个规则可以通过指定
内存 Source/Sink形成一个处理管道。例如,第一条规则在内存 sink 中保存结果,其他规则在其内存源中订阅主题获取数据。除了通过内存 Source/Sink,用户还可以使用MQTT Source/Sink来连接规则。SQL语句:NeuronEX 数据处理模块提供了一种类似于 SQL 的查询语言,用于对数据流执行转换和计算。规则中的 SQL 语言支持包括数据定义语言(DDL)、数据操作语言(DML)和查询语言。NeuronEX 中的 SQL 支持是 ANSI SQL 的一个子集,并有一些定制的扩展。
规则调试:在规则创建时,开启规则调试功能,可以实时查看数据源接入后,经过 SQL 处理后的规则输出结果,可以快速对 SQL 语法、内置函数以及数据模板等内容进行测试验证,是否符合预期输出结果。
动作(Sink)
动作Sink:动作Sink 用来向外部系统写入数据,一个规则可以有多个动作,不同的动作可以是同一个动作类型。
数据模板: NeuronEX 通过规则进行数据分析处理后,数据模板将规则处理结果进行「二次处理」后,使用各种 Sink 可以往不同的系统。数据模板为非必须配置项,如果不配置数据模板,规则处理结果将直接输出到 Sink 中。
动作类型
- MQTT sink:输出到外部 MQTT 服务。
- Neuron sink:输出到 NeuronEX 数采模块。
- Rest sink:输出到外部 HTTP 服务器。
- Memory sink:输出到内存(Memory)主题以形成规则流水线。
- Log sink:写入日志,通常只用于调试。
- SQL sink:写入 SQL 数据库。
- InfluxDB V1 sink: 写入 Influx DB
v1.x。 - InfluxDB V2 sink: 写入 Influx DB
v2.x。 - File sink: 写入文件。
- Nop sink:不输出,用于性能测试。
- Kafka sink:输出到 Kafka。
- Image sink:输出到图片文件。
流式处理
流数据是一种不断增长的、无限的数据集,流处理是对流数据的处理。 流处理具有低延迟、近实时的特点,可以在数据产生后就进行处理,以极低的延迟获得结果,因此流处理可以用于实时分析、实时计算、实时预测等场景。
有状态的流处理:有状态的流处理是流处理的一个子集,其中的计算保持着上下文状态。有状态流处理的例子包括:
- 聚合事件以计算总和、计数或平均值时。
- 检测事件的变化。
- 在一系列事件中搜索一个模式。
窗口:窗口提供了一种机制,将无界的数据分割成一系列连续的有界数据来计算。在时间窗口中,同时支持处理时间和事件时间。对于所有支持的窗口类型,请查看窗口函数。在 NeuronEX 中,内置的窗口包括两种类型:
- 时间窗口:按时间分割的窗口
- 计数窗口:按元素计数分割的窗口
多源连接:在流处理中,连接是将多个数据源合并到一起的唯一方法。它需要一种方法来对齐多个来源并触发连接结果。NeuronEX 支持的连接类型包括 LEFT、RIGHT、FULL 和 CROSS 。
流处理的时间概念: 流数据是一个随时间变化的数据序列,其中时间是数据的一个固有属性。在流处理中,时间在计算中起着重要的作用。例如,在做基于某些时间段(通常称为窗口)的聚合时,定义时间的概念是很重要的。在流处理中,有两种时间概念:
- 事件时间,即事件实际发生的时间。通常情况下,事件应该有一个时间戳字段来表明其产生的时间。
- 处理时间,即在系统中观察到事件的时间。
事件时间和水印:一个支持事件时间的流处理器需要一种方法来衡量事件时间的进展。例如,创建一个小时的时间窗口时,内部的算子需要在事件时间超过一小时后得到通知,这样算子就可以发布正在进行的窗口。 NeuronEX 中衡量事件时间进展的机制是水印。水印作为数据流的一部分,带有一个时间戳 t 。一个水印( t )声明事件时间在该数据流中已经达到了时间 t ,意味着该数据流中不应该再有时间戳 t' <= t 的元素(即时间戳大于或等于水印的事件)。在 NeuronEX 中,水印是在规则层面上的,这意味着当从多个数据流中读取数据时,水印将在所有输入流中流动。
扩展
NeuronEX 允许用户自定义扩展,以支持AI/ML等更多功能。 用户可以通过插件系统编写 Python/Go 扩展插件。此外,用户也可以调用外部已有的 REST 服务作为函数及算法扩展来使用。您可通过扩展页面创建插件或注册外部服务。