Data processing
EMQX Neuron (formerly NeuronEX) has a built-in data processing engine to improve the real-time performance of data processing, reduce edge-cloud communication costs, and provide low-latency data access management and intelligent analysis services for industrial scenarios.
Architecture
The architecture of the EMQX Neuron data processing module is as follows:
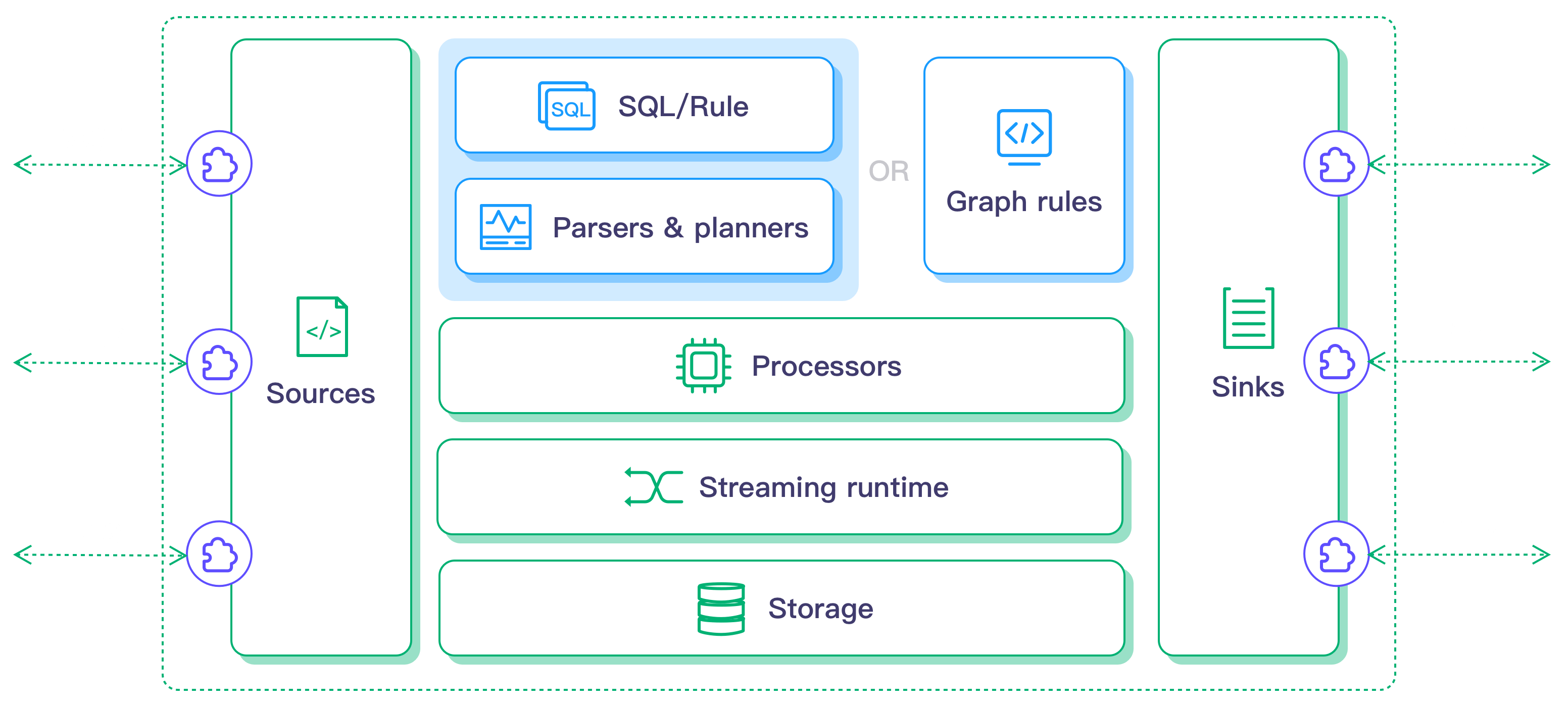
Features and advantages
Low latency
It provides low-latency data processing and analysis, which can transfer data between multiple systems more quickly. Combined with AI/ML algorithms, it can realize intelligent decision-making and control.
Complete data analysis
- Data extraction, transformation and filtering
- Data sorting, grouping, aggregation, and connection
- 160+ various functions, covering mathematical operations, string processing, aggregation operations, hash operations, etc.
- 4 types of time windows, and counting windows
AI/ML integration
Custom functions, AI/ML algorithms, etc. can be accessed through Python or Go extensions to achieve expansion in the three aspects of Source, Function, and Sink.
- Source: allows users to access more data sources for data analysis
- Function: Allows users to add custom functions for data analysis (for example, AI/ML function calls)
- Sink: allows users to send analysis results to different extension systems
Multi-source data access integration
It has the ability to flexibly acquire various types of data and can support:
MES, WMS, ERP system integration
Database integration
Enterprise Service Bus (ESB) integration
File data collection
Video stream analysis
Core conception
Source
Source defines the connection to the external system to load data. In the rules, according to the data usage logic, the data source can be used as Stream or Table.
Stream: Stream is the main operation mode of data source access in EMQX Neuron. Users can define how to connect to external resources by selecting the data source type and configuration parameters. Whenever data flows into the data stream, calculations in the rules will be triggered.
Table: Table is used to represent the current status of the stream. It can be thought of as a snapshot of a stream where you can batch process data through a table. By combining stream and table in rules, more data processing functions can be achieved.
Scan Table: In EMQX Neuron save state data in memory like an event-driven stream, loading data events one by one.
Lookup Table: Bind external data (such as data in a SQL database) and query and reference external data when needed.
Decoding of source: Users can define the decoding method by specifying the
formatattribute when creating the source. Currentlyjson,binary,protobufanddelimitedformats are supported. You can also use your own encoding format and define the field ascustom.Source definition and operation: After creating the stream or table of the data source, the system actually only creates a logical definition of the data source rather than the actual data input for physical operation. This logical definition can be used in the
fromclause of SQL for multiple rules. The data flow will not actually run until it is started using the defined rules.
Currently EMQX Neuron has the following built-in data sources:
- Neuron: Read data from the EMQX Neuron data collection module.
- MQTT: Read data from the MQTT topic.
- HTTP pull: Pulls data from the HTTP server.
- HTTP push: Receive HTTP client messages through the built-in HTTP Server.
- Memory: Read data from the memory topic to form a rule pipeline.
- SQL: Get data from
sqlserver\postgres\mysql\sqlite3\oracledatabase. - File: Read data from a file.
- Video: Obtain data from the video stream.
- Simulator: built-in simulation data source for simulating data and debugging.
- Redis: Obtain data from Redis.
- CAN: Read data from CAN bus.
- Kafka: Read data from Kafka.
- WebSocket: Read data from WebSocket.
Rule
Rules represent a data flow processing process, defining input from data sources, various processing logic, and then outputting data to actions (Sink).
Rule Lifecycle: Once started, a rule will run continuously and will only stop when the user explicitly sends a stop command. Rules may stop abnormally due to errors or the EMQX Neuron instance exiting.
Relationship between multiple rules: The rules are separated at run time, and an error in one rule does not affect other rules. All rules share the same hardware resources, and each rule can specify an operator buffer to limit the processing speed and avoid occupying all resources.
Rule Pipeline: Multiple rules can form a processing pipeline by specifying
Memory Source/Sink. For example, the first rule saves the results in memory sink, and other rules subscribe to topics in their memory sources to get data. In addition tomemory Source/Sink, users can also useMQTT Source/Sinkto connect rules.SQL Statement: The EMQX Neuron data processing module provides a SQL-like query language for performing transformations and calculations on data streams. SQL language support in rules includes data definition language (DDL), data manipulation language (DML), and query language. SQL support in EMQX Neuron is a subset of ANSI SQL, with some custom extensions.
Rule Test: When creating rules, rule test allows you to view the output results of rules after SQL processing in real-time, ensuring that SQL syntax, built-in functions, and data templates meet the expected output results.
Sink
Action Sink: Action Sink is used to write data to external systems. A rule can have multiple actions, and different actions can be of the same action type.
Data Template: After EMQX Neuron performs data analysis and processing through rules, the data template performs "secondary processing" of the rule processing results, and can use various sinks to system. The data template is an optional configuration item. If the data template is not configured, the rule processing results will be output directly to the Sink.
Action type
- MQTT sink: Output to external MQTT service.
- Neuron sink: Output to EMQX Neuron data collection module.
- Rest sink: Output to external HTTP server.
- Memory sink: Output to the memory (Memory) topic to form a rule pipeline.
- Log sink: Write logs, usually only used for debugging.
- SQL sink: Write to SQL database.
- InfluxDB V1 sink: Write to Influx DB
v1.x. - InfluxDB V2 sink: Write to Influx DB
v2.x. - File sink: Write to file.
- Nop sink: No output, used for performance testing.
- Kafka sink: Output to Kafka.
- Image sink: Output to image file.
Streaming
Streaming data is a growing, infinite data set, and stream processing is the processing of streaming data. Stream processing has the characteristics of low latency and near real-time. It can process data after it is generated and obtain results with extremely low latency. Therefore, stream processing can be used in real-time analysis, real-time calculation, real-time prediction and other scenarios.
Stateful Stream Processing: Stateful stream processing is a subset of stream processing in which computations maintain context state. Examples of stateful stream processing include:
- Aggregation Events when calculating a sum, count or average.
- Detect changes in events.
- Search for a pattern in a series of events.
Window: The window provides a mechanism to divide unbounded data into a series of continuous bounded data for calculation. In time windows, both processing time and event time are supported. For all supported window types, see window functions. In EMQX Neuron, the built-in windows include two types:
- Time window: window divided by time
- Counting window: window split by element count
Multiple Source Join: In stream processing, joins are the only way to merge multiple data sources together. It requires a way to align multiple sources and trigger concatenated results. EMQX Neuron supports connection types including LEFT, RIGHT, FULL and CROSS.
Time concept of stream processing: Streaming data is a data sequence that changes over time, where time is an inherent property of the data. In stream processing, time plays an important role in computation. For example, when doing aggregations based on certain time periods (often called windows), it is important to define the concept of time. In stream processing, there are two concepts of time:
- [Event time](./rules.md#Rule options - optional), that is, the time when the event actually occurred. Typically, events should have a timestamp field to indicate when they occurred.
- Processing time, i.e. the time the event was observed in the system.
Event Time and Watermarks: A stream processor that supports event time requires a way to measure event time progress. For example, when creating a one-hour time window, the internal operator needs to be notified when the event time exceeds one hour, so that the operator can publish the ongoing window. The mechanism in EMQX Neuron for measuring event time progression is watermarking. The watermark is part of the data stream and carries a timestamp t. A watermark (t) declares that the event time has reached time t in this data stream, meaning that there should be no more elements in this data stream with timestamp t' <= t (i.e. events with timestamps greater than or equal to the watermark). In EMQX Neuron, watermarking is at the rule level, which means that when reading data from multiple data streams, the watermark will flow across all input streams.
Extension
EMQX Neuron allows users to customize extensions to support AI/ML and other functions. Users can write Python/Go extension plug-ins through the plug-in system. In addition, users can also call existing external REST services to use as functions and algorithm extensions. You can create plug-ins or register external services through the Extension page.
Configuration
The configuration page introduces the Resource configuration and Mode configuration of the EMQX Neuron data analysis module.