SQLを使ったデータクエリ
EMQX Tablesは、データベースからデータをクエリするために完全なSQLをサポートしています。このページでは、monitorテーブルを使ってデータのクエリ方法を説明します。
基本的なクエリ
クエリはSELECT文で表されます。例えば、以下のクエリはmonitorテーブルからすべてのデータを選択します。
SELECT * FROM monitor;クエリ結果は以下のようになります。
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2022-11-03 03:39:57 | 0.1 | 0.4 |
| 127.0.0.1 | 2022-11-03 03:39:58 | 0.5 | 0.2 |
| 127.0.0.2 | 2022-11-03 03:39:58 | 0.2 | 0.3 |
+-----------+---------------------+------+--------+
3 rows in set (0.00 sec)SELECTフィールドリストでは関数も使用可能です。例えば、count()関数を使ってテーブル内の行数を取得できます。
SELECT count(*) FROM monitor;+-----------------+
| COUNT(UInt8(1)) |
+-----------------+
| 3 |
+-----------------+avg()関数は特定フィールドの平均値を返します。
SELECT avg(cpu) FROM monitor;+---------------------+
| AVG(monitor.cpu) |
+---------------------+
| 0.26666666666666666 |
+---------------------+
1 row in set (0.00 sec)関数の結果だけを選択することも可能です。例えば、タイムスタンプから年の何日目かを抽出できます。SQL文中のDOYはday of the yearの略です。
SELECT date_part('DOY', '2021-07-01 00:00:00');出力例:
+----------------------------------------------------+
| date_part(Utf8("DOY"),Utf8("2021-07-01 00:00:00")) |
+----------------------------------------------------+
| 182 |
+----------------------------------------------------+
1 row in set (0.003 sec)日付関数のパラメータと結果はSQLクライアントのタイムゾーンに合わせて処理されます。例えば、クライアントのタイムゾーンが+08:00に設定されている場合、以下の2つのクエリの結果は同じです。
select to_unixtime('2024-01-02 00:00:00');
select to_unixtime('2024-01-02 00:00:00+08:00');詳細はSELECTおよびFunctionsを参照してください。
返される行数の制限
時系列データは通常大量です。帯域幅の節約やクエリ性能向上のために、LIMIT句を使ってSELECT文で返される行数を制限できます。
例えば、以下のクエリは返される行数を10行に制限します。
SELECT * FROM monitor LIMIT 10;データのフィルタリング
WHERE句を使ってSELECT文で返される行をフィルタリングできます。
タグや時間インデックスによるデータのフィルタリングは、時系列シナリオで効率的かつ一般的です。例えば、以下のクエリはタグhostでデータをフィルタリングします。
SELECT * FROM monitor WHERE host='127.0.0.1';以下のクエリは時間インデックスtsでフィルタリングし、2022-11-03 03:39:57以降のデータを返します。
SELECT * FROM monitor WHERE ts > '2022-11-03 03:39:57';また、ANDキーワードを使って複数の条件を組み合わせることも可能です。
SELECT * FROM monitor WHERE host='127.0.0.1' AND ts > '2022-11-03 03:39:57';時間インデックスによるフィルタリング
時間インデックスによるフィルタリングは、時系列データベースの重要な機能です。
Unix時間値を扱う際、データベースはカラムの値の型に基づいて処理します。例えば、monitorテーブルのtsカラムの値の型がTimestampMillisecondの場合、以下のクエリでデータをフィルタリングできます。
Unix時間値1667446797000はTimestampMillisecond型に対応します。
SELECT * FROM monitor WHERE ts > 1667446797000;カラムの値の精度と異なるUnix時間値を扱う場合は、::構文で時間値の型を指定する必要があります。これにより、データベースが正しく型を認識します。
例えば、1667446797は秒単位のタイムスタンプであり、tsカラムのデフォルトのミリ秒単位のタイムスタンプとは異なります。::TimestampSecond構文で秒単位のタイムスタンプであることを指定します。
SELECT * FROM monitor WHERE ts > 1667446797::TimestampSecond;標準のRFC3339やISO8601形式の文字列リテラルを使う場合は、精度が明確なためそのままフィルタ条件に使用可能です。
SELECT * FROM monitor WHERE ts > '2022-07-25 10:32:16.408';フィルタ条件では日時関数も使用可能です。例えば、now()関数とINTERVALキーワードを使って直近5分のデータを取得できます。
SELECT * FROM monitor WHERE ts >= now() - '5 minutes'::INTERVAL;日時関数の詳細はFunctionsを参照してください。
タイムゾーン
タイムゾーン情報を含まない文字列リテラルのタイムスタンプは、SQLクライアントのローカルタイムゾーンに基づいて解釈されます。例えば、クライアントのタイムゾーンが+08:00の場合、以下の2つのクエリは同等です。
SELECT * FROM monitor WHERE ts > '2022-07-25 10:32:16.408';
SELECT * FROM monitor WHERE ts > '2022-07-25 10:32:16.408+08:00';クエリ結果のすべてのタイムスタンプカラム値はクライアントのタイムゾーンに基づいてフォーマットされます。例えば、以下のコードはクライアントのタイムゾーンがUTCと+08:00の場合の同じts値のフォーマット例です。
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2023-12-31 16:00:00 | 0.5 | 0.1 |
+-----------+---------------------+------+--------++-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2024-01-01 00:00:00 | 0.5 | 0.1 |
+-----------+---------------------+------+--------+関数
GreptimeDBはデータ分析のニーズに応じた豊富な組み込み関数と集約機能を提供します。特徴は以下の通りです。
- Apache Datafusionクエリエンジンから継承した包括的な関数セット。Postgresの命名規則と挙動に準拠した日付/時間関数を含みます。
- JSON、ジオロケーションなどの特殊なデータ型に対する論理データ型操作。
- 高度な全文検索マッチング機能。
詳細はFunctions referenceを参照してください。
ORDER BY
返されるデータの順序は保証されません。返されるデータをソートするにはORDER BY句を使用する必要があります。例えば、時系列シナリオでは時間インデックスカラムをソートキーとして使い、時系列順に並べることが一般的です。
-- tsで昇順ソート
SELECT * FROM monitor ORDER BY ts ASC;-- tsで降順ソート
SELECT * FROM monitor ORDER BY ts DESC;CASE式
クエリ内で条件分岐ロジックを実装するにはCASE文を使用できます。例えば、cpuフィールドの値に基づいてCPUの状態を返すクエリは以下の通りです。
SELECT
host,
ts,
CASE
WHEN cpu > 0.5 THEN 'high'
WHEN cpu > 0.3 THEN 'medium'
ELSE 'low'
END AS cpu_status
FROM monitor;結果は以下のようになります。
+-----------+---------------------+------------+
| host | ts | cpu_status |
+-----------+---------------------+------------+
| 127.0.0.1 | 2022-11-03 03:39:57 | low |
| 127.0.0.1 | 2022-11-03 03:39:58 | medium |
| 127.0.0.2 | 2022-11-03 03:39:58 | low |
+-----------+---------------------+------------+
3 rows in set (0.01 sec)詳細はCASEを参照してください。
タグによるデータ集約
GROUP BY句を使って同じ値を持つ行をグループ化し、集約行を作成できます。例えば、hostごとのCPU平均使用率は以下の通りです。
SELECT host, avg(cpu) FROM monitor GROUP BY host;+-----------+------------------+
| host | AVG(monitor.cpu) |
+-----------+------------------+
| 127.0.0.2 | 0.2 |
| 127.0.0.1 | 0.3 |
+-----------+------------------+
2 rows in set (0.00 sec)詳細はGROUP BYを参照してください。
時系列の最新データを取得
各時系列の最新ポイントを取得するには、ClickHouseのようにDISTINCT ONとORDER BYを組み合わせて使用できます。
SELECT DISTINCT ON (host) * FROM monitor ORDER BY host, ts DESC;+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2022-11-03 03:39:58 | 0.5 | 0.2 |
| 127.0.0.2 | 2022-11-03 03:39:58 | 0.2 | 0.3 |
+-----------+---------------------+------+--------+
2 rows in set (0.00 sec)時間ウィンドウによるデータ集約
GreptimeDBはレンジクエリをサポートし、時間ウィンドウごとにデータを集約できます。
例えば、monitorテーブルに以下のデータがあるとします。
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2023-12-13 02:05:41 | 0.5 | 0.2 |
| 127.0.0.1 | 2023-12-13 02:05:46 | NULL | NULL |
| 127.0.0.1 | 2023-12-13 02:05:51 | 0.4 | 0.3 |
| 127.0.0.2 | 2023-12-13 02:05:41 | 0.3 | 0.1 |
| 127.0.0.2 | 2023-12-13 02:05:46 | NULL | NULL |
| 127.0.0.2 | 2023-12-13 02:05:51 | 0.2 | 0.4 |
+-----------+---------------------+------+--------+以下のクエリは10秒の時間範囲でCPU使用率の平均を集計し、5秒ごとに計算します。
SELECT
ts,
host,
avg(cpu) RANGE '10s' FILL LINEAR
FROM monitor
ALIGN '5s' TO '2023-12-01T00:00:00' BY (host) ORDER BY ts ASC;avg(cpu) RANGE '10s' FILL LINEARはレンジ式です。RANGE '10s'は集約の時間範囲が10秒であることを指定し、FILL LINEARは集約時間内にデータがない場合にLINEAR方式で補完することを指定します。ALIGN '5s'はデータ統計のステップ幅を5秒に指定します。TO '2023-12-01T00:00:00'は起点のアライメント時間を指定します。デフォルトはUnix時間の0です。BY (host)は集約キーを指定します。BYキーワードを省略すると、データテーブルの主キーが集約キーとして使われます。ORDER BY ts ASCは結果セットのソート方法を指定します。指定しない場合、結果の順序は保証されません。
レスポンスは以下の通りです。
+---------------------+-----------+----------------------------------------+
| ts | host | AVG(monitor.cpu) RANGE 10s FILL LINEAR |
+---------------------+-----------+----------------------------------------+
| 2023-12-13 02:05:35 | 127.0.0.1 | 0.5 |
| 2023-12-13 02:05:40 | 127.0.0.1 | 0.5 |
| 2023-12-13 02:05:45 | 127.0.0.1 | 0.4 |
| 2023-12-13 02:05:50 | 127.0.0.1 | 0.4 |
| 2023-12-13 02:05:35 | 127.0.0.2 | 0.3 |
| 2023-12-13 02:05:40 | 127.0.0.2 | 0.3 |
| 2023-12-13 02:05:45 | 127.0.0.2 | 0.2 |
| 2023-12-13 02:05:50 | 127.0.0.2 | 0.2 |
+---------------------+-----------+----------------------------------------+時間範囲ウィンドウ
起点の時間範囲ウィンドウは時系列上で前後にステップし、すべての時間範囲ウィンドウを生成します。上記の例では、起点アライメント時間が2023-12-01T00:00:00に設定されており、これは起点時間ウィンドウの終了時間でもあります。
RANGEオプションは起点アライメント時間とともに、origin alignment timestampからorigin alignment timestamp + rangeまでの起点時間範囲ウィンドウを定義します。
ALIGNオプションはクエリの解像度ステップを定義します。起点時間ウィンドウから他の時間ウィンドウへの計算ステップを決定します。例えば、起点アライメント時間が2023-12-01T00:00:00でALIGN '5s'の場合、アライメント時間は2023-11-30T23:59:55、2023-12-01T00:00:00、2023-12-01T00:00:05、2023-12-01T00:00:10…と続きます。
これらの時間ウィンドウは左閉右開区間であり、条件[alignment timestamp, alignment timestamp + range)を満たします。
以下の画像は時間範囲ウィンドウの理解を助けます。
クエリ解像度が時間範囲ウィンドウより大きい場合、メトリクスデータは1つの時間範囲ウィンドウのみで計算されます。
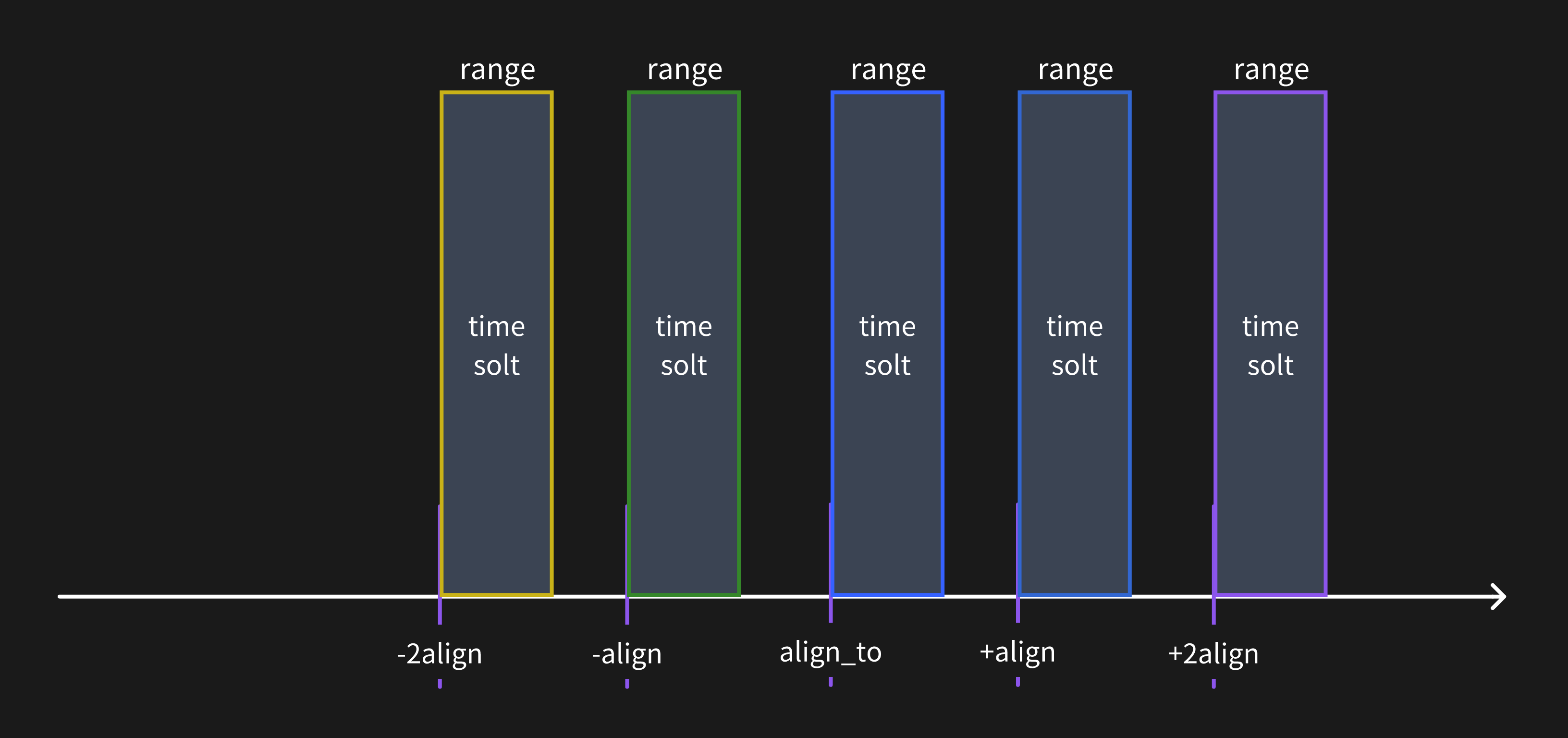
クエリ解像度が時間範囲ウィンドウより小さい場合、メトリクスデータは複数の時間範囲ウィンドウで計算されます。
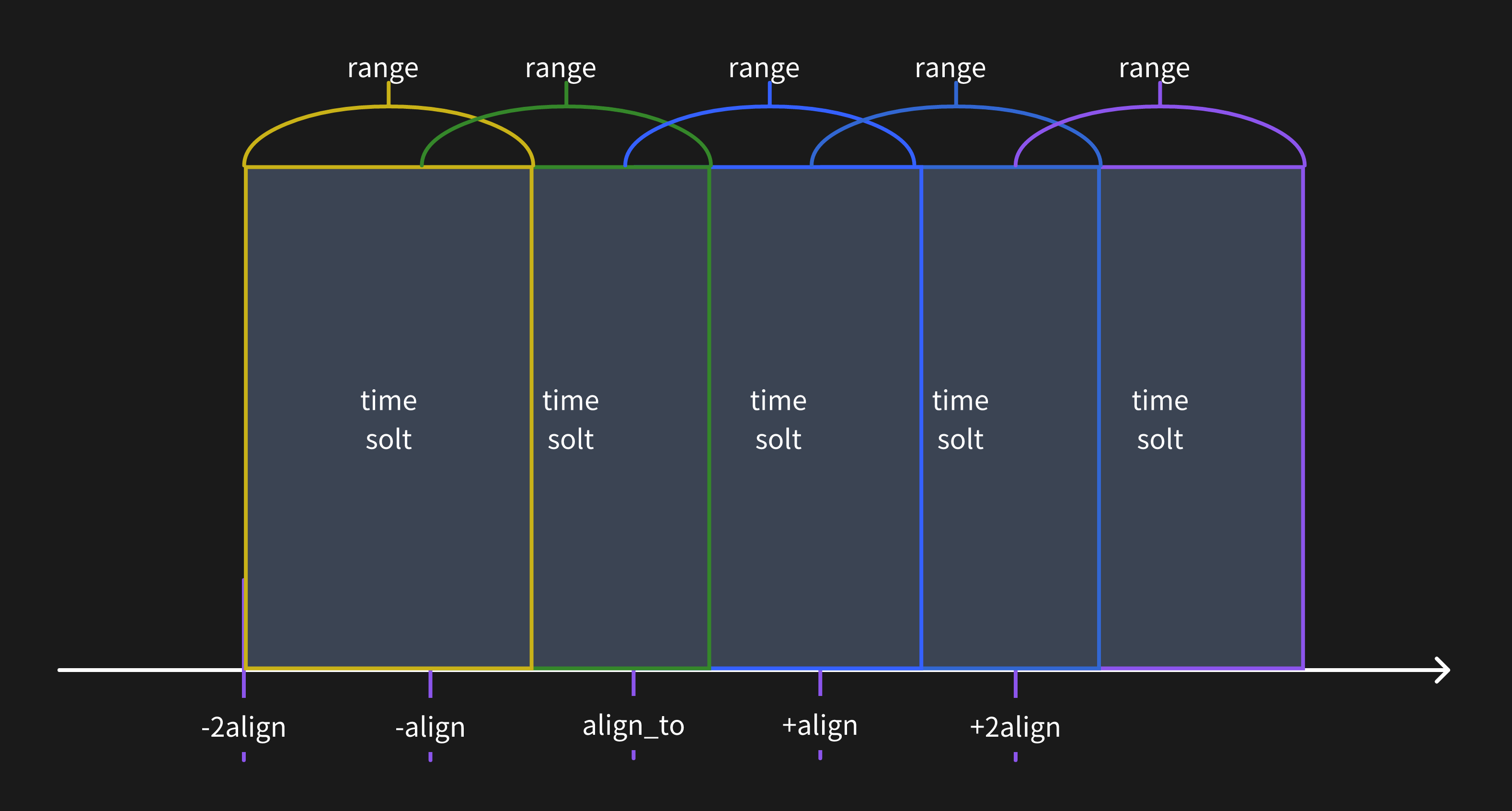
特定のタイムスタンプにアライメント
アライメント時間はデフォルトで現在のSQLクライアントセッションのタイムゾーンに基づきます。起点アライメント時間は任意のタイムスタンプに変更可能です。例えば、NOWを使って現在時刻にアライメントする場合:
SELECT
ts,
host,
avg(cpu) RANGE '1w'
FROM monitor
ALIGN '1d' TO NOW BY (host);または、ISO 8601形式のタイムスタンプを使って指定時刻にアライメントする場合:
SELECT
ts,
host,
avg(cpu) RANGE '1w'
FROM monitor
ALIGN '1d' TO '2023-12-01T00:00:00+08:00' BY (host);NULL値の補完
FILLオプションはデータのNULL値を補完するために使用します。上記の例ではLINEAR方式で補完しています。他にもPREVや定数値Xなどの方法がサポートされています。詳細はFILL OPTIONを参照してください。
構文
詳細はRange Queryを参照してください。
テーブル名の制約
テーブル名に特殊文字や大文字が含まれる場合は、テーブル名をバッククォートで囲む必要があります。詳細はテーブル作成ドキュメントのTable name constraintsを参照してください。