EMQX AI
With the rapid advancement of large language models (LLMs), AI is reshaping industries at an unprecedented pace, and the Internet of Things (IoT) is undergoing a fundamental transformation. Traditional smart hardware was built around fixed functions and operated mainly as passive executors. Today, devices are evolving into intelligent agents with integrated capabilities for perception, understanding, interaction, and action, enabling autonomy and context-aware decision-making. This evolution is driving disruptive upgrades across many application domains.
In emotional companionship, simple electronic toys are becoming intelligent partners capable of emotion recognition, contextual understanding, and empathetic interaction. In smart homes, isolated devices are being replaced by coordinated, whole-home ecosystems controlled through natural language. In robotics, embodied intelligent systems, ranging from service and industrial robots to humanoid robots, require real-time perception, intent understanding, and immediate response. In the automotive sector, intelligent vehicles are emerging as mobile intelligent spaces, where in-vehicle AI assistants manage complex traffic scenarios and enhance driving experiences through continuous, natural voice interaction.

Core of AI Hardware: Real-Time, Accurate, and Context-Rich Perception with Multimodal Interaction
Although large models possess powerful reasoning and generation capabilities, their performance is fundamentally constrained by the quality of the context they receive. When a system fails to accurately understand the current situation, environmental changes, or the user’s true intent, the model may hallucinate or produce irrelevant responses. Humans behave similarly—limited information leads to flawed judgments, while complete context enables accurate decisions. For intelligent hardware, enabling AI to understand the real world is critical to improving interaction stability and trustworthiness. A reliable AI agent must therefore possess the following three core capabilities.
Multi-Source Data: Enabling AI to Understand the Real World
Data from diverse sources collectively form the AI’s world model:
- Environmental data: Physical signals such as temperature, humidity, brightness, and gravity provide real-time state awareness.
- Cloud-based knowledge: Maps, weather, traffic conditions, charging station availability, and other services extend the device’s global awareness.
- Third-party context: Content services and knowledge bases enable the device to handle more complex questions and user needs.
The richer the data sources, the more precisely the system can determine what is happening now and what the user truly needs.
Real-Time Event Awareness: Understanding Changes at the Millisecond Level
Events act as anchors for contextual understanding and are the key triggers that drive LLMs and VLMs:
- Environmental changes: For example, a sudden change in room brightness.
- State changes: Such as a toy unexpectedly tipping over.
- Special scenarios: For instance, abnormal rear-seat pressure sensor readings after a car has been locked.
The ability to capture events at millisecond-level latency directly determines how fast and how accurately the system can respond intelligently.
Multimedia Interaction: Enabling Natural Human–Machine Communication
Multimedia interaction represents a fundamental leap from traditional “voice assistants” to truly immersive intelligent experiences:
- Voice: Emotional expression, natural prosody, and multilingual support.
- Video: Facial expression recognition, scene understanding, and real-time visual feedback.
- Control capabilities: Combining voice and visual understanding to drive more intelligent, context-aware scenarios.
Six Essential Elements for Building Intelligent Hardware
From both input and output perspectives, we define six essential elements required to build qualified intelligent hardware.
Input Capabilities
- Perception: The agent can perceive the physical world through various sensors: temperature sensors for environmental conditions, positioning systems for location awareness, and accelerometers for motion and posture detection.
- Hearing: Microphones capture ambient sounds and user speech. With noise suppression and echo cancellation, combined with multilingual speech recognition, the device can truly “hear” natural human language.
- Vision: Cameras collect visual information to enable image recognition, object detection, face recognition, and gesture recognition, allowing the device to “see” and understand its surroundings and user behavior.
Output Capabilities
- Understanding: By integrating LLM and VLM models, the device achieves semantic understanding, emotion recognition, and contextual memory, enabling accurate intent comprehension and coherent multi-turn conversations.
- Speech: High-quality speakers deliver synthesized speech with multiple voices, emotional expressiveness, and context-aware intonation, allowing natural and fluent communication with users.
- Action: Through the MCP protocol, the device controls its functions, such as volume adjustment, camera activation, and multi-device coordination, executing user commands and producing tangible actions.
An Intelligent IoT Architecture Centered on EMQX and RTC Services
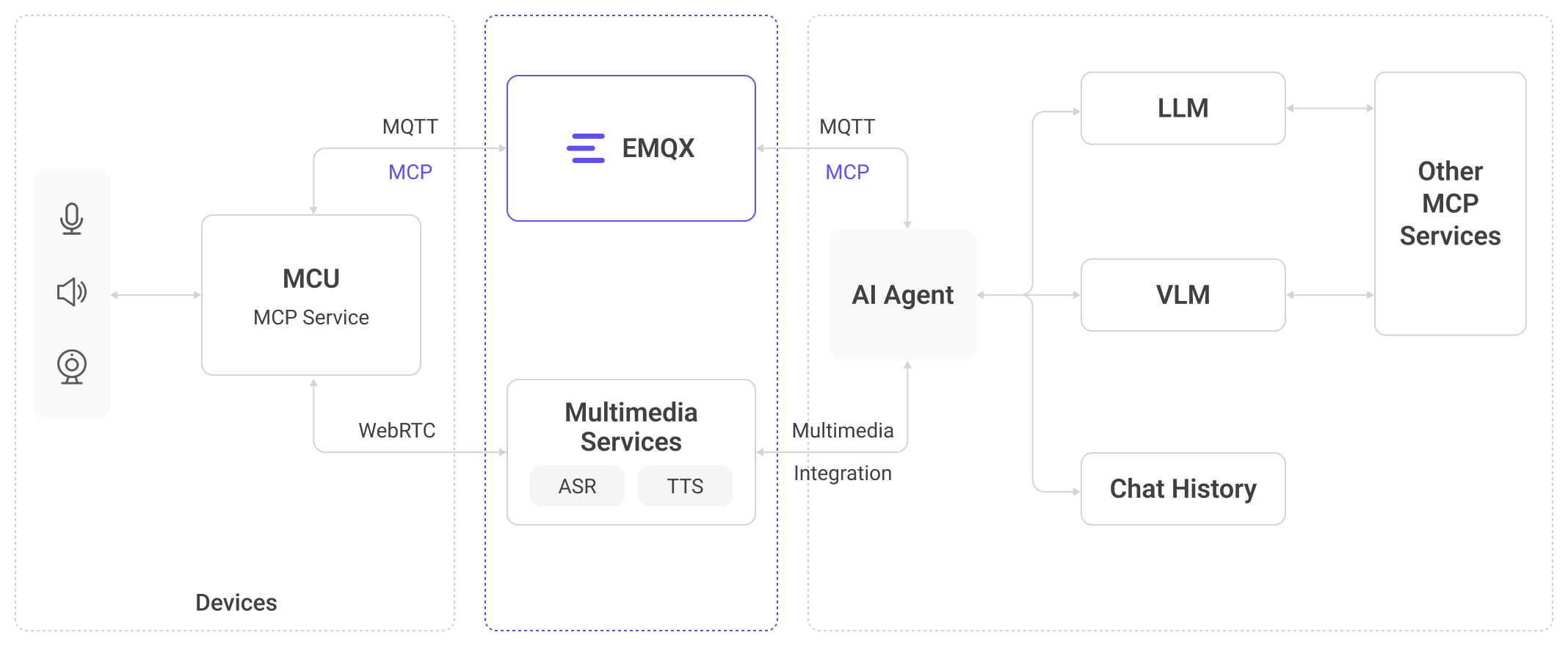
The EMQX end-to-end solution adopts a layered architecture that integrates the device layer, communication layer, processing layer, and application layer into a cohesive system. From sensor data collection and edge processing, to real-time communication (MQTT + WebRTC), and onward to cloud-based large models, it forms a closed-loop chain of “Perception -> Understanding -> Action.” This architecture is suitable for both lightweight devices and complex scenarios such as robotics and in-vehicle systems.
Perception: EMQX as the Provider of Real-Time Context for AI World Models
Perception is the foundation of all intelligent behavior. For humans, most input comes from vision, hearing, and touch, while spoken language accounts for only 6–10% of daily activity. Similarly, an AI agent without real-time world perception is merely an algorithm, not an entity operating in the physical world.
EMQX provides a comprehensive real-time context infrastructure for devices:
- Millisecond-level data pipelines: End-to-end message forwarding from devices to the cloud occurs with millisecond latency, ensuring immediate event processing.
- Full-spectrum SDKs: Unified access from low-power MCUs to Linux-based devices simplifies sensor integration.
- Massive device management: Supports large-scale concurrent connections, message processing, and state tracking, suitable for scenarios ranging from toys to automotive systems.
Further Reading
Building Perception-to-Control Feedback with EMQX
Hearing, Seeing, and Speaking: Audio and Video Stream Access and Processing
WebRTC is the core technology for real-time audio and video interaction. Its low latency and high compatibility make it the preferred solution for multimedia interaction in intelligent hardware.
- Voice input: Enables devices to truly “understand” users. High-quality microphones combined with noise reduction and echo cancellation maintain speech clarity in complex environments. Real-time ASR converts speech to text with multilingual support, forming the basis for semantic understanding.
- Visual input: Provides devices with “eyes.” High-definition cameras combined with object recognition, face recognition, and action understanding allow devices to perceive user states and actions. Gesture interaction enables touch-free, more natural operation.
- Voice output: Makes communication more natural. Modern TTS supports multiple voices and emotional synthesis, automatically adjusting tone and rhythm to context, making machine responses more human-like and engaging.
Further Reading
Building Audio and Video Access with Volcano Engine RTC
Understanding: Integrating LLMs and VLMs
LLMs handle language understanding and generation, while VLMs integrate vision and language. Together, they enable devices not only to “hear and see,” but to truly understand. Compared to traditional rule-based engines, modern large models offer powerful reasoning, memory, and generalization capabilities, making them suitable for highly complex and open-ended interaction scenarios.
Further Reading:
Action: MCP Device Control — The Bridge Between AI and Devices

The Model Context Protocol (MCP) enables AI to invoke device capabilities in a natural, standardized, and dynamic manner.
- MCP Server: Deployed on the device side, responsible for registering device capabilities such as camera control, volume adjustment, and mechanical motion commands.
- MCP Client: Runs in the cloud or at the edge, translating AI decisions into executable device control commands.
- MCP Hosts: Embedded in AI applications, responsible for converting user intent into tool invocations and enabling bidirectional collaboration with devices.
Through MCP, AI gains the ability to act, while devices gain a unified control interface—making multi-device coordination and complex scenario control achievable.
Further Reading
Coordination: A2A over MQTT — Agent-to-Agent Collaboration
As intelligent hardware and AI agents proliferate, individual agents increasingly need to delegate tasks to, and collaborate with, other agents. The Agent-to-Agent (A2A) protocol defines how agents discover each other, exchange task requests, and stream results, forming a multi-agent system that can tackle complex workflows no single agent can handle alone.
EMQX implements A2A over MQTT through its built-in A2A Registry, which records Agent Cards published by agents, tracks their connection state, and routes task requests between them using standard MQTT topics.
Further Reading
Typical Intelligent Agent Interaction Scenarios
- Pure voice interaction: Voice as the sole input; real-time, high-quality interaction can be achieved using WebRTC alone.
- Voice/video-based device control: Devices are operated via microphones or cameras, requiring both WebRTC and MQTT to ensure a stable control pipeline.
- Perception-driven control with multimedia interaction: Devices detect events through sensors, AI makes decisions, and responses are delivered via voice and video, creating immersive intelligent experiences. Like the previous scenario, this requires integration of both WebRTC and MQTT.